




处理流程
MapReduce处理数据过程主要分成Map和Reduce两个阶段。首先执行Map阶段,再执行Reduce阶段。Map和Reduce的处理逻辑由用户自定义实现,但要符合MapReduce框架的约定。处理流程如下所示:
- 在正式执行Map前,需要将输入数据进行分片。所谓分片,就是将输入数据切分为大小相等的数据块,每一块作为单个Map Worker的输入被处理,以便于多个Map Worker同时工作。
- 分片完毕后,多个Map Worker便可同时工作。每个Map Worker在读入各自的数据后,进行计算处理,最终输出给Reduce。Map Worker在输出数据时,需要为每一条输出数据指定一个Key,这个Key值决定了这条数据将会被发送给哪一个Reduce Worker。Key值和Reduce Worker是多对一的关系,具有相同Key的数据会被发送给同一个Reduce Worker,单个Reduce Worker有可能会接收到多个Key值的数据。
- 在进入Reduce阶段之前,MapReduce框架会对数据按照Key值排序,使得具有相同Key的数据彼此相邻。如果您指定了合并操作(Combiner),框架会调用Combiner,将具有相同Key的数据进行聚合。Combiner的逻辑可以由您自定义实现。与经典的MapReduce框架协议不同,在MaxCompute中,Combiner的输入、输出的参数必须与Reduce保持一致,这部分的处理通常也叫做洗牌(Shuffle)。
- 接下来进入Reduce阶段。相同Key的数据会到达同一个Reduce Worker。同一个Reduce Worker会接收来自多个Map Worker的数据。每个Reduce Worker会对Key相同的多个数据进行Reduce操作。最后,一个Key的多条数据经过Reduce的作用后,将变成一个值。
- 下文将以WordCount为例,为您介绍MaxCompute MapReduce各个阶段的概念。
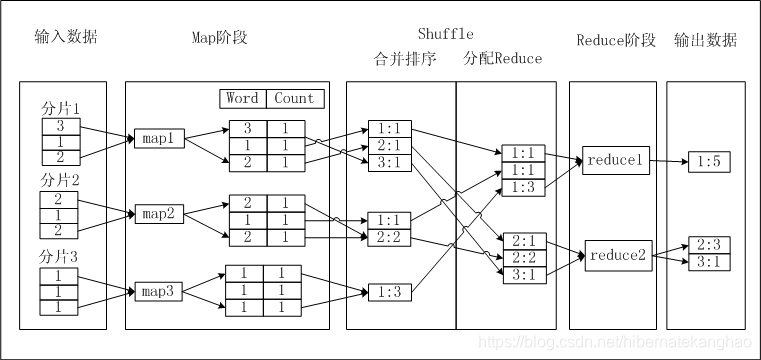
- 假设存在一个文本a.txt,文本内每行是一个数字,您要统计每个数字出现的次数。文本内的数字称为Word,数字出现的次数称为Count。如果MaxCompute MapReduce完成这一功能,需要经历以下流程,如下图所示:
操作步骤:
- 假设存在一个文本a.txt,文本内每行是一个数字,您要统计每个数字出现的次数。文本内的数字称为Word,数字出现的次数称为Count。如果MaxCompute MapReduce完成这一功能,需要经历以下流程,如下图所示:
- 输入数据:对文本进行分片,将每片内的数据作为单个Map Worker的输入。
- Map阶段:Map处理输入,每获取一个数字,将数字的Count 设置为1,并将此<Word, Count>对输出,此时以Word作为输出数据的Key。
- Shuffle>合并排序:在Shuffle阶段前期,首先对每个Map Worker的输出,按照Key值(即Word值)进行排序。排序后进行Combiner操作,即将Key值(Word值)相同的Count累加,构成一个新的<Word, Count>对。此过程被称为合并排序。
- Shuffle>分配Reduce:在Shuffle阶段后期,数据被发送到Reduce端。Reduce Worker收到数据后依赖Key值再次对数据排序。
- Reduce阶段:每个Reduce Worker对数据进行处理时,采用与Combiner相同的逻辑,将Key值(Word 值)相同的Count累加,得到输出结果。
输出结果数据。

















 310
310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









