







 本文详细介绍了Hive SQL中的各类函数,包括简单函数、聚合函数、窗口函数等,并提供了丰富的示例帮助理解如何在实际场景中应用这些函数。
本文详细介绍了Hive SQL中的各类函数,包括简单函数、聚合函数、窗口函数等,并提供了丰富的示例帮助理解如何在实际场景中应用这些函数。
https://blog.youkuaiyun.com/scgaliguodong123_/article/details/46954009
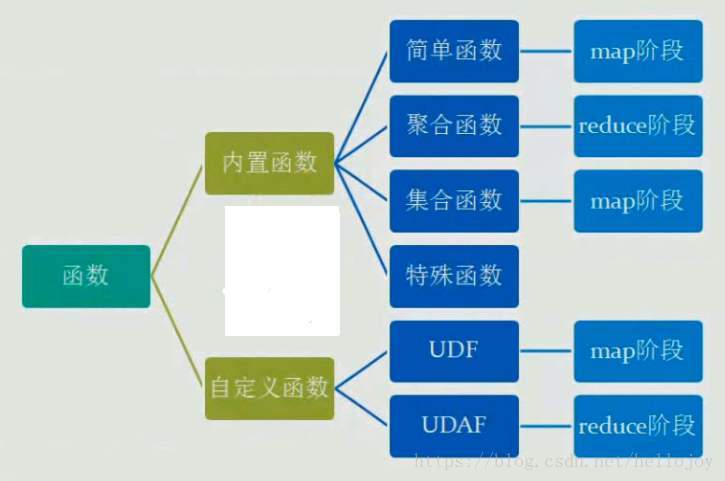
函数分类
HIVE CLI命令
显示当前会话有多少函数可用
SHOW FUNCTIONS;
显示函数的描述信息
DESC FUNCTION concat;
显示函数的扩展描述信息
DESC FUNCTION EXTENDED concat;
简单函数
函数的计算粒度为单条记录。
关系运算
数学运算
逻辑运算
数值计算
类型转换
日期函数
条件函数
字符串函数
统计函数
聚合函数
函数处理的数据粒度为多条记录。
sum()—求和
count()—求数据量
avg()—求平均直
distinct—求不同值数
min—求最小值
max—求最人值
集合函数
复合类型构建
复杂类型访问
复杂类型长度
特殊函数
窗口函数
应用场景
用于分区排序
动态Group By
Top N
累计计算
层次查询
Windowing functions
lead
lag
FIRST_VALUE
LAST_VALUE
- 1
- 2
- 3
- 4
分析函数
Analytics functions
RANK
ROW_NUMBER
DENSE_RANK
CUME_DIST
PERCENT_RANK
NTILE
- 1
- 2
- 3
- 4
- 5
- 6
混合函数
java_method(class,method [,arg1 [,arg2])
reflect(class,method [,arg1 [,arg2..]])
hash(a1 [,a2...])
