




 本文深入探讨MySQL索引的性能影响,对比普通索引、唯一索引及主键索引的效能,讲解字符串索引策略,分析索引使用误区,提供优化技巧。
本文深入探讨MySQL索引的性能影响,对比普通索引、唯一索引及主键索引的效能,讲解字符串索引策略,分析索引使用误区,提供优化技巧。
索引
1. 索引的影响
ttps://img-blog.csdnimg.cn/20200623135902174.png)
MySQL环境:CPU 8 MEM 16G IOPS 300
表数据量:6W行数据,大小74M左右。
select * from xxx where a='xxxx'; #唯一一行
先读取该表前1000行,读入其数据页入缓存。
该字段非索引耗时:0.198 sec
该字段为索引(唯一/非唯一):0.000 sec
1.1 执行计划
不使用索引:
 使用唯一索引:
使用唯一索引:

使用普通索引: 总结:
总结:
索引对性能有影响,且随着数据量变大,而效果明显。
2. 普通索引、唯一索引、主键索引性能
2.1 主键索引与非主键索引
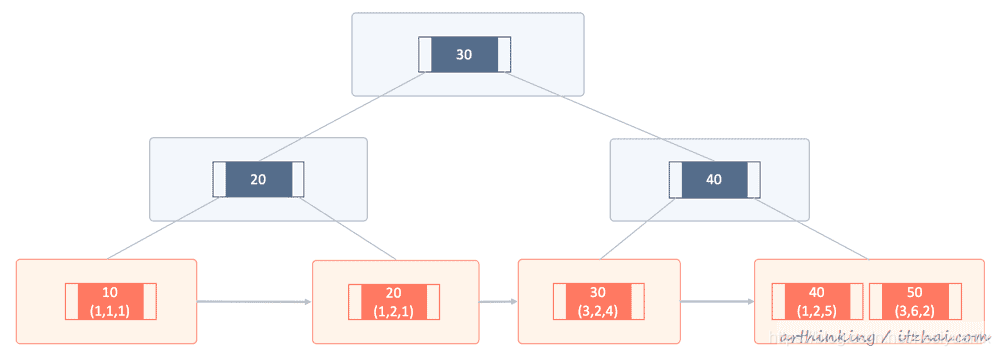
当在表上面定义了PRIMARY KEY之后,InnoDB会把它作为聚集索引;
为此,为你的每个表定义一个PRIMARY KEY。如果没有唯一并且非空的字段或者一组列,那么请添加一个自增列;
如果您没有为表定义PRIMARY KEY,则MySQL会找到第一个不带null值的UNIQUE索引,并其用作聚集索引;
如果表没有PRIMARY KEY或没有合适的UNIQUE索引,则InnoDB 内部会生成一个隐藏的聚集索引GEN_CLUST_INDEX,作为行ID,行ID是一个6字节的字段,随着数据的插入而自增;
性能:这个几乎是其他索引操作数据CURD的必经之路(部分查询除外)
2.2 查询的性能
查询操作
普通索引:查找到满足条件的第一个记录后,需要查找下一个记录,直到碰到第一个不满足条件的记录;
唯一索引:由于索引定义了唯一性,查找到第一个满足条件的记录后,就会停止继续检索;
性能差距:微乎其微 (k=5刚好是该索引页最后一条记录,需要读取下个索引页影响稍微大点,但是概率低)。
2.3 插入/更新的性能
changge buff介绍:
在不影响数据一致性前提下(个人存疑? 不需要读入就可以执行的更新 如果where带条件是否就不行了),InnoDB 会将更新操作缓存在change buffer中,从而减少磁盘的读入,在下次访问该数据时,读入内存并合并。
change buffer 用的是 buffer pool 里的内存,因此不能无限增大。change buffer 的大小,可以通过参数 innodb_change_buffer_max_size 来动态设置。这个参数设置为 50 的时候,表示 change buffer 的大小最多只能占用 buffer pool 的 50%。
