








 超级会员免费看
超级会员免费看

 本文深入分析了Spark Streaming通过Direct Approach消费Kafka数据的方式,对比了Receiver-based Approach,指出Direct Approach避免了内存缓冲问题,实现了数据分布式处理,并提供了更好的容错性和性能。同时讨论了Direct Approach的限速机制及其配置参数。
本文深入分析了Spark Streaming通过Direct Approach消费Kafka数据的方式,对比了Receiver-based Approach,指出Direct Approach避免了内存缓冲问题,实现了数据分布式处理,并提供了更好的容错性和性能。同时讨论了Direct Approach的限速机制及其配置参数。
原文链接:https://www.jianshu.com/p/b4af851286e5
前言
这个算是Spark Streaming 接收数据相关的第三篇文章了。 前面两篇是:
Spark Streaming 接受数据的方式有两种:
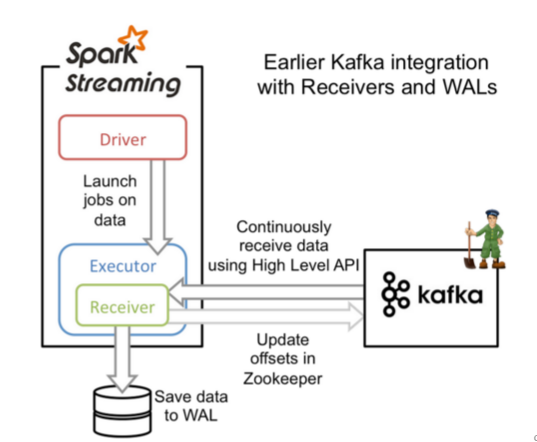
- Receiver-based Approach:offset存储在zookeeper,由Receiver维护,Spark获取数据存入executor中,调用Kafka高阶API
- Direct Approach (No Receivers):offset存储在zookeeper,由Spark维护,且可以从每个分区读取数据,调用Kafka低阶API
上面提到的两篇文章讲的是 Receiver-based Approach 。 而这篇文章则重点会分析Direct Approach (No Receivers) 。
Receiver-based Approach
Direct Approach (No Receivers)
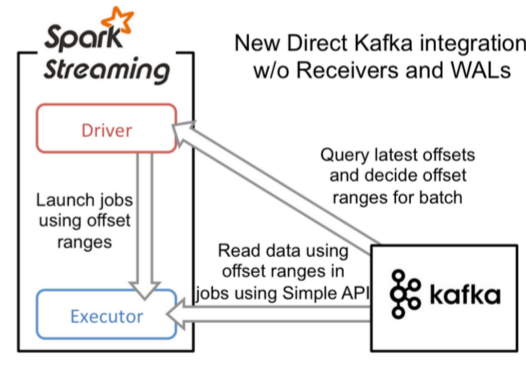
个人认为,DirectApproach 更符合Spark的思维。我们知道,RDD的概念是一个不变的,分区的数据集合。我们将kafka数据源包裹成了一个KafkaRDD,RDD里的partition 对应的数据源为kafka的partition。唯一的区别是数据在Kafka里而不是事先被放到Spark内存里。其实包括FileInputStream里也是把每个文件映射成一个RDD,比较好奇,为什么一开始会有Receiver-based Approach,额外添加了Receiver这么一个概念。
DirectKafkaInputDStream
Spark Streaming通过Direct Approach接收数据的入口自然是KafkaUtils.createDirectStream 了。在调用该方法时,会先创建
val kc = new KafkaCluster(kafkaParams)
KafkaCluster 这个类是真实负责和Kafka 交互的类,该类会获取Kafka的partition信息,接着会创建 DirectKafkaInputDStream,每个DirectKafkaInputDStream对应一个Topic。 此时会获取每个Topic的每个Partition的offset。 如果配置成smallest 则拿到最早的offset,否则拿最近的offset。
每个DirectKafkaInputDStream 也会持有一个KafkaCluster实例。
到了计算周期后,对应的DirectKafkaInputDStream .compute方法会被调用,此时做下面几个操作:
获取对应Kafka Partition的
untilOffset。这样就确定过了需要获取数据的区间,同时也就知道了需要计算多少数据了构建一个KafkaRDD实例。这里我们可以看到,每个计算周期里,
DirectKafkaInputDStream和KafkaRDD是一一对应的将相关的offset信息报给InputInfoTracker
返回该RDD
KafkaRDD 的组成结构
KafkaRDD 包含 N(N=Kafka的partition数目)个 KafkaRDDPartition,每个KafkaRDDPartition 其实只是包含一些信息,譬如topic,offset等,真正如果想要拉数据, 是透过KafkaRDDIterator 来完成,一个KafkaRDDIterator对应一个 KafkaRDDPartition。
整个过程都是延时过程,也就是数据其实都在Kafka存着呢,直到有实际的Action被触发,才会有去kafka主动拉数据。
Direct Approach VS Receiver-based Approach
如果你细心看了之前两篇文章,各种内存折腾,我们会发现Direct Approach (No Receivers),带来了明显的几个好处:
因为按需拉数据,所以不存在缓冲区,就不用担心缓冲区把内存撑爆了。这个在Receiver-based Approach 就比较麻烦,你需要通过
spark.streaming.blockInterval等参数来调整。数据默认就被分布到了多个Executor上。Receiver-based Approach 你需要做特定的处理,才能让 Receiver分不到多个Executor上。
Receiver-based Approach 的方式,一旦你的Batch Processing 被delay了,或者被delay了很多个batch,那估计你的Spark Streaming程序离奔溃也就不远了。 Direct Approach (No Receivers) 则完全不会存在类似问题。就算你delay了很多个batch time,你内存中的数据只有这次处理的。
Direct Approach (No Receivers) 直接维护了 Kafka offset,可以保证数据只有被执行成功了,才会被记录下来,透过
checkpoint机制。这个我会单独一篇文章来讲。如果采用Receiver-based Approach,消费Kafka和数据处理是被分开的,这样就很不好做容错机制,比如系统当掉了。所以你需要开启WAL,但是开启WAL带来一个问题是,数据量很大,对HDFS是个很大的负担,而且也会对实时程序带来比较大延迟。
我原先以为Direct Approach 因为只有在计算的时候才拉取数据,可能会比Receiver-based Approach 的方式慢,但是经过我自己的实际测试,总体性能 Direct Approach会更快些,因为Receiver-based Approach可能会有较大的内存隐患,GC也会影响整体处理速度。
限速
Spark Streaming 接收数据的两种方式都有限速的办法。Receiver-based Approach 的具体参看 Spark Streaming 数据产生与导入相关的内存分析。
而在Direct Approach,则是通过参数 spark.streaming.kafka.maxRatePerPartition 来配置的。这里需要注意的是,这里是对每个Partition进行限速。所以你需要事先知道Kafka有多少个分区,才好评估系统的实际吞吐量,从而设置该值。
另外,spark.streaming.backpressure.enabled 参数在Direct Approach 中也是继续有效的。
总结
根据我的实际经验,目前Direct Approach 稳定性个人感觉比 Receiver-based Approach 更好些。但看源码说该接口处于实验性质。
实现方式参考:
- https://blog.youkuaiyun.com/high2011/article/details/79848882
- https://blog.youkuaiyun.com/ligt0610/article/details/47311771
- https://blog.youkuaiyun.com/wangweislk/article/details/78339910
- http://blog.cloudera.com/blog/2015/03/exactly-once-spark-streaming-from-apache-kafka/
- http://www.aboutyun.com/thread-20427-1-1.html
- https://my.oschina.net/u/1250040/blog/908571


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