- 1
- 2
- 3
UDTF
lateralView: LATERAL VIEW udtf(expression) tableAlias AS columnAlias (',' columnAlias)*
fromClause: FROM baseTable (lateralView)*
- 1
- 2
ateral view用于和split, explode等UDTF一起使用,它能够将一行数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。lateral view首先为原始表的每行调用UDTF,UTDF会把一行拆分成一或者多行,lateral view再把结果组合,产生一个支持别名表的虚拟表。
常用函数Demo:
create table employee(
id string,
money double,
type string
)
row format delimited
fields terminated by '\t'
lines terminated by '\n'
stored as textfile;
load data local inpath '/liguodong/hive/data' into table employee;
select * from employee;
优先级依次为NOT AND OR
select id,money from employee where (id='1001' or id='1002') and money='100';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
cast类型转换
select cast(1.5 as int);
- 1
if判断
if(con,'','');
hive (default)> select if(2>1,'YES','NO');
YES
- 1
- 2
- 3
- 4
case when con then '' when con then '' else '' end (''里面类型要一样)
select case when id='1001' then 'v1001' when id='1002' then 'v1002' else 'v1003' end from employee;
- 1
- 2
- 3
get_json_object
get_json_object(json 解析函数,用来处理json,必须是json格式)
select get_json_object('{"name":"jack","age":"20"}','$.name');
- 1
- 2
URL解析函数
parse_url(string urlString, string partToExtract [, string keyToExtract])
select parse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1', 'HOST') from
employee limit 1;
- 1
- 2
- 3
- 4
字符串连接函数: concat
语法: concat(string A, string B…)
返回值: string
说明:返回输入字符串连接后的结果,支持任意个输入字符串
举例:
hive> select concat('abc','def’,'gh') from lxw_dual;
abcdefgh
- 1
- 2
带分隔符字符串连接函数: concat_ws
语法: concat_ws(string SEP, string A, string B…)
返回值: string
说明:返回输入字符串连接后的结果, SEP 表示各个字符串间的分隔符
concat_ws(string SEP, array<string>)
举例:
hive> select concat_ws(',','abc','def','gh') from lxw_dual;
abc,def,gh
- 1
- 2
- 3
- 4
- 5
列出该字段所有不重复的值,相当于去重
collect_set(id) //返回的是数组
列出该字段所有的值,列出来不去重
collect_list(id) //返回的是数组
select collect_set(id) from taborder;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
求和
sum(money)
统计列数
count(*)
select sum(num),count(*) from taborder;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
窗口函数
first_value(第一行值)
first_value(money) over (partition by id order by money)
select ch,num,first_value(num) over (partition by ch order by num) from taborder;
- 1
- 2
- 3
- 4
- 5
rows between 1 preceding and 1 following (当前行以及当前行的前一行与后一行)
hive (liguodong)> select ch,num,first_value(num) over (partition by ch order by num ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) from taborder;
- 1
- 2
- 3
- 4
last_value 最后一行值
hive (liguodong)> select ch,num,last_value(num) over (partition by ch) from taborder;
- 1
- 2
- 3
lead
去当前行后面的第二行的值
lead(money,2) over (order by money)
lag
去当前行前面的第二行的值
lag(money,2) over (order by money)
```
```
select ch, num, lead(num,2) over (order by num) from taborder;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
select ch, num, lag(num,2) over (order by num) from taborder;
- 1
rank排名
rank() over(partition by id order by money)
- 1
select ch, num, rank() over(partition by ch order by num) as rank from taborder;
- 1
select ch, num, dense_rank() over(partition by ch order by num) as dense_rank from taborder;
- 1
cume_dist
cume_dist (相同值的最大行号/行数)
cume_dist() over (partition by id order by money)
percent_rank (相同值的最小行号-1)/(行数-1)
第一个总是从0开始
percent_rank() over (partition by id order by money)
select ch,num,cume_dist() over (partition by ch order by num) as cume_dist,
percent_rank() over (partition by ch order by num) as percent_rank
from taborder;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
ntile分片
ntile(2) over (order by money desc) 分两份
select ch,num,ntile(2) over (order by num desc) from taborder;
- 1
- 2
- 3
- 4
混合函数
select id,java_method("java.lang,Math","sqrt",cast(id as double)) as sqrt from hiveTest;
- 1
UDTF
select id,adid
from employee
lateral view explode(split(type,'B')) tt as adid;
explode 把一列转成多行
hive (liguodong)> select id,adid
> from hiveDemo
> lateral view explode(split(str,',')) tt as adid;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
正则表达式
使用正则表达式的函数
regexp_replace(string subject A,string B,string C)
regexp_extract(string subject,string pattern,int index)
hive> select regexp_replace('foobar', 'oo|ar', '') from lxw_dual;
fb
hive> select regexp_replace('979|7.10.80|8684', '.*\\|(.*)',1) from hiveDemo limit 1;
- 1
- 2
- 3
- 4
hive> select regexp_replace('979|7.10.80|8684', '(.*?)\\|(.*)',1) from hiveDemo limit 1;
- 1

















 1331
1331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