插入一条key = 4 的数据
这个记录要插入的目标页在内存中:
唯一索引来说,找到 3 和 5 之间的位置,判断到没有冲突,插入这个值,语句执行结束;
普通索引来说,找到 3 和 5 之间的位置,插入这个值,语句执行结束;
性能差异:普通索引和唯一索引对更新语句性能影响的差别,只是一个判断,只会耗费微小的 CPU 时间。
这个记录要更新的目标页不在内存中:
对于唯一索引来说,需要将数据页读入内存,判断到没有冲突,插入这个值,语句执行结束;
对于普通索引来说,则是将更新记录在 change buffer,语句执行就结束了。
总结:
业务代码已经保证不会写入重复数据”的情况下,使用普通索引(性能更好,使用change buffer减少了磁盘随机读)。
业务代码需要从数据库保障唯一情况下,还是使用唯一索引。
3. 字符串类型如何加索引
3.1 前缀索引
alter table SUser add index index1(order_no(6));
优势: 索引结构中的key占用空间会更小,那么每个索引页上能够放下更多的索引。
劣势:
增加额外的记录扫描次数(前缀的区分度越低,扫描到满足索引条件数据会越多,回表的次数也会变多)
使用前缀索引,定义好长度(区分度),就可以做到既节省空间,又不用额外增加太多的查询成本。
经验:一般使用前缀索引能够过滤掉95%以上不同数据即可,再网上过滤 考虑每增加1%需要多使用的字段长度是否值。
无法使用覆盖索引:前缀索引不知道是否该字段为全部字段,需要进行回表确认。
总结:
使用前缀索引,定义好长度,就可以做到既节省空间,又不用额外增加太多的查询成本。
3.2 倒叙索引
select field_list from t where id_card = reverse('input_id_card_string');
使用hash映射:
劣:每次CPU消耗(可以程序端做),倒序存储,再创建前缀索引,用于绕过字符串本身前缀的区分度不够的问题。
3.3 hash索引
select field_list from t where id_card_crc=crc32('input_id_card_string') and id_card='input_id_card_string'
劣:需要数据库增加一个额外的hash字段,且需要在该字段添加索引,同时在每次查询时候,需要调用一次crc32 hash函数进行计算,增加CPU消耗(比倒序消耗高);
优:hash冲突概率小,平均查询行数约为1,不支持范围查询,hash字段仅能等值查询;
二次优化:程序hash优化(hash函数自定义规则),数据库直接存。
