




 本文详细介绍了编译原理在实现简单JSON解析器中的应用,包括词法分析阶段,如Tok和Token类的设计,词法错误识别;语法分析阶段,通过LR(1)文法构造LALR(1)分析表;文件读取和写入功能的实现;以及如何按路径获取JSON元素值的方法。
本文详细介绍了编译原理在实现简单JSON解析器中的应用,包括词法分析阶段,如Tok和Token类的设计,词法错误识别;语法分析阶段,通过LR(1)文法构造LALR(1)分析表;文件读取和写入功能的实现;以及如何按路径获取JSON元素值的方法。
一、词法分析阶段
1、创建Tok类,记录Token的类型以及将每个转换为相应的字符串值。
package Lex;
/**
* Created by think on 2017/6/8.
*/
public class TOK {
//Tok类型
public static final int OBJB = 0;
public static final int OBJE = 1;
public static final int ARRB = 2;
public static final int ARRE = 3;
public static final int DESC = 4;
public static final int SPLIT = 5;
public static final int STR = 6;
public static final int NUM = 7;
public static final int TRUE = 8;
public static final int FALSE = 9;
public static final int NULL = 10;
public static final int BGN = 11;
public static final int EOF = 12;
//并存储tok类型的个数
public static final int TOK_NUM = 13;
//每个Tok类型对应的字符串类型
public static final String[] CAST_STRS = { "OBJB","OBJE", "ARRB","ARRE","DESC", "SPLIT",
"STR", "NUM","TRUE", "FALSE", "NULL","BGN","EOF" };
//每个Tok类型对应的实际字符串
public static final String[] CAST_LOCAL_STRS = { "{", "}", "[", "]",
":", ",", "s", "n", "true","false", "null", "开始", "结束" };
//返回Tok类型字符串
public static String castTokTypeStr(int type) {
if (type < 0 || type > TOK_NUM)
return "undefine";
else
return CAST_STRS[type];
}
//返回Tok类型实际字符串
public static String castTokTypeLocalStr(int type) {
if (type < 0 || type > TOK_NUM)
return "undefine";
else
return CAST_LOCAL_STRS[type];
}
}2、创建Token类,作为词法分析的结果,有type属性和value属性,其中只有Num类型和STR类型有真正的value值,其余的只有类型。
package Lex;
/**
* Created by think on 2017/6/8.
*/
public class Token {
public static final Token DESC = new Token(TOK.DESC);
public static final Token SPLIT = new Token(TOK.SPLIT);
public static final Token ARRB= new Token(TOK.ARRB);
public static final Token OBJB = new Token(TOK.OBJB);
public static final Token ARRE = new Token(TOK.ARRE);
public static final Token OBJE = new Token(TOK.OBJE);
public static final Token FALSE = new Token(TOK.FALSE);
public static final Token TRUE = new Token(TOK.TRUE);
public static final Token NULL = new Token(TOK.NULL);
public static final Token BGN = new Token(TOK.BGN);
public static final Token EOF = new Token(TOK.EOF);
// 从TOK类中定义的类型
private Integer type;
// 该tok的值
private String value;
//行号
private int lineNum;
//开始列号
private int beginCol;
//结束列号
private int endCol;
public Token(int type) {
this.type = type;
this.value = null;
}
public Token(int type, String value) {
this.type = type;
this.value = value;
}
public int getType() {
return type;
}
public void setType(int type) {
this.type = type;
}
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
public int getLineNum(){
return lineNum;
}
public void setLineNum(int lineNum) {
this.lineNum = lineNum;
}
public int getBeginCol() {
return beginCol;
}
public int getEndCol() {
return endCol;
}
public void setEndCol(int endCol){
this.endCol=endCol;
}
public void setBeginCol(int beginCol) {
this.beginCol = beginCol;
}
public Object getRealValue(){
Object curValue = null;
switch(this.getType()){
case TOK.TRUE:
curValue = true;
break;
case TOK.FALSE:
curValue = false;
break;
case TOK.NULL:
curValue = null;
break;
case TOK.NUM:
if(value.indexOf('.')>=0){
curValue = Double.parseDouble(value);
}else{
curValue = Integer.parseInt(value);
}
break;
case TOK.STR:
curValue = "\""+this.getValue()+"\"";
break;
}
return curValue;
}
//输出被中括号括起来的token值
public String toString() {
if (this.type != 6&&this.type!=7) {
return "[" + TOK.castTokTypeStr(this.type) + "]";
} else {
return "[" + TOK.castTokTypeStr(this.type) + ":" + this.value
+ "]";
}
}
//输出每个Token实际对应的值
public String toLocalString() {
if (this.type != 6&&this.type!=7) {
return TOK.castTokTypeLocalStr(this.type);
} else if(this.type == 6){
return "\""+this.value + "\"";
}else{
return this.value;
}
}
}3、创建JsonLex类进行词法分析,其中next()用来获取下一个的token,nextchar()用于获取下一个的字符,revertchar()用于回退一个字符,其余进行词法解析。getWriteStr()用来把词法分析的json字符串按照json文件的格式进行输出。
package Lex;
import MyException.UnexpectedException;
/**
* Created by think on 2017/6/8.
