




 文章介绍了AFM(Attentional Factorization Machines)模型,该模型通过注意力网络学习特征交互的权重,解决了FM模型中所有交互特征权重相同的问题。AFM在回归任务上相对于FM和其它深度学习方法表现出优越性能,并且结构简单,参数少。实验证明AFM能提升模型效果并提供更好的解释性。
文章介绍了AFM(Attentional Factorization Machines)模型,该模型通过注意力网络学习特征交互的权重,解决了FM模型中所有交互特征权重相同的问题。AFM在回归任务上相对于FM和其它深度学习方法表现出优越性能,并且结构简单,参数少。实验证明AFM能提升模型效果并提供更好的解释性。
Attentional Factorization Machines: Learning the Weight of Feature Interactions via Attention Networks
Jun Xiao, Hao Ye, Xiangnan He, Hanwang Zhang, Fei Wu, Tat-Seng Chua
Zhejiang University, National University of Singapore
https://www.ijcai.org/Proceedings/2017/0435.pdf
分解机是一种有监督学习方法,通过融入二阶特征交互对线性回归模型进行增强。虽然这种方法比较有效,但是它将所有特征交互赋予相同的权重,这种操作具有一定局限性,因为并不是所有的特征交互同样有用,或者预测能力也有所差异。比如,无用的特征交互可能会引入噪声,进而模型性能会下降。
这篇文章,通过区别不同特征交互的重要性对FM进行了改进。作者们提出一种新的模型,注意力分解机(AFM),利用神经注意力网络从数据中学习每个特征交互的重要性。
作者们在两个真实数据集上进行了实验,验证了AFM的有效性。结果表明,在回归任务中,AFM相对FM可以提升8.6%,并且优于之前效果比较好的深度学习方法,Wide & Deep,以及DeepCross。这种模型的优势在于结构比较简单,模型参数较少。
关于特征交互,部分现有方法具有一定的缺陷

FM的形式及简介如下

FM的缺陷在于

作者们所提网络结构图示如下
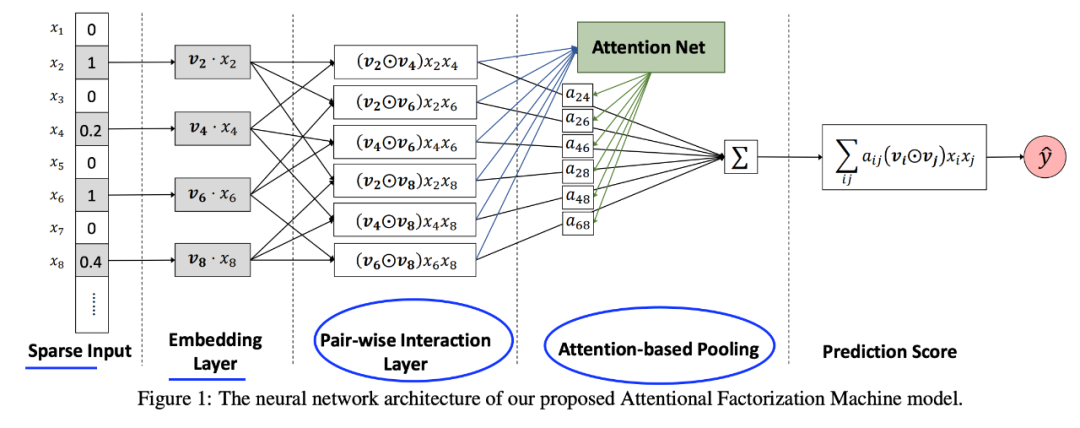
成对式交互层简介以及跟FM的关系如下

基于注意力的池化层简介如下


下面是比较流行的防止过拟合的方法以及在作者们所提模型中使用的细节简介

作者们所提方法跟GBFM的区别在于,AFM可以学习特征交互的重要性

此外,AFM相对Wide & Deep和DeepCross的解释性更强

作者们所用的数据集以及特征数描述如下

评估标准如下

参与对比的几种方法简介如下

几种方法的参数设置如下


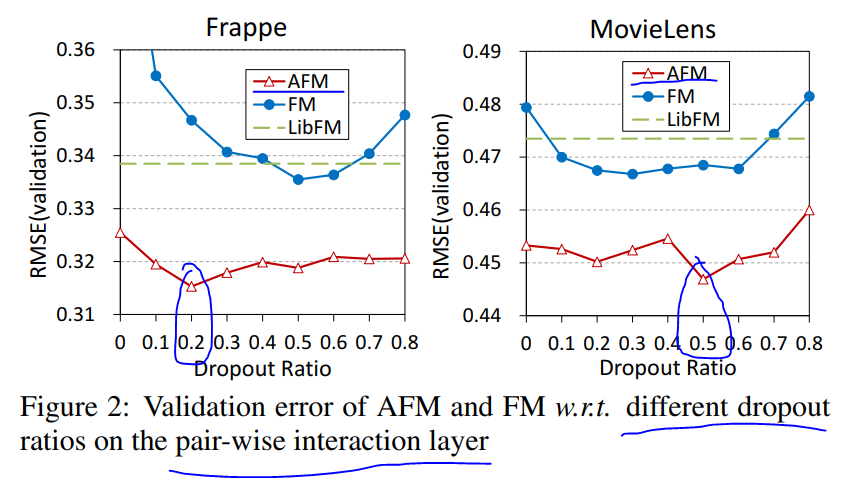
dropout对模型效果影响图示如下
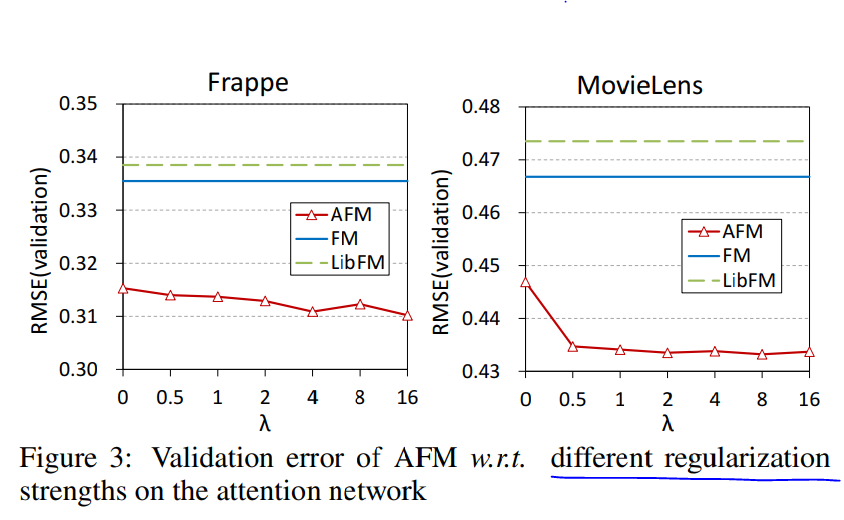
不同的正则系数对模型效果影响如下
不同的注意力因子对模型效
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 6499
6499

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









