




 本文深入解析MyBatis的生命周期管理、结果集映射机制及缓存策略。介绍不同组件的最佳作用范围,展示如何通过ResultMap处理多表关联查询,并探讨缓存如何提升查询效率。
本文深入解析MyBatis的生命周期管理、结果集映射机制及缓存策略。介绍不同组件的最佳作用范围,展示如何通过ResultMap处理多表关联查询,并探讨缓存如何提升查询效率。
一、生命域和作用周期
理解我们目前已经讨论过的不同作用域和生命周期类是至关重要的,因为错误的使用会导致非常严重的并发问题。
我们可以先画一个流程图,分析一下Mybatis的执行过程!
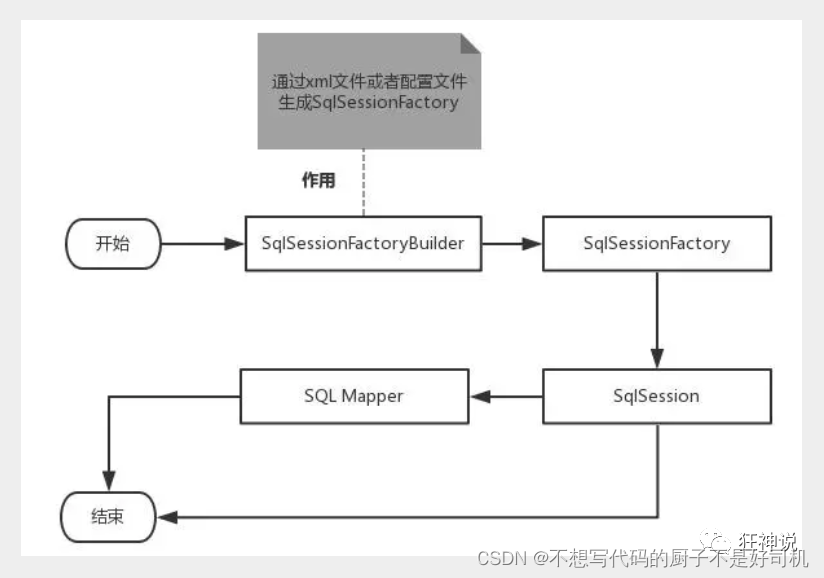
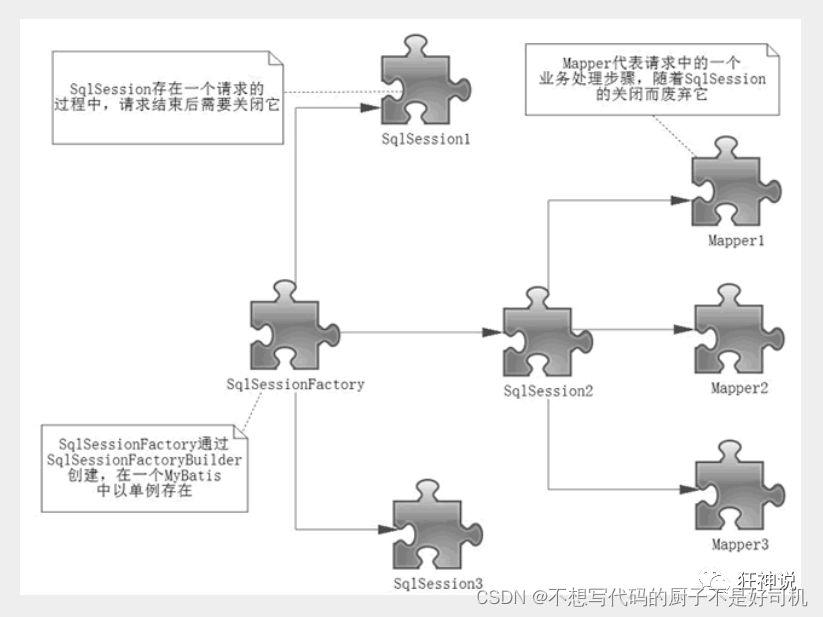
作用域理解
-
SqlSessionFactoryBuilder 的作用在于创建 SqlSessionFactory,创建成功后,SqlSessionFactoryBuilder 就失去了作用,所以它只能存在于创建 SqlSessionFactory 的方法中,而不要让其长期存在。因此 SqlSessionFactoryBuilder 实例的最佳作用域是方法作用域(也就是局部方法变量)。
-
SqlSessionFactory 可以被认为是一个数据库连接池,它的作用是创建 SqlSession 接口对象。因为 MyBatis 的本质就是 Java 对数据库的操作,所以 SqlSessionFactory 的生命周期存在于整个 MyBatis 的应用之中,所以一旦创建了 SqlSessionFactory,就要长期保存它,直至不再使用 MyBatis 应用,所以可以认为 SqlSessionFactory 的生命周期就等同于 MyBatis 的应用周期。
-
由于 SqlSessionFactory 是一个对数据库的连接池,所以它占据着数据库的连接资源。如果创建多个 SqlSessionFactory,那么就存在多个数据库连接池,这样不利于对数据库资源的控制,也会导致数据库连接资源被消耗光,出现系统宕机等情况,所以尽量避免发生这样的情况。
-
因此在一般的应用中我们往往希望 SqlSessionFactory 作为一个单例,让它在应用中被共享。所以说 SqlSessionFactory 的最佳作用域是应用作用域。
-
如果说 SqlSessionFactory 相当于数据库连接池,那么 SqlSession 就相当于一个数据库连接(Connection 对象),你可以在一个事务里面执行多条 SQL,然后通过它的 commit、rollback 等方法,提交或者回滚事务。所以它应该存活在一个业务请求中,处理完整个请求后,应该关闭这条连接,让它归还给 SqlSessionFactory,否则数据库资源就很快被耗费精光,系统就会瘫痪,所以用 try…catch…finally… 语句来保证其正确关闭。
-
所以 SqlSession 的最佳的作用域是请求或方法作用域。
二、结果集映射(ResultMap)
- 假设有两个表,一个Teacher表,一个Student表,一个老师会教多个学生,所以老师跟学生的关系是一对多,学生跟老师的关系是多对一

1、一对一或多对一
实体类
@Data //GET,SET,ToString,有参,无参构造
// 老师实体类
public class Teacher {
private int id;
private String name;
}
@Data
// 学生实体类
public class Student {
private int id;
private String name;
//多个学生可以是同一个老师,即多对一
private Teacher teacher;
}
Mapper接口对应的Mapper.xml文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.kuang.mapper.StudentMapper">
<!--
需求:获取所有学生及对应老师的信息
思路:
1. 获取所有学生的信息
2. 根据获取的学生信息的老师ID->获取该老师的信息
3. 思考问题,这样学生的结果集中应该包含老师,该如何处理呢,数据库中我们一般使用关联查询?
1. 做一个结果集映射:StudentTeacher
2. StudentTeacher结果集的类型为 Student
3. 学生中老师的属性为teacher,对应数据库中为tid。
多个 [1,...)学生关联一个老师=> 一对一,一对多
4. 查看官网找到:association – 一个复杂类型的关联;使用它来处理关联查询
-->
<select id="getStudents" resultMap="StudentTeacher">
select * from student
</select>
<resultMap id="StudentTeacher" type="Student">
<!--association对应的是Student类中的teacher对象,property对应的是成员变量名,tid是作为getTeacher查询的条件,javaType代表类型为Teacher-->