*/
public class JsonLex {
// 当前行号
private int lineNum = 0;
//每个Token的开始位置
private int startCol = 0;
// 当前字符游标
private int cur = -1;
// 保存当前要解析的字符串
private String str = null;
// 保存当前要解析的字符串的长度
private int len = 0;
//private int startLine=0;
//private int lastEndCol;
public JsonLex(String str) {
if (str == null)
throw new NullPointerException("词法解析构造函数不能传递null");
this.str = str;
this.len = str.length();
//this.lastEndCol=0;
this.startCol = 0;
this.cur = -1;
this.lineNum = 0;
}
public boolean isLetterUnderline(char c) {
return ((c >= 'a' && c <= 'z') || (c >= 'A' && c <= 'Z') || c == '_');
}
public boolean isNumLetterUnderline(char c) {
return ((c >= 'a' && c <= 'z') || (c >= 'A' && c <= 'Z')
|| (c >= '0' && c <= '9') || c == '_');
}
public boolean isNum(char c) {
return (c >= '0' && c <= '9');
}
public boolean isPunctuation(char c){
return (c==','||c=='.'||c=='-'||c=='('||c==')');
}
public static boolean isSpace(char c) {
return (c == ' ' || c == '\t' || c == '\n'||c=='\r');
}
private void checkEnd() throws UnexpectedException {
if (cur >= len - 1) {
throw generateUnexpectedException("未预期的结束,字符串未结束");
}
}
public UnexpectedException generateUnexpectedException(String str) {
return new UnexpectedException(lineNum,startCol, str);
}
//获取下一个字符
private char nextChar() {
if (cur >= len - 1) {
return 0;
}
cur++;
startCol++;
char c = str.charAt(cur);
if (c == '\n'||c=='\r') {
if(str.charAt(cur+1)!='\n'&&str.charAt(cur+1)!='\r'){
lineNum++;
//lastEndCol=startCol;
startCol = 0;
}
}
return c;
}
//回退一个字符
private int revertChar() {
if (cur <= 0) {
return 0;
}
int rcur = cur--;
char c = str.charAt(rcur);
if (c == '\n') {
lineNum--;
//startCol=lastEndCol;
}
return rcur;
}
//解析获取字符串的值
private String getStrValue(char s) throws UnexpectedException {
int start = cur;
char c;
c=nextChar();
while (c!=0) {
if (isNumLetterUnderline(c)||isSpace(c)||isPunctuation(c)) {
c = nextChar();
} else if (s == c) {
return str.substring(start + 1, cur);
} else {
throw generateUnexpectedException("字符串,需要\"结尾");
}
}
return null;
}
//解析获取数字的值
private String getNumValue() throws UnexpectedException {
int start = cur;
boolean hasPoint=false;
boolean hasE=false;
char c;
while ((c=nextChar())!=0) {
if(isNum(c)){}
else if(c=='.'){
if(hasPoint){
throw generateUnexpectedException("数字错误,多余的.");
}else {
hasPoint=true;
}
}else if(c=='e'){
if (hasE){
throw generateUnexpectedException("数字错误,多余的e");
}else{
hasE=true;
}
