



 本文介绍了正则表达式学习网站RegexLearn和在线工具regex101,详细讲解了正则表达式的各种语法、锚点、边界、字符类、量词、分支、标志、组和引用等概念,并提供了练习题帮助读者掌握和应用正则表达式。
本文介绍了正则表达式学习网站RegexLearn和在线工具regex101,详细讲解了正则表达式的各种语法、锚点、边界、字符类、量词、分支、标志、组和引用等概念,并提供了练习题帮助读者掌握和应用正则表达式。
推荐网站
学习
推荐一个正则表达式学习网站RegexLearn,界面简洁明了,可以高亮提示和练习
使用
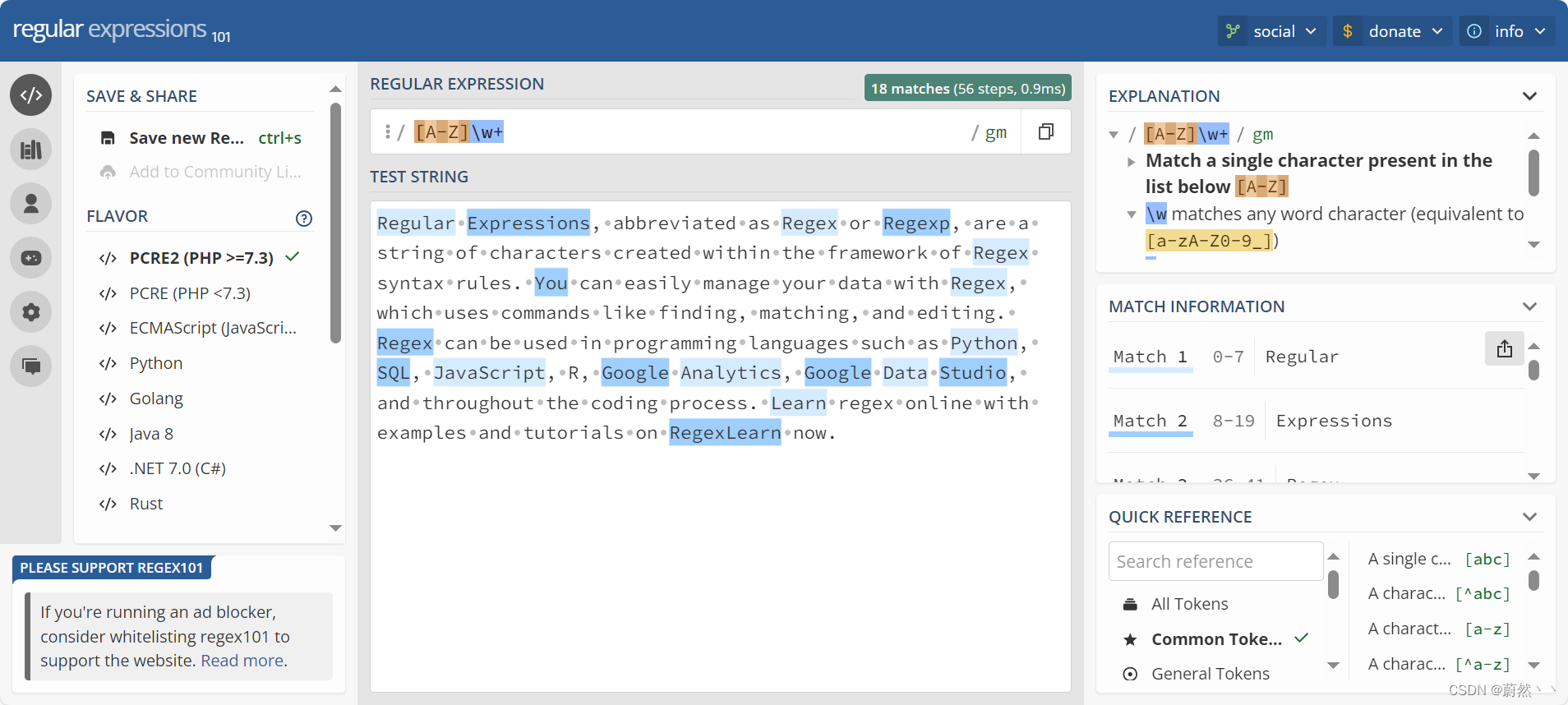
在线使用regex101,右侧可以显示语法介绍和匹配信息,可以导出匹配文本
语法
示例
an answer or a question(这里是待匹配文本,其中加粗部分是被匹配字符)
^\w+(这里写的是正则表达式)
说明
/w+/g,“/“是表达式开始和结束的定界符,在不特殊说明使用标志(全局g,多行m,忽略大小写i)的情况下,下面就隐藏”//g”
锚点
^开头
匹配字符串或行的开头。
an answer or a question
^\w+
这个例子仅说明”^“的用法,其中“\w”表示匹配字母、数字或下划线,”+“表示匹配一个或多个。
$末尾
匹配字符串或行的末尾。
an answer or a question
\w+$
\b边界
匹配单词的开头或末尾,单词边界。
an answer or a question
n\b
\B非边界
匹配不在单词开头或末尾的位置,非单词边界。
an answer or a question
n\B
字符类
[abc]字符集
匹配集合中的任意字符。
bar ber bir bor bur
b[eo]r
[^abc]否定字符集
匹配不在集合中的任意字符。
bar ber bir bor bur
b[^eo]r
[a-z]范围
匹配两个字符之间的任意字符,包括它们本身。
abcdefghijklmnopqrstuvwxyz
[e-i]
.点
匹配除换行符之外的任意字符。
hi012_-!?
