




目录标题
要分析 K8s Node 节点的系统日志,需结合日志内容、组件配置和常见故障场景,以下是分步分析与解决方案:
一、日志关键错误解析
从截图日志中,核心错误包括两类:
-
Unable to read config path "/etc/kubernetes/manifests": path does not exist- 含义:Kubelet 尝试读取静态 Pod 配置目录,但该路径不存在。
- 背景:
/etc/kubernetes/manifests是 控制平面节点(Master 节点)存放kube-apiserver、kube-controller-manager等静态 Pod 定义的目录。若 Worker 节点 出现此错误,说明 Kubelet 被错误配置为加载控制平面的静态 Pod。
-
Failed to get system container stats for "/system.slice/docker.service": failed to get cgroup- 含义:Kubelet 无法获取 Docker 服务的 cgroup 统计信息,通常因 Kubelet 和 Docker 的 cgroup 驱动不一致 导致。
二、排查与解决步骤
步骤 1:确认节点角色与状态
- 查看节点角色:
kubectl get nodes -o wide- 若为 Worker 节点,理论上不应加载
/etc/kubernetes/manifests中的静态 Pod。
- 若为 Worker 节点,理论上不应加载
- 检查节点事件:
kubectl describe node <node-name>- 关注
Kubelet相关的警告(如未就绪、通信失败等)。
- 关注
步骤 2:分析 Kubelet 配置
Kubelet 的配置可能通过 启动参数(/etc/sysconfig/kubelet)或 配置文件(/var/lib/kubelet/config.yaml)定义,需检查以下项:
-
静态 Pod 路径:
-
检查 Kubelet 是否配置了
--pod-manifest-path=/etc/kubernetes/manifests:cat /etc/sysconfig/kubelet | grep pod-manifest-path cat /var/lib/kubelet/config.yaml | grep staticPodPath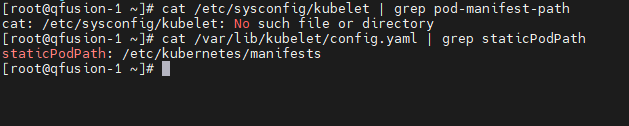
-
若 Worker 节点存在该配置,注释或删除该参数(因为 Worker 节点的控制平面组件由 Apiserver 管理,而非静态 Pod),然后重启 Kubelet:
systemctl restart kubelet
-
-
Cgroup 驱动:
-
查看 Docker 的 cgroup 驱动:
docker info | grep "Cgroup Driver" # 示例输出:Cgroup Driver: cgroupfs -
查看 Kubelet 的 cgroup 驱动:
cat /var/lib/kubelet/config.yaml | grep cgroupDriver # 示例输出:cgroupDriver: systemd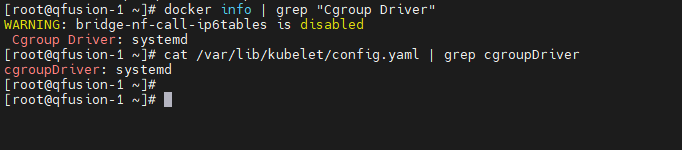
-
若两者不一致(如 Docker 用
cgroupfs,Kubelet 用systemd),需统一驱动:- 方案 1:修改 Docker 驱动为
systemd(推荐,systemd 更稳定):- 编辑
/etc/docker/daemon.json,添加:{ "cgroup-driver": "systemd" } - 重启 Docker 和 Kubelet:
systemctl daemon-reload && systemctl restart docker systemctl restart kubelet
- 编辑
- 方案 2:修改 Kubelet 驱动为
cgroupfs(不推荐,仅临时调试用):
编辑/var/lib/kubelet/config.yaml,将cgroupDriver改为cgroupfs,然后重启 Kubelet。
- 方案 1:修改 Docker 驱动为
-
步骤 3:检查 Docker 服务状态
- 查看 Docker 日志:
journalctl -u docker -n 100 # 检查是否有启动失败、超时等错误 - 验证 Docker 运行状态:
docker ps # 查看容器是否正常运行,若大量重启需排查镜像、资源问题
步骤 4:验证日志错误是否消除
- 重启 Kubelet 和 Docker 后,再次检查 Kubelet 日志:
journalctl -u kubelet -n 100 - 检查节点状态:
kubectl get nodes # 确认节点是否恢复 Ready 状态
三、长期日志管理方案(参考资料延伸)
若需对 K8s 集群日志进行 集中采集、存储和分析,可参考以下方案(基于 EFK 或 Fluentbit + Elasticsearch + Kibana):
-
日志采集:
- 通过 Fluentd/Fluentbit DaemonSet 部署在每个 Node 上,采集路径包括:
- 容器日志:
/var/log/containers/*.log(K8s 自动挂载的容器日志)。 - 系统组件日志:
/var/log/kubelet.log、/var/log/docker.log等。
- 容器日志:
- 配置示例(Fluentd 输入插件):
<source> @type tail path /var/log/containers/*.log pos_file /var/log/fluentd-containers.log.pos tag kubernetes.* read_from_head true <parse> @type json </parse> </source>
- 通过 Fluentd/Fluentbit DaemonSet 部署在每个 Node 上,采集路径包括:
-
日志存储与分析:
- 利用 Elasticsearch 存储日志,通过 Kibana 可视化查询。
- 部署参考:通过 StatefulSet 部署 Elasticsearch 集群,Service 暴露访问端口;Kibana 以 Deployment 部署,关联 Elasticsearch。
总结
当前 Node 日志的核心问题是 配置错误(静态 Pod 路径)和 cgroup 驱动不一致,按上述步骤修复后,若需长期监控,建议部署 EFK 等日志系统。若问题仍存在,需进一步检查:
- 节点资源(CPU、内存是否过载,导致 Kubelet/Docker 无法响应)。
- 网络通信(Node 与 Apiserver、Docker 守护进程的连接是否正常)。

















 1111
1111

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









