




 超级会员免费看
超级会员免费看
 本文探讨了如何提高Spark并行度,包括通过reduce参数、partitionBy和设置SparkContext.textFile的num参数。并行度受partition、节点数量、CPU核心数等因素影响。深入讲解了File、Block、Split、Task、Partition、RDD等概念及其相互关系,指出InputSplit与Task一对一,Task并发度等于Executor数乘以每个Executor的核数。在数据读取阶段,partition数目基于InputSplit,Map阶段保持不变,Reduce阶段如repartition操作可改变分区数。
本文探讨了如何提高Spark并行度,包括通过reduce参数、partitionBy和设置SparkContext.textFile的num参数。并行度受partition、节点数量、CPU核心数等因素影响。深入讲解了File、Block、Split、Task、Partition、RDD等概念及其相互关系,指出InputSplit与Task一对一,Task并发度等于Executor数乘以每个Executor的核数。在数据读取阶段,partition数目基于InputSplit,Map阶段保持不变,Reduce阶段如repartition操作可改变分区数。
一、问题
1、怎样提高并行度?
几种方式:(1)reduce时,输入参数(int) (2)partitionBy()输入分区数 (3)SparkContext.textFile(path,num)
2、什么情况下需要提高并行度?
(1).partition的个数是split size决定的,spark的底层还是用的hadoop的fileformat,当你制定了一个可以切分的format,他就会按照splitsize去切partition,这个决定了任务会被分成多少份。
(2).节点个数跟cpu的核数决定了你能起多少实例,就是资源池。
(3).如果你partition的数量多,能起实例的资源也多,那自然并发度就多,如果你partition数量少,资源很多,它也不会有很多并发,如果你partition的数量很多,但是资源少,那么并发也不大,他会算完一批再继续起下一批
二、几个概念和关系
Spark中关于并发度涉及的几个概念File,Block,Split,Task,Partition,RDD以及节点数、Executor数、core数目的关系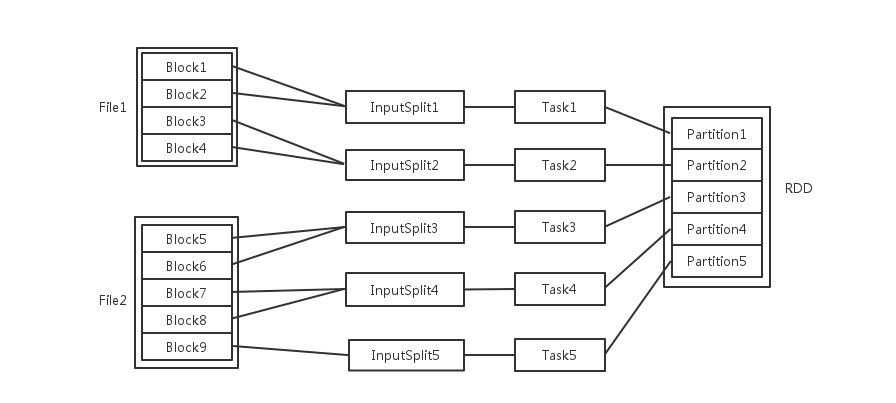
输入可能以多个文件的形式存储在HDFS上,每个File都包含了很多块,称为

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 2596
2596




 到【灌水乐园】发言
到【灌水乐园】发言