.
\w单词
匹配字母、数字或下划线。
hi 012 _-!?
\w
\W非单词
匹配除字母、数字和下划线之外的任意字符。
hi [空格]012[空格]_-!?
\W
\d数字
匹配所有数字。
+1-(444)-222
\d
\D非数字
匹配除数字外的任意字符。
**+1-(444)-**222
\D
\s空白符
匹配所有空白字符。
one**[空格]**two
\s
\S非空白符
匹配除空白字符以外的任意字符。
one two
\S
量词与分支
+一或多
表达式匹配一个或多个。
bp bep beep beeep
/be+p/g
*零或多
表达式匹配零个或多个。
bp bep beep beeep
/be*p/g
{1-3}重复
表达式匹配指定范围的位数。
bp bep beep beeep
/be{1,2}p/g
?可选
使表达式可选。
color, colour
/colou?r/g
|或
类似于“或”。用于匹配多种符合条件的表达式之一。
fat, cat, rat
/(c|r)at/g
零宽断言
(?=)正向先行断言
例如,我们要匹配文本中的小时值。为了只匹配后面有 PM 的数值,我们需要在表达式后面使用正向先行断言 (?=),并在括号内的 = 后面添加 PM
Date: 4 Aug 3PM
\d+(?=PM)
(?!)负向先行断言
例如,我们要在文本中匹配除小时值以外的数字。我们需要在表达式后面使用负向先行断言 (?!),并在括号内的 ! 后面添加 PM,从而只匹配没有 PM 的数值。
Date: 4 Aug 3PM
\d+(?!PM)
(?<=)正向后行断言
例如,我们要匹配文本中的金额数。为了只匹配前面带有 $ 的数字。我们要在表达式前面使用正向后行断言 (?<=),并在括号内的 = 后面添加 $。
Product Code: 1064 Price: $5
(?<=\$)\d+
(?<!)负向后行断言
例如,我们要在文本中匹配除价格外的数字。为了只匹配前面没有 $ 的数字,我们要在表达式前用负向后行断言 (?<!),并在括号内的 ! 后面添加 $。
Product Code: 1064 Price: $5
(?<!\$)\d+
标志
g全局标志
全局标志使表达式选中所有匹配项,如果不启用全局标志,那么表达式只会匹配第一个匹配项。现在,请启用全局标志,以便匹配所有匹配项。
domain.com, test.com, site.com
/\w+\.com/g
m多行标志
正则表达式将所有文本视作一行。但如果我们使用了多行标志,它就会单独处理每一行。这次,我们将根据每一行行末的规律来写出表达式,现在,请启用多行标志来查找所有匹配项。