<association property="teacher" column="tid" javaType="Teacher" select="getTeacher"/>
</resultMap>
<!--
这里传递过来的id,只有一个属性的时候,下面可以写任何值
association中column多参数配置:
column="{key=value,key=value}"
其实就是键值对的形式,key是传给下个sql的取值名称,value是片段一中sql查询的字段名。
-->
<select id="getTeacher" resultType="teacher">
select * from teacher where id = #{id}
</select>
</mapper>
注意点说明
<resultMap id="StudentTeacher" type="Student">
<!--association关联属性 property属性名 javaType属性类型 column在多的一方的表中的列名-->
<association property="teacher" column="{id=tid,name=tid}" javaType="Teacher" select="getTeacher"/>
</resultMap>
<!--
这里传递过来的id,只有一个属性的时候,下面可以写任何值
association中column多参数配置:
column="{key=value,key=value}"
其实就是键值对的形式,key是传给下个sql的取值名称,value是片段一中sql查询的字段名。
-->
<select id="getTeacher" resultType="teacher">
select * from teacher where id = #{id} and name = #{name}
</select>
这种查询方式等价于嵌套查询
select s.*, (select t.name from teacher t where t.id = s.tid) as tname from student s;
当然,也可以通过表连接的方式查询
<!--
思路:
1. 直接查询出结果,进行结果集的映射
-->
<select id="getStudents2" resultMap="StudentTeacher2" >
select s.id sid, s.name sname , t.name tname
from student s,teacher t
where s.tid = t.id
</select>
<resultMap id="StudentTeacher2" type="Student">
<!--property对应的是实体类中的成员变量,column对应的是查询结果的列名或别名-->
<!--id代表主键-->
<id property="id" column="sid"/>
<!--result即普通成员属性-->
<result property="name" column="sname"/>
<!--association对应的是Student类中的teacher对象-->
<association property="teacher" javaType="Teacher">
<result property="name" column="tname"/>
</association>
</resultMap>
2、一对多
实体类
@Data
public class Student {
private int id;
private String name;
private int tid;
}
@Data
public class Teacher {
private int id;
private String name;
//一个老师多个学生
private List<Student> students;
}
Mapper接口对应的Mapper.xml配置文件
<select id="getTeacher2" resultMap="TeacherStudent2">
select * from teacher where id = #{id}
</select>
<resultMap id="TeacherStudent2" type="Teacher">
<!--collection对应的是Teacher对象中的students成员变量,类型为List<Student>-->
<collection property="students" javaType="ArrayList" ofType="Student" column="id" select="getStudentByTeacherId"/>
</resultMap>
<select id="getStudentByTeacherId" resultType="Student">
select * from student where tid = #{id}
</select>
<mapper namespace="com.kuang.mapper.TeacherMapper">
<!--
思路:
1. 从学生表和老师表中查出学生id,学生姓名,老师姓名
2. 对查询出来的操作做结果集映射
1. 集合的话,使用collection!