4. 为什么有时候不使用索引
4.1 order by的情况
问题:在sale_time建立普通索引,想利用索引来进行排序,发现并未使用索引。
示例: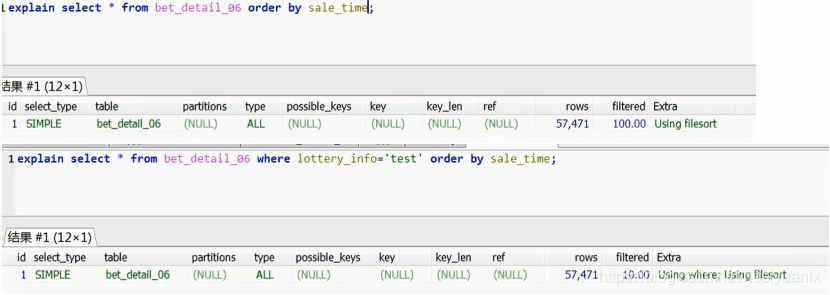
原因:优化器认为原字段无序,走二级索引再回表成本比全表扫描高,所以选择走全表扫描,再排序。
解决:使用limit (如果limit的值比较小,优化器认为索引有序回表查比回表高,即是没有二级索引 mysql5.6 针对order by
4.2 存在非索引字段的多条件过滤。
select t1.f1, t1.f2, t2.f1 ,t2.f2 from t1 left jion t2 on t1.index_1 = t2.index_2
where t1.index1 = xxxx and t1.f3=xxx , t1.f4=xxxx and t2.f3=xxxx order by t2.f4 ASSC LIMIT 100
执行结果:
优化器选择表1全表扫描,满足规则的放入临时表,而不使用index1,因使用了非索引字段f3,优化器会因为f3字段必须回表查询,而选择全表扫描
优化:
将 index1 与 f3 建立联合索引,让优化器使用索引下推的判断,从而使表1使用上索引。
sql
select * from t where (a between 1 and 1000) and (b between 50000 and 100000) order by b limit 1;
4.3 多索引或部分非索引where条件
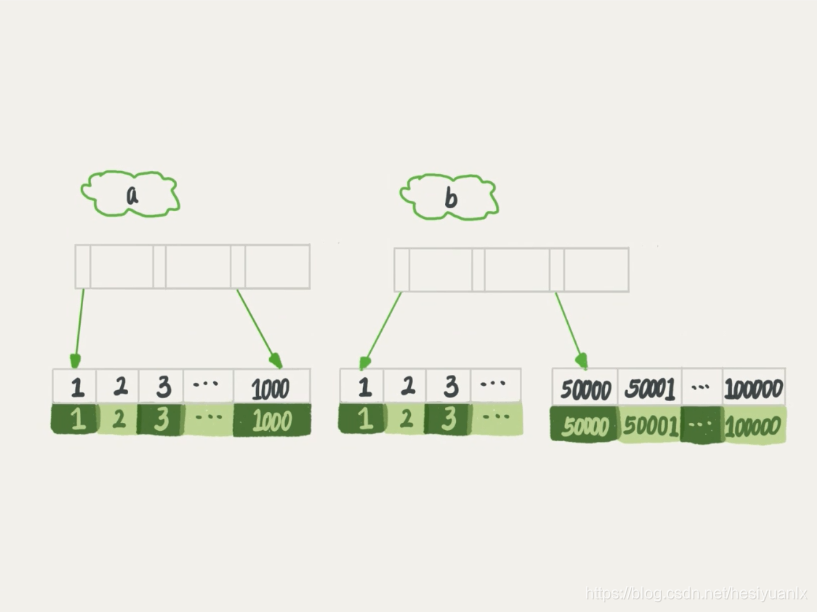
 问题:a,b两个索引,但是优化器选择了b,原因在于优化器认为使用索引B遍历的数据条数更少。
问题:a,b两个索引,但是优化器选择了b,原因在于优化器认为使用索引B遍历的数据条数更少。
优化1:sql语句添加添加force index
 优化2:添加排序,因为二级索引有序,优化器会考虑使用索引
优化2:添加排序,因为二级索引有序,优化器会考虑使用索引
select * from t where (a between 1 and 1000) and (b between 50000 and 100000) order by b,a limit 1;
```sql
select * from t where (a between 1 and 1000) and (b between 50000 and 100000) order by b,a limit 1;
优化3:针对性修改sql语句
select * from (select * from t where (a between 1 and 1000) and (b between 50000 and 100000) order b