domain.com
test.com
site.com
/\w+\.com$/gm
i忽略大小写标志
为了使我们编写的表达式不再大小写敏感,我们必须启用 不区分大小写 标志。
DOMAIN.COM
TEST.COM
SITE.COM
/\w+\.com$/gmi
组和引用
()分组
我们可以对一个表达式进行分组,并用这些分组来引用或执行一些规则。为了给表达式分组,我们需要将文本包裹在 () 中。现在,请尝试为下方文本中的 haa 构造分组。
ha-ha,haa-haa
(haa)
引用组
单词 ha 和 haa 分组如下。第一组用 \1 来避免重复书写。这里的 1 表示分组的顺序。请在表达式的末尾键入 \2 以引用第二组。
ha-ha,haa-haa
(ha)-\1,(haa)-\2
(?:)非捕获分组
您可以对表达式进行分组,并确保它不被引用捕获。例如,下面有两个分组,但我们用 \1 引用的第一个组实际上是指向第二个组,因为第一个是未被捕获的分组。
ha-ha,haa-haa
(?:ha)-ha,(haa)-\1
不会再去匹配ha,而是整体作为一个组
贪婪匹配
正则表达式默认执行贪婪匹配。这意味着匹配内容会尽可能长。请看下面的示例,它匹配任何以 r 结尾的字符串,以及前面带有该字符串的文本,但它不会在第一个 r 处停止匹配。
ber beer beeer beeeer
.*r
懒惰匹配
与贪婪匹配不同,懒惰匹配在第一次匹配时停止。下面的例子中,在 * 之后添加 ?,将查找以 r 结尾且前面带有任意字符的第一个匹配项。这意味着本次匹配将会在第一个字母 r 处停止。
ber beer beeer beeeer
.*?r
练习
字符集
写出匹配文本中所有单词的表达式。单词首字母是唯一变化的字符。
beer deer feer
[bdf]eer
大括号-1
用 {} 编写表达式,匹配文本中,位数为 4 的阿拉伯数字。
Release 10/9/2021
[0-9]{4}
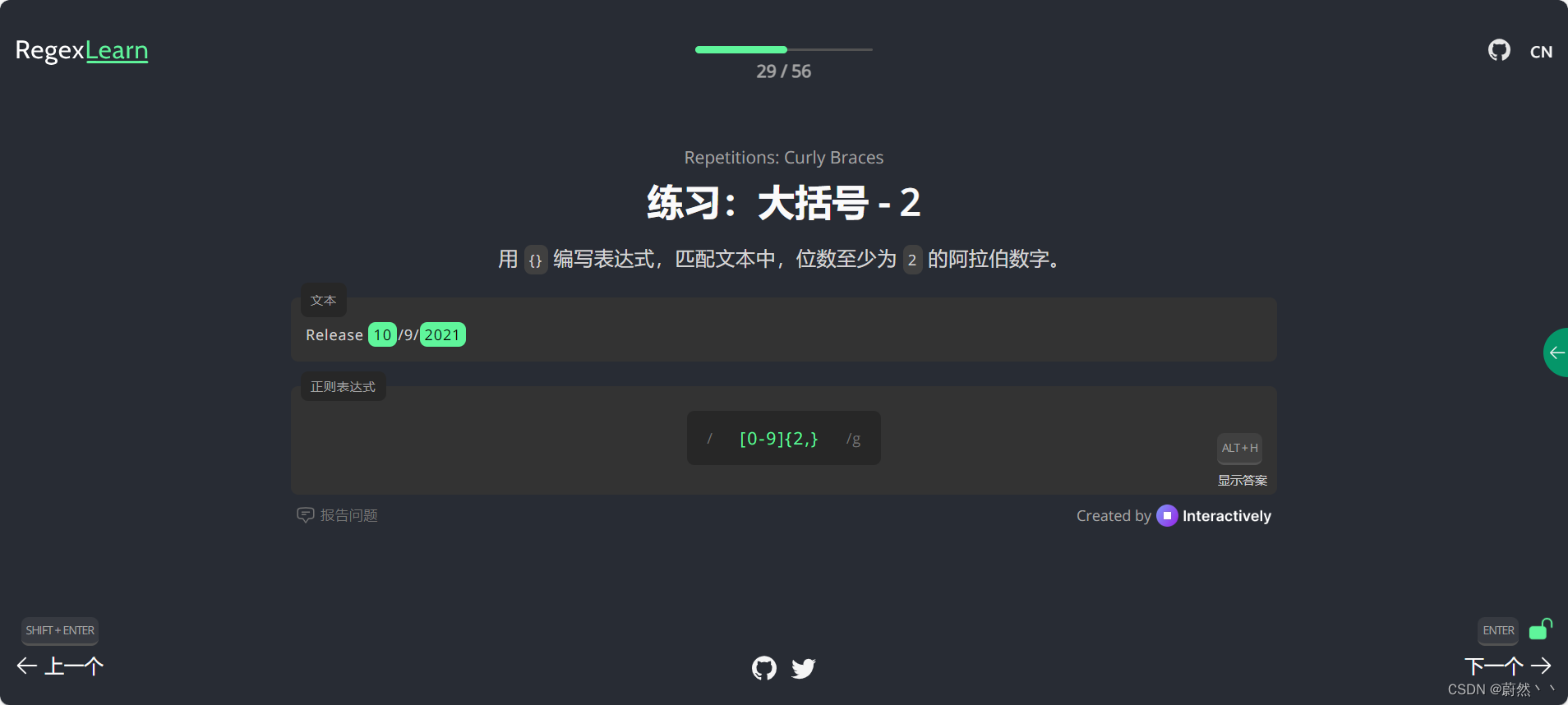
大括号-2
用 {} 编写表达式,匹配文本中,位数至少为 2 的阿拉伯数字。
Release 10/9/2021
[0-9]{2,}
大括号-3
用 {} 编写表达式,匹配文本中,位数为 1 至 4 的阿拉伯数字。
Release 10/9/2021
[0-9]{1,4}

















 7409
7409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