JavaType和ofType都是用来指定对象类型的
JavaType是用来指定pojo中属性的类型
ofType指定的是映射到list集合属性中pojo的类型。
-->
<select id="getTeacher" resultMap="TeacherStudent">
select s.id sid, s.name sname , t.name tname, t.id tid
from student s,teacher t
where s.tid = t.id and t.id=#{id}
</select>
<resultMap id="TeacherStudent" type="Teacher">
<result property="name" column="tname"/>
<!--collection对应的是Teacher对象中的students成员变量,类型为List<Student>-->
<collection property="students" ofType="Student">
<result property="id" column="sid" />
<result property="name" column="sname" />
<result property="tid" column="tid" />
</collection>
</resultMap>
</mapper>
三、Mybatis缓存
简介
1、什么是缓存 [ Cache ]?
-
存在内存中的临时数据。
-
将用户经常查询的数据放在缓存(内存)中,用户去查询数据就不用从磁盘上(关系型数据库数据文件)查询,从缓存中查询,从而提高查询效率,解决了高并发系统的性能问题。
2、为什么使用缓存?
- 减少和数据库的交互次数,减少系统开销,提高系统效率。
3、什么样的数据能使用缓存?
- 经常查询并且不经常改变的数据。
Mybaits缓存
-
MyBatis包含一个非常强大的查询缓存特性,它可以非常方便地定制和配置缓存。缓存可以极大的提升查询效率。
-
MyBatis系统中默认定义了两级缓存:一级缓存和二级缓存
-
默认情况下,只有一级缓存开启。(SqlSession级别的缓存,也称为本地缓存)
-
二级缓存需要手动开启和配置,他是基于namespace级别的缓存。
-
-
为了提高扩展性,MyBatis定义了缓存接口Cache。我们可以通过实现Cache接口来自定义二级缓存
一级缓存
一级缓存也叫本地缓存:
- 与数据库同一次会话期间查询到的数据会放在本地缓存中
- 一个SqlSession对应一个一级缓存
- 相同的查询条件,会直接从缓存中获取数据,不会查询数据库
- SqlSession关闭或提交后,一级缓存会被清除
- 一级缓存失效的情况
- SqlSession不同
- SqlSeesion相同,查询sql不同
- SqlSeesion相同,两次查询之间执行了增删改操作
- SqlSeesion相同,手动清除了缓存
二级缓存
-
二级缓存也叫全局缓存,一级缓存作用域太低了,所以诞生了二级缓存
-
基于namespace级别的缓存,一个名称空间,对应一个二级缓存;
-
工作机制
-
一个会话查询一条数据,这个数据就会被放在当前会话的一级缓存中;
-
如果当前会话关闭或提交了,这个会话对应的一级缓存就没了;如果开启了二级缓存,一级缓存中的数据会被保存到二级缓存中;
-
同样的,同一个命名空间下
-
一个命名空间(mapper类)对应一个二级缓存
-
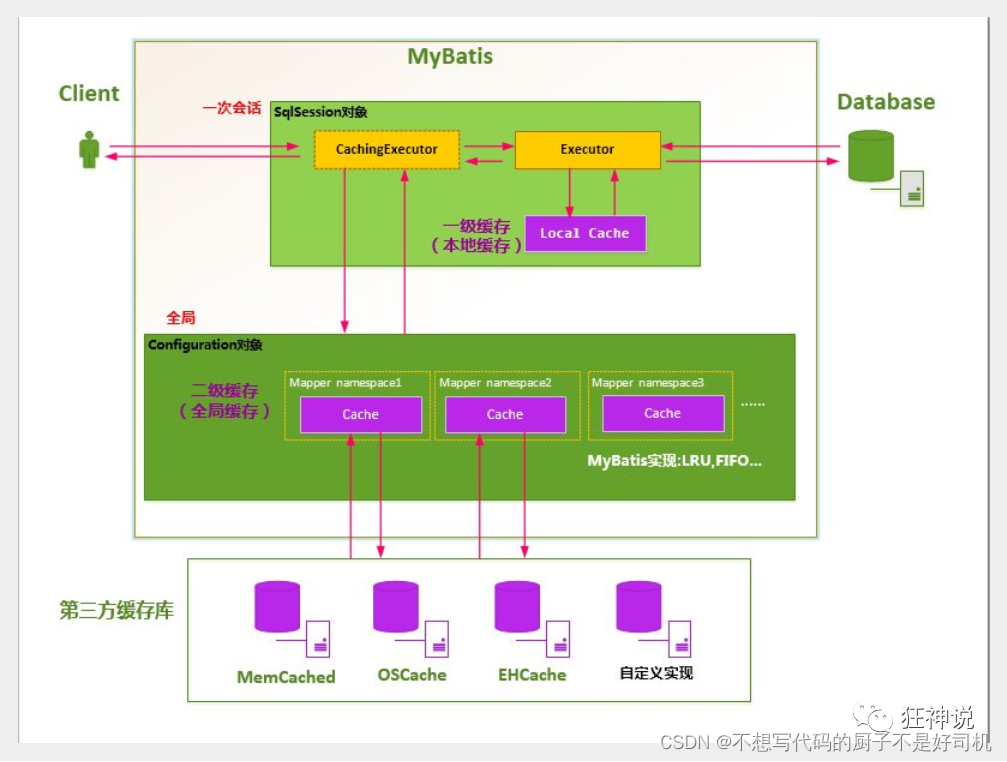
一级缓存测试
@Test
public void test11() {
// 声明一个SqlSession
SqlSession sqlSession = MybatisUtil.getSqlSession();
// 同一个sqlSession下,声明三个mapper
UserMapper userMapper1 = sqlSession.getMapper(UserMapper.class);
UserMapper userMapper2 = sqlSession.getMapper(UserMapper.class);
