 微调LLM
微调LLM





文章目录
OpenAI提供了许多可直接使用的GPT模型。尽管这些模型在各种任务上表现出色,但针对特定任务或上下文对这些模型进行微调,可以进一步提高它们的性能。
一. 开始微调
假设你想为公司创建一个电子邮件自动回复生成器。由于你的公司所在的行业使用专有词汇,因此你希望生成器给出的电子邮件回复保持一定的写作风格。要做到这一点,有两种策略:要么使用之前介绍的提示工程技巧来强制模型输出你想要的文本,要么对现有模型进行微调。
本文对微调进行讨论。
微调的基本逻辑
- 收集大量数据:对于这个例子,你需要收集大量电子邮件,其中包含关于特定业务领域的数据、客户咨询及针对这些咨询的回复。然后,你可以使用这些数据微调现有模型,以使模型学习公司所用的语言模式和词汇。
- 微调后的新模型:微调后的模型本质上是
基于OpenAI提供的原始模型构建的新模型,其中模型的内部权重被调整,以适应特定问题,从而能够在相关任务上提高准确性。
通过对现有模型进行微调,你可以创建一个专门针对特定业务所用语言模式和词汇的电子邮件自动回复生成器。
下图展示了微调过程,也就是使用特定领域的数据集来更新现有GPT模型的内部权重。微调的目标是使新模型能够在特定领域中做出比原始GPT模型更好的预测。
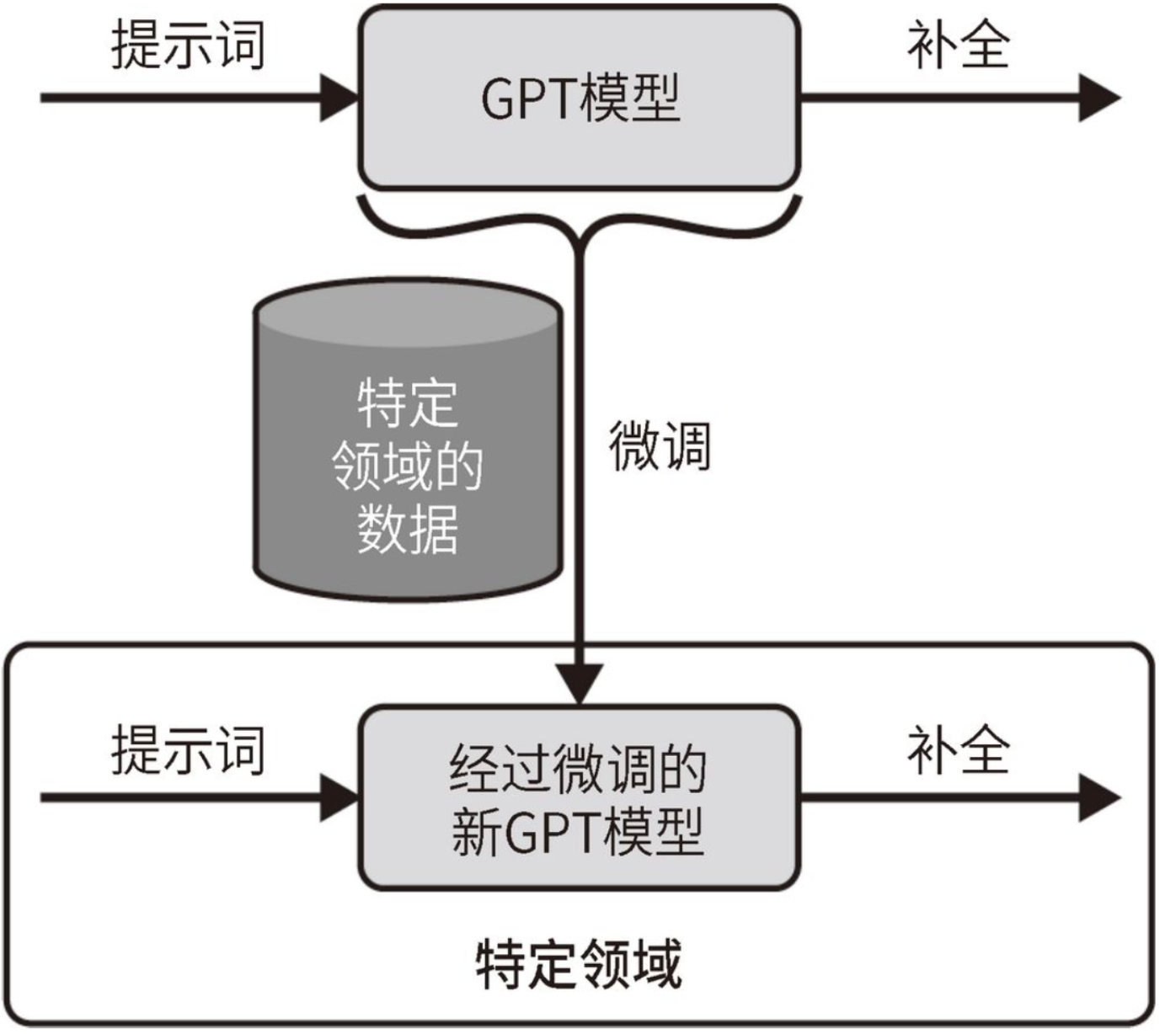
需要注意的是:新模型仍然在OpenAI服务器上
即使你使用自己的数据对LLM进行了微调,
新模型也仍然保存在OpenAI的服务器上。你需要通过OpenAI API与新模型进行交互,而不是在本地使用它。
1. 选择合适的基础模型
在微调时,必须使用基础模型,而不能使用InstructGPT系列中的模型。
目前,微调仅适用于davinci、curie、babbage和ada这几个基础模型。这些模型都在准确性和所需资源之间做出了权衡。
开发人员可以为应用程序选择最合适的模型:
- 较小的模型(ada和babbage)可能在简单任务或资源有限的应用程序中更快且更具成本效益
- 较大的模型(curie和davinci)则提供了更强的语言处理和生成能力,从而适用于需要更高准确性的复杂任务。
微调后的专有能力
- 上述模型不属于InstructGPT系列,它们没有经过RLHF阶段。
- 通过微调这些