}else if (isLetterUnderline(c)||c==' '){
throw generateUnexpectedException("数字错误,未知标识符");
}else {
return str.substring(start, revertChar());
}
}
checkEnd();
return null;
}
//解析获取false true,null类型的Token
private Token getDefToken() throws UnexpectedException {
int start = cur;
char c;
while ((c = nextChar()) != 0) {
if(cur==1245){
System.out.print(1546);
}
if (!isNumLetterUnderline(c)) {
String value = str.substring(start, revertChar());
if ("true".equals(value)) {
return Token.TRUE;
} else if ("false".equals(value)) {
return Token.FALSE;
} else if ("null".equals(value)) {
return Token.NULL;
} else {
throw generateUnexpectedException("错误标识符");
}
}
}
checkEnd();
return null;
}
//解析获取标点符号的Token
public Token parseSymbol(char c) {
switch (c) {
case '[':
return Token.ARRB;
case ']':
return Token.ARRE;
case '{':
return Token.OBJB;
case '}':
return Token.OBJE;
case ',':
return Token.SPLIT;
case ':':
return Token.DESC;
}
return null;
}
//获取下一个Token
public Token next() throws UnexpectedException {
if (lineNum == 0) {
lineNum = 1;
return Token.BGN;
}
char c;
while ((c = nextChar()) != 0) {
if (c == '\"') {
Token tempToken = new Token(TOK.STR);
tempToken.setLineNum(lineNum);
tempToken.setBeginCol(startCol);
tempToken.setValue(getStrValue(c));
tempToken.setEndCol(startCol);
return tempToken;
} else if (isLetterUnderline(c)) {
Token tempToken= getDefToken();
tempToken.setLineNum(lineNum);
tempToken.setBeginCol(startCol-TOK.castTokTypeStr(tempToken.getType()).length());
tempToken.setEndCol(startCol);
return tempToken;
} else if (isNum(c) || c == '-') {
Token tempToken = new Token(TOK.NUM);
tempToken.setLineNum(lineNum);
tempToken.setBeginCol(startCol);
tempToken.setValue(getNumValue());
tempToken.setEndCol(startCol);
return tempToken;
} else if (isSpace(c)) {
continue;
} else {
Token tempToken = parseSymbol(c);
tempToken.setLineNum(lineNum);
tempToken.setBeginCol(startCol);
tempToken.setEndCol(startCol);
return tempToken;
}
}
if (c == 0) {
return Token.EOF;
}
return null;
}
//获取待解析json字符串的标准格式
public String getWriteStr() throws UnexpectedException {
Token tk;
String str = "";
int goTimes = 0;
this.next();
while ((tk = this.next()) != Token.EOF) {
if (tk.toLocalString() == "{" || tk.toLocalString() == "[") {
str = str + tk.toLocalString();
goTimes++;
str = str + "\r" + "\n";
for (int i = 0; i < goTimes * 4; i++) {
str = str + " ";
}
} else if (tk.toLocalString() == ",") {