优化4:新建一个更适合的索引,或删掉误用的索引。
4.4 在字段上使用函数操作
4.4.1 直接函数操作
mysql> select count(*) from tradelog where month(t_modified)=7;
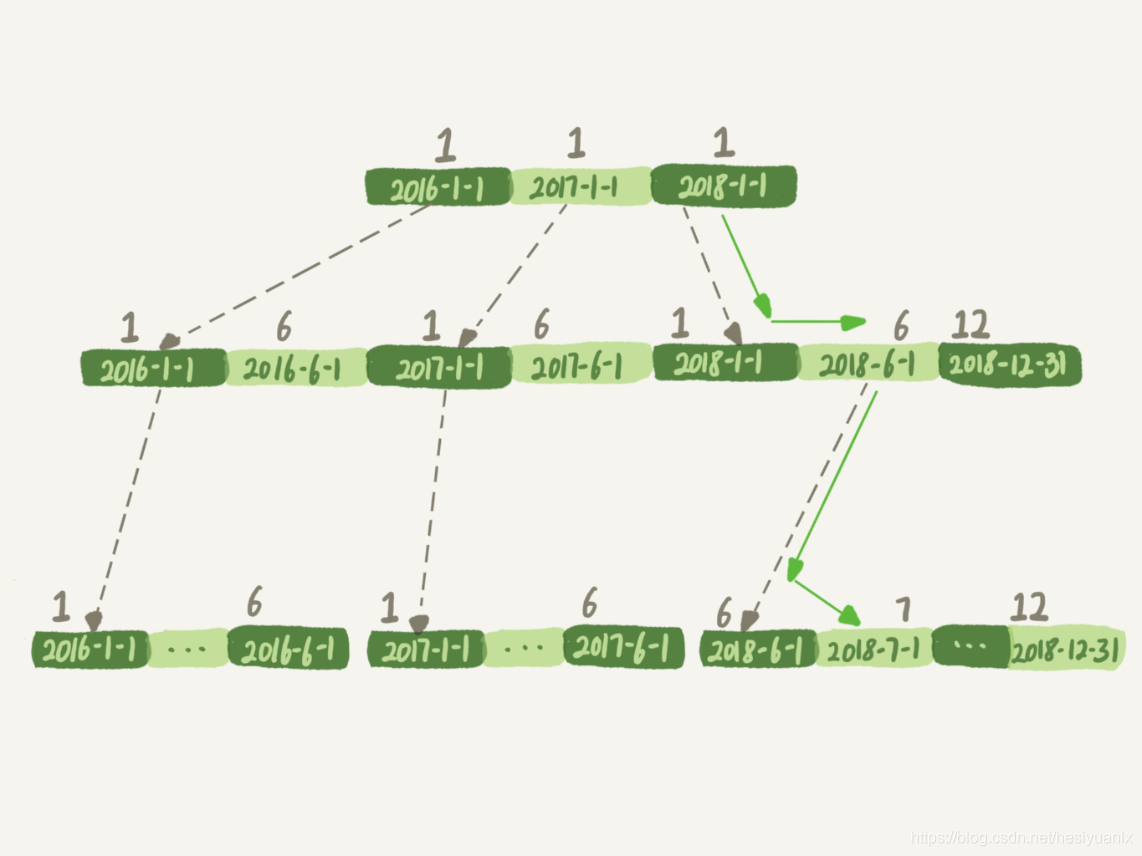 结论:对索引字段做函数操作,可能会破坏索引值的有序性,因此优化器就决定放弃走树搜索功能。
结论:对索引字段做函数操作,可能会破坏索引值的有序性,因此优化器就决定放弃走树搜索功能。
优化:
mysql> select count(*) from tradelog where
-> (t_modified >= ‘2016-7-1’ and t_modified<‘2016-8-1’) or
-> (t_modified >= ‘2017-7-1’ and t_modified<‘2017-8-1’) or
-> (t_modified >= ‘2018-7-1’ and t_modified<‘2018-8-1’);
4.4.2 隐式类型转换
mysql> select * from tradelog where tradeid=110717;
实际为:
mysql> select * from tradelog where CAST(tradid AS signed int) = 110717;
4.4.3 隐式编码集转换
mysql> select d.* from tradelog l, trade_detail d where d.tradeid=l.tradeid and l.id=2; /*语句Q1*/
实际为:
select * from trade_detail where CONVERT(traideid USING utf8mb4)=$L2.tradeid.value;
-------------------以下不属于索引 ,待挪至其他总结------------------------------------------------
如何随机取一行
select word from words order by rand() limit 3;
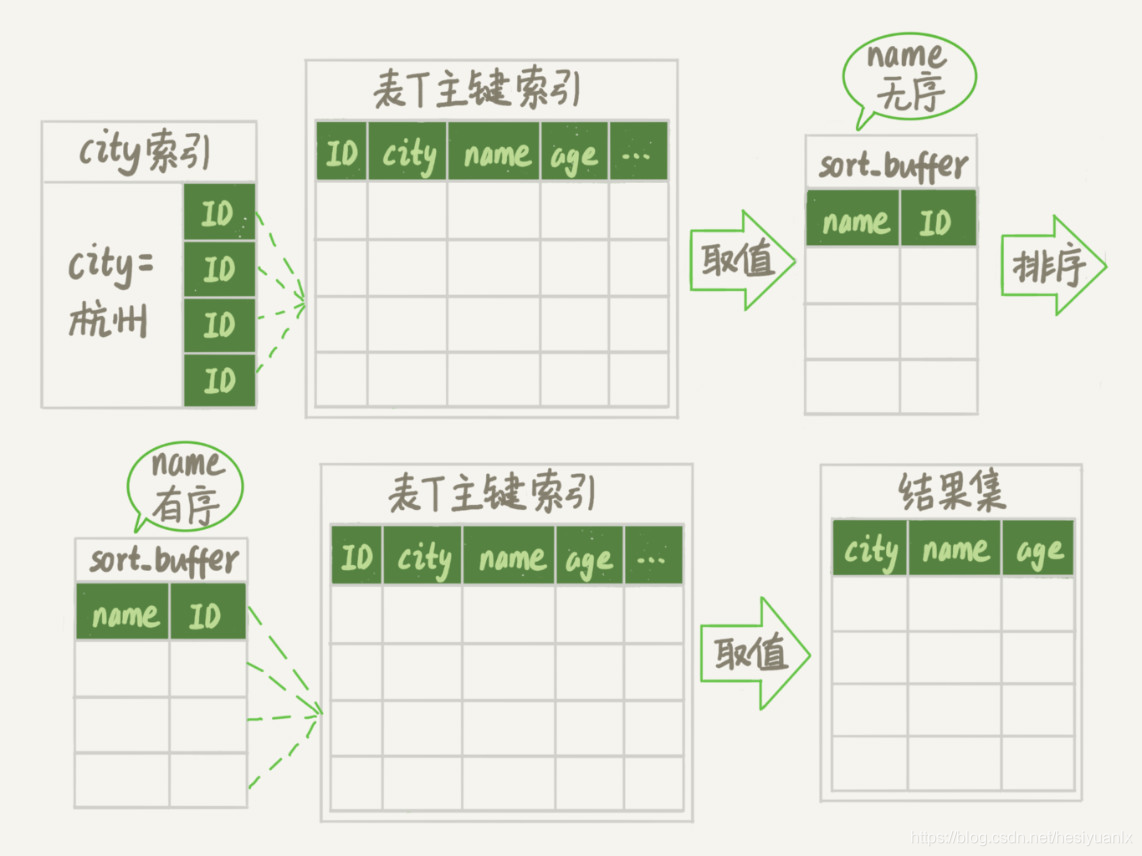
如果内存足够(tmp_table_size 参数配置),使用内存临时表实现逻辑:
- 创建一个临时表。这个临时表使用的是 memory 引擎,表里有两个字段,第一个字段是 double 类型,为了后面描述方便,记为字段 R,第二个字段是 varchar(64) 类型,记为字段 W。并且,这个表没有建索引。