基础模型,比如根据自定义数据集调整它们的内部权重,你可以针对特定的任务或领域定制模型。- 虽然没有InstructGPT系列的处理能力和推理能力,但是它们提供了强大的基础,让你可以利用其预训练的处理能力和生成能力来构建专门的应用程序。
2. 微调和少样本学习
2.1. 对比微调和少样本学习
模型是否进行了更新
- 微调是指针对特定任务在一组数据上
重新训练现有模型,以提高模型的性能并使其回答更准确。在微调过程中,模型的内部参数得到更新。- 少样本学习则是通过提示词向模型提供
有限数量的好例子,以指导模型根据这些例子给出目标结果。在少样本学习过程中,模型的内部参数不会被修改。
都可以用来增强GPT模型
- 微调可以帮助我们得到
高度专业化的模型,更准确地为特定任务提供与上下文相关的结果。这使得微调非常适合有大量数据可用的场景。这种定制化确保模型生成的内容更符合目标领域的特定语言模式、词汇和语气。- 少样本学习是一种更灵活的方法,其数据使用率也更高,因为它不需要重新训练模型。当只有有限的示例可用或需要快速适应不同任务时,这种技巧非常有益。
2.2. 微调需要的数据量
微调通常需要用到大量数据。可用示例的缺乏往往限制了我们使用这种技巧。
- 简单任务:为了了解微调所需的数据量,可以假设对于相对简单的任务或仅需稍微调整的模型,通过几百个提示词示例才能获得相应的目标结果。当预训练的GPT模型在任务上表现良好但需要微调以更好地与目标领域对齐时,这种方法是有效的。
- 复杂任务:对于更复杂的任务或需要更多定制化的应用场景,模型可能需要使用成千上万个示例进行训练。前述的电子邮件自动回复生成器正是这样一个应用场景。
- 专业性强的任务:针对非常专业的任务微调模型,可能需要数十万甚至数百万个示例。这种微调规模可以显著地提高模型的性能,并使模型更好地适应特定领域。
ing
迁移学习是指将从一个领域学到的知识应用于不同但相关的领域。正因为如此,你有时可能会听到人们在谈论微调时提到迁移学习。
二. 使用OpenAI API进行微调
本节使用OpenAI API来微调LLM。我们将学习如何准备数据、上传数据,并使用OpenAI API创建一个经过微调的模型。
1. 数据生成
1.1. JSONL的数据格式
更新LLM需要提供一个包含示例的数据集。该数据集是一个JSONL文件,其中每一行对应一个<提示词:补全文本>对,如下示例:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











