




 超级会员免费看
超级会员免费看
 本文详细介绍了Spark的序列化机制,包括Java serialization和Kryo serialization,推荐使用Kryo以提高速度和紧凑性。还讨论了如何自定义Kryo serialization,并指出其在网络传输中的效率优势。
本文详细介绍了Spark的序列化机制,包括Java serialization和Kryo serialization,推荐使用Kryo以提高速度和紧凑性。还讨论了如何自定义Kryo serialization,并指出其在网络传输中的效率优势。
一、前言
关于序列化和反序列化的定义,在这篇文章中有详细介绍,此处简要说明:
- 序列化:将对象写入到 IO 流中
- 反序列化:从 IO 流中恢复对象
我们也可以借助下图来理解序列化和反序列化的过程。
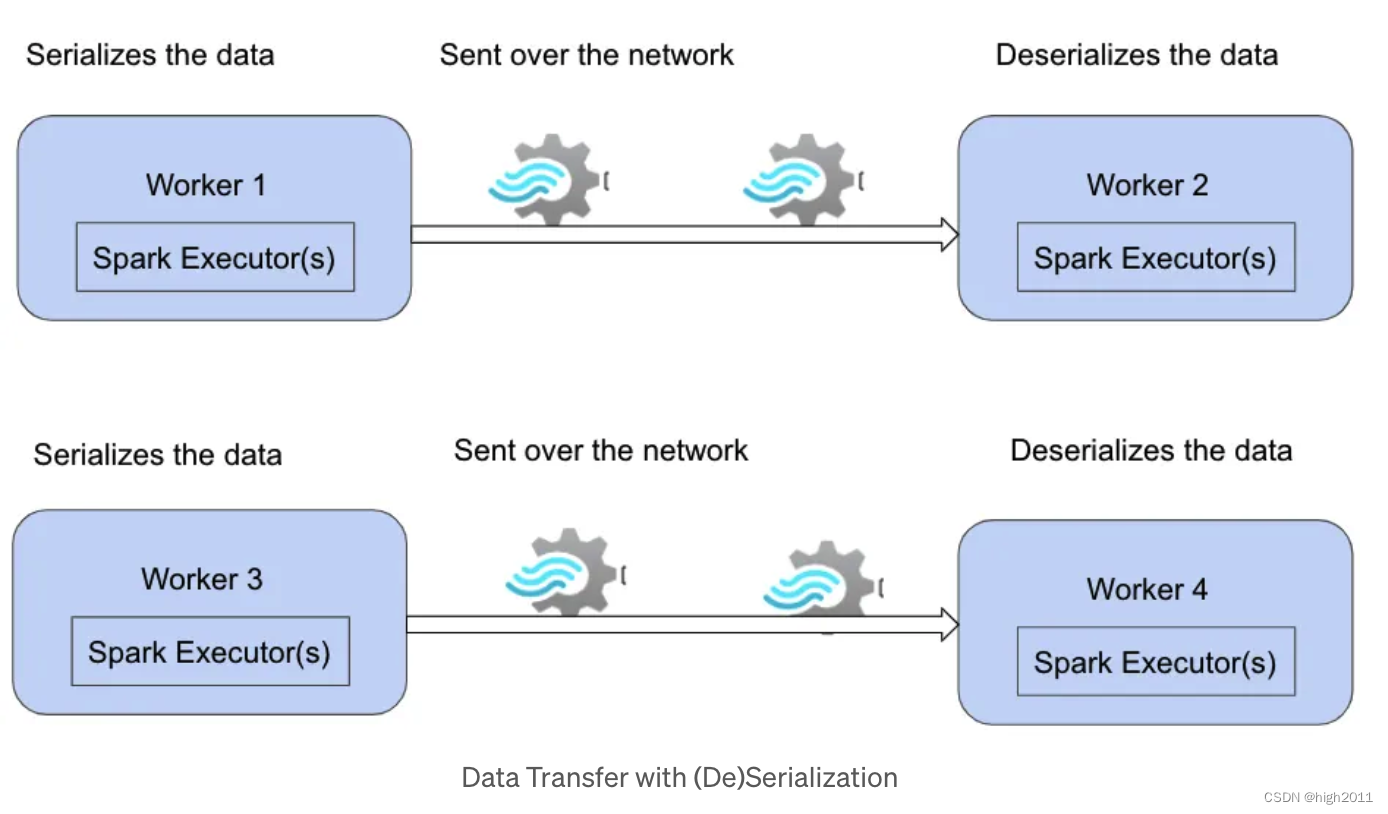
二、Spark 的序列化器
Spark 提供了 2 个序列化库 (Java serialization 和 Kyro serialization),此外用户也可以自定义实现序列化:
- Java serialization (默认):Java 序列化非常灵活,但通常相当缓慢,而且会导致许多类的序列化格式过大。
- Kryo serialization (推荐使用):更快地序列化对象。Kryo 比 Java 序列化要快得多,也更紧凑(通常是 Java 序列化

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