str = str + tk.toLocalString();
str = str + "\r" + "\n";
for (int i = 0; i < goTimes * 4; i++) {
str = str + " ";
}
} else if (tk.toLocalString() == "}" || tk.toLocalString() == "]") {
goTimes--;
str = str + "\r" + "\n";
for (int i = 0; i < goTimes * 4; i++) {
str = str + " ";
}
str = str + tk.toLocalString();
} else {
str = str + tk.toLocalString();
}
}
return str;
}
}4、创建UnexpectedException进行错误抛出。
package MyException;
/**
* Created by think on 2017/6/8.
*/
public class UnexpectedException extends Exception {
private Integer lineNum = null;
private Integer colNum = null;
private String desc = null;
private Throwable cause = null;
public UnexpectedException() {
super();
}
public UnexpectedException(Integer lineNum, Integer colNum, String message) {
this.colNum = colNum;
this.lineNum = lineNum;
this.desc = message;
}
public String getMessage() {
return "line:" + lineNum + ",column:" + colNum
+ "]" + desc + (cause == null ? "" : cause.toString());
}
public String getLocalMessage() {
return getMessage();
}
public String toString() {
return getMessage();
}
}
在词法分析阶段,可以完成词法错误的识别,如字符串没有用”结束,数字的浮点型和科学计数法行不对,true,false和null的拼写错误等。
二、语法分析阶段
1、根据用LR分析法进行分析,发现Json语法为LR(1)文法。
构造LALR(1)项目自动机得如下图:(这个自己画一遍吧,比较复杂,画的很乱)
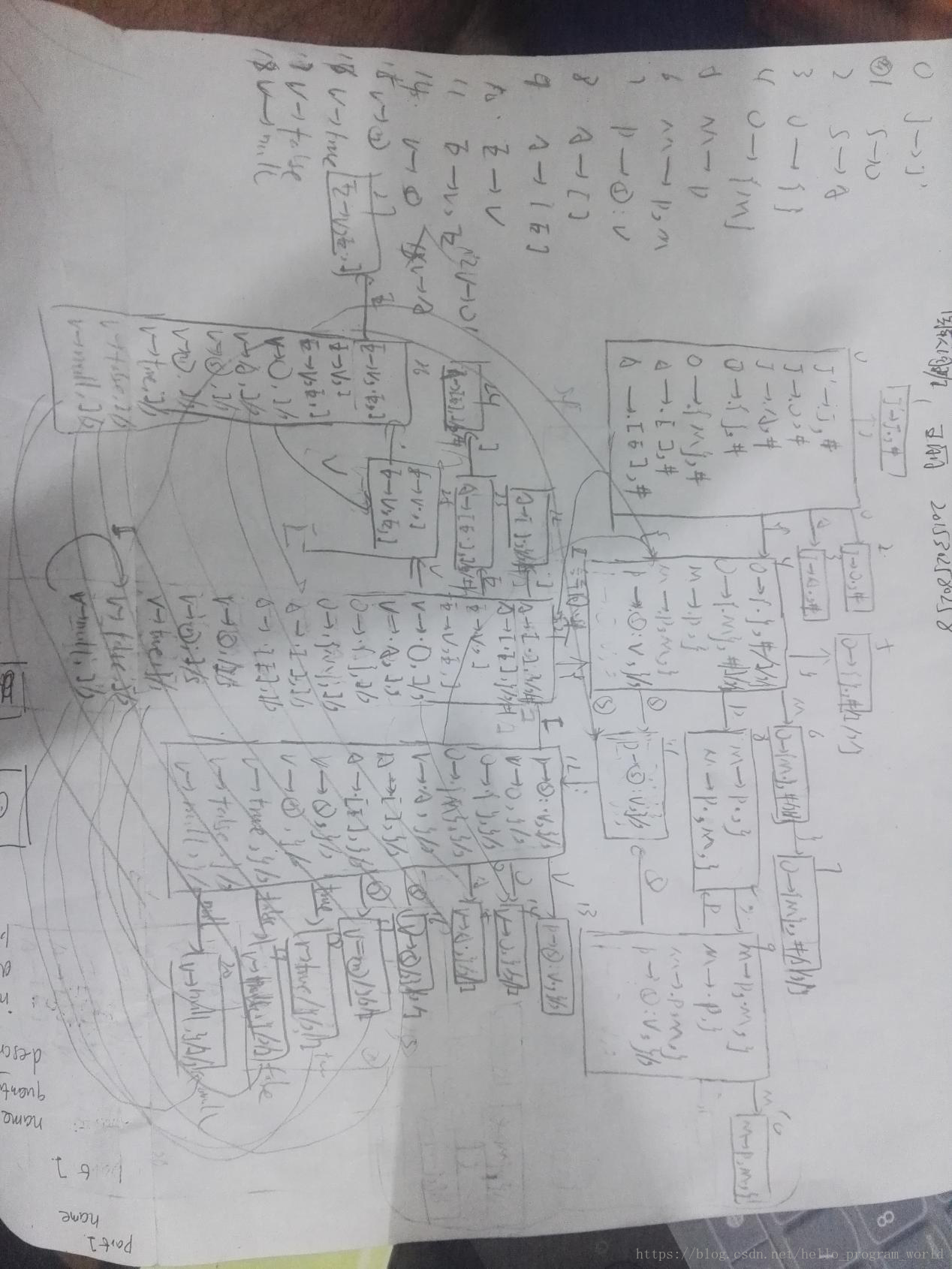
求得LALR(1)分析表
状态 | Action | GoTo | |||||||||||||||||
{ | } | [ | ] | : | , | s | n | # | TRUE | FALSE | null | J | O | M | P | A | E | V | |
0 | s4 |
| s21 |
|
|
|
|
|
|
|
|
| 1 | 2 |
|
| 3 |
|
|
1 |
|
|
|
|
|
|
|
| r0 |
|
|
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
| r1 |
|
|
|
|
|
|
|
|
|
|
3 |
|
|
|
|
|
|
|
| r2 |
|
|
|
|
|
|
|
|
|
|
4 |
| s5 |
|
|
|
| s11 |
|
|
|
|
|
|
| 6 | 8 |
|
|
|
5 |
| r3 |
| r3 |
| r3 |
|
| r3 |
|
|
|
|
|
|
|
|
|
|
6 |
| s7 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
7 |
| r4 |
| r4 |
| r4 |
|
| r4 |
|
|
|
|
|
|
|
|
|
|
8 |
| r5 |
|
|
| s9 |
|
|
|
|
|
|
|
|
|
|
|
|
|
9 |
|
|
|
|
|
| s11 |
|
|
|
|
|
|
| 10 | 8 |
|
|
|
10 |
| r6 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
11 |
|
|
|
| s12 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
12 | s4 |
| s21 |
|
|
| s16 | s17 |
| s18 | s19 | s20 |
| 14 |
|
| 15 |
| 13 |
13 |
| r7 |
|
|
| r7 |
|
|
|
|
|
|
|
|
|
|
|
|
|
14 |
| r12 |
| r12 |
| r12 |
|
|
|
|
|
|
|
|
|
|
|
|
|
15 |
| r13 |
| r13 |
| r13 |
|
|
|
|
|
|
|
|
|
|
|
|
|
16 |
| r14 |
| r14 |
| r14 |
|
|
|
|
|
|
|
|
|
|
|
|
|
17 |
| r15 |
| r15 |
| r15 |
|
|
|
|
|
|
|
|
|
|
|
|
|
18 |
