



 本文通过Python的pandas和scipy库,详细介绍了如何从Excel文件中读取年龄数据,进行描述性统计分析,计算平均年龄,并利用正态分布和T分布抽取样本数据,计算置信区间。此外,还展示了如何通过重复抽样,计算多次样本平均数的置信区间,并用seaborn和matplotlib库绘制样本平均数的分布图。
本文通过Python的pandas和scipy库,详细介绍了如何从Excel文件中读取年龄数据,进行描述性统计分析,计算平均年龄,并利用正态分布和T分布抽取样本数据,计算置信区间。此外,还展示了如何通过重复抽样,计算多次样本平均数的置信区间,并用seaborn和matplotlib库绘制样本平均数的分布图。
1.导入数据
import numpy as np
import pandas as pd
from scipy import stats
path = 'D:\数据\data.xlsx'
data = pd.read_excel(path)
age = data['Age']
print(age.mean) #输出值为:29.64209269662921
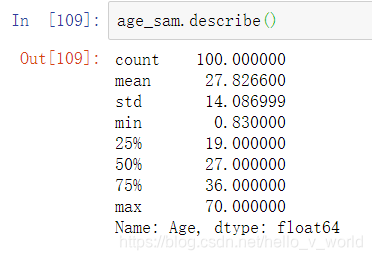
2.抽取100个样本
age_sam = age.sample(100)
age_sam.describe()
3.计算置信区间
# 正态分布下的置信区间
def norm_conf(data,confidence = 0.95):
sample_mean = np.mean(data)
# numpy.std() 求标准差的时候默认是除以 n 的,即是有偏的,np.std无偏样本标准差方式为加入参数 ddof = 1;
# pandas.std() 默认是除以n-1 的,即是无偏的
sample_std = np.std(data,ddof = 1)
conf_interval = scipy.satas.norm.interval(confidence,loc = sample_name,scale = sample_std)

# T分布下的置信区间
def ttest_conf(data,confidence = 0.95):
sample_mean = np.mean(data)
sample_std = np.std(data,ddof = 1)
sample_size = len(data)
conf_interval = scipy.satas.norm.interval(confidence, df = (sample_size - 1), loc = sample_name, scale = sample_std)

4.重复抽取数据
age_means = []
for i in range (1000):
age_sample = age.sample(100, replace = True)
sam_mean = age_sample.mean()
age.means.append(sam_mean)
norm_conf(age_means)
ttest_conf(age_means)


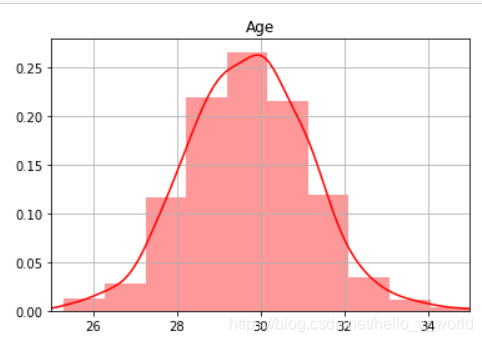
5.绘制图像
import seaborn as sns
from matplotlib import pyplot as plt
sns.set_palette("hls") #设置所有图的颜色,使用hls色彩空间
sns.distplot(scale_means,color="r",bins=10,kde=True)
plt.title('Age')
plt.xlim(25,35)
plt.grid(True)
plt.show()
参考链接:
https://blog.youkuaiyun.com/qq_43315928/article/details/103658733

















 9902
9902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