- 从 words 表中,按主键顺序取出所有的 word 值。对于每一个 word 值,调用 rand() 函数生成一个大于 0 小于 1 的随机小数,并把这个随机小数和 word 分别存入临时表的 R 和 W 字段中,到此,扫描行数是 10000。
- 现在临时表有 10000 行数据了,接下来你要在这个没有索引的内存临时表上,按照字段 R 排序。
- 初始化 sort_buffer。sort_buffer 中有两个字段,一个是 double 类型,另一个是整型。
- 从内存临时表中一行一行地取出 R 值和位置信息(我后面会和你解释这里为什么是“位置信息”),分别存入 sort_buffer 中的两个字段里。这个过程要对内存临时表做全表扫描,此时扫描行数增加 10000,变成了 20000。
- 在 sort_buffer 中根据 R 的值进行排序。注意,这个过程没有涉及到表操作,所以不会增加扫描行数。
- 排序完成后,取出前三个结果的位置信息,依次到内存临时表中取出 word 值,返回给客户端。这个过程中,访问了表的三行数据,总扫描行数变成了 20003。
如果内存不足,则使用磁盘临时表(默认是 InnoDB,是由参数 internal_tmp_disk_storage_engine 控制),但是在排序和limit的情况下,采用是 MySQL 5.6 版本引入的一个新的排序算法,即:优先队列排序算法,其实仅需要维护一个最大堆即可(要求不大于sort_buffer_size大小)。
总结:无论如何,这种取随机几个数的操作,都将导致大量排序,严重影响性能和资源消耗。
优化1:
select count(*) from t;
### 程序中获取不大于count(*)的随机整数a,b,c
select * from t limit a,1
select * from t limit b,1
select * from t limit c,1
一次获取多个随机行(前提返回数据不是很多):
select count(*) from t;
### 程序中获取不大于count(*)的随机整数假设(a > b > c)
select * from t limit c, a-c +1
好处:减少扫描行数,坏处,返回的数量量变大了
改进思考:
读入数据库数据,放入redis,每次从redis中读取(利用hash值)
数据
- bigint(1)和bigint(19)都能存储2^64-1范围内的值。
- int是2^32-1。
事务隔离性问题
- 程序都建议使用RC作为默认事务隔壁级别
- Mysql 默认事务隔离级别是RR

















 174万+
174万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