TeacherMapper teacherMapper = sqlSession.getMapper(TeacherMapper.class);
// sqlSession中的userMapper1查询
List<User> users1 = userMapper1.selectUserList();
// sqlSession2中的userMapper2查询
List<User> users2 = userMapper2.selectUserList();
// 结果为true,命中此sqlSession的一级缓存
System.out.println(users1 == users2);
// 新增一个teacher
Teacher teacher = new Teacher();
teacher.setId(3);
teacher.setName("hahaha");
teacherMapper.addTeacher(teacher);
// sqlSession2中的userMapper2查询
List<User> users3 = userMapper2.selectUserList();
// 结果为false,说明此sqlSession的任何增删改操作都会影响此sqlSession的一级缓存
System.out.println(users1 == users3);
}
二级缓存测试
// 声明两个SqlSession
SqlSession sqlSession1 = MybatisUtil.getSqlSession();
SqlSession sqlSession2 = MybatisUtil.getSqlSession();
// 声明三个mapper
UserMapper userMapper1 = sqlSession1.getMapper(UserMapper.class);
UserMapper userMapper2 = sqlSession2.getMapper(UserMapper.class);
TeacherMapper teacherMapper2 = sqlSession2.getMapper(TeacherMapper.class);
// sqlSession1中的userMapper1查询
List<User> users1 = userMapper1.selectUserList();
// 查询后提交,一级缓存清除,保存到UserMapper的二级缓存中
sqlSession1.commit();
// sqlSession2中的userMapper2查询
List<User> users20 = userMapper2.selectUserList();
// 结果为true,命中UserMapper的二级缓存
System.out.println(users1 == users20);
// 通过sqlsession2中的teacherMapper2新增一个user
User user = new User();
user.setId(8);
user.setUsername("hahahaha");
user.setPassword("123456");
teacherMapper2.addUser(user);
sqlSession2.commit();
// sqlSession2中的userMapper2查询
List<User> users21 = userMapper2.selectUserList();
// 结果为true,说明其他命名空间的增删改操作不会影响当前命名空间的缓存,是个需要注意的地方
System.out.println(users1 == users21);
总结
- 对于一级缓存,同一个SqlSeesion中,任何增删改操作都会影响此SqlSession的缓存
- 对于二级缓存,只有同一个命名空间的增删改操作才会影响此命名空间的缓存
- 当然,MyBatis定义了缓存接口Cache,我们可以通过实现Cache接口来自定义二级缓存

















 888
888

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