| r16 |
| r16 |
| r16 |
|
|
|
|
|
|
|
|
|
|
|
|
|
19 |
| r17 |
| r17 |
| r17 |
|
|
|
|
|
|
|
|
|
|
|
|
|
20 |
| r18 |
| r18 |
| r18 |
|
|
|
|
|
|
|
|
|
|
|
|
|
21 | S4 |
|
| s22 |
|
| s16 | s17 |
| s18 | s19 | s20 |
| 14 |
|
| 15 | 23 | 25 |
22 |
| r8 |
| r8 |
| r8 |
|
| r8 |
|
|
|
|
|
|
|
|
|
|
23 |
|
|
| s24 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
24 |
| r9 |
| r9 |
| r9 |
|
| r9 |
|
|
|
|
|
|
|
|
|
|
25 |
|
|
| r10 |
| s26 |
|
|
|
|
|
|
|
|
|
|
|
|
|
26 | s4 |
| s21 |
|
|
| s16 | s17 |
| s18 | s19 | s20 |
| 14 |
|
| 15 | 27 | 25 |
27 |
|
|
| r11 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
对test/a/true.json进行分析得
SYMBOL | INPUT | ACTION | GOTO |
# | { | S4 |
|
#{ | s | s11 |
|
#{s | : | s12 |
|
#{s: | [ | s21 |
|
#{s:[ | { | s4 |
|
#{s:[{ | s | s11 |
|
#{s:[{s | : | s12 |
|
#{s:[{s: | s | s16 |
|
#{s:[{s:s | , | r14 | 13 |
#{s:[{s:v | , | r7 | 8 |
#{s:[{p | , | s9 |
|
#{s:[{p, | s | s11 |
|
#{s:[{p,s | : | S12 |
|
#{s:[{p,s: | s | s16 |
|
#{s:[{p,s:s | } | r14 | 13 |
#{s:[{p,s:v | } | r7 | 8 |
#{s:[{p,p | } | r5 | 10 |
#{s:[{p,m | } | r6 | 6 |
#{s:[{m | } | s7 |
|
#{s:[{m} | , | r4 | 14 |
#{s:[o | , | r12 | 25 |
#{s:[v | , | s26 |
|
#{s:[v, | { | S4 |
|
#{s:[v,{ | s | s11 |
|
#{s:[v,{s | : | s12 |
|
#{s:[v,{s: | s | s16 |
|
#{s:[v,{s:s | , | r14 | 13 |
#{s:[v,{s:v | , | r7 | 8 |
#{s:[v,{p | , | s9 |
|
#{s:[v,{p, | s | s11 |
|
#{s:[v,{p,s | : | s12 |
|
#{s:[v,{p,s: | s | s16 |
|
#{s:[v,{p,s:s | } | R14 | 13 |
#{s:[v,{p,s:V | } | r7 |
|
#{s:[v,{p,p | } | r5 | 10 |
#{s:[v,{p,m | } | r6 | 6 |
#{s:[v,{m | } | s7 |
|
#{s:[v,{m} | ] | r4 | 14 |
#{s:[v,o | ] | r12 | 25 |
#{s:[v,v | ] | r10 | 27 |
#{s:[v,E | ] | r11 | 23 |
#{s:[E | ] | s24 |
|
#{s:[E] | } | r9 |
|
#{s:A | } |
|
|
|
|
|
|
2、构建StateClass类,创建inputChar数组,存放分析表的终结符和非终结符,创建stateTable数字,存放分析表的值。创建production二维数组,存放产生式,其中数组的第一个值为左部,第二个值为右部。
package Parser;
import java.util.*;
/**
* Created by think on 2017/6/9.
*/
public class StateClass {
//分析表中的所有终结符和非终结符
public static final ArrayList<String> inputChar =new ArrayList<>();
static {
inputChar.add("{");
inputChar.add("}");
inputChar.add("[");
inputChar.add("]");
inputChar.add(":");
inputChar.add(",");
inputChar.add("s");
inputChar.add("n");
inputChar.add("#");
inputChar.add("true");
inputChar.add("false");
inputChar.add("null");
inputChar.add("J");
inputChar.add("O");
inputChar.add("M");
inputChar.add("P");
inputChar.add("A");
inputChar.add("E");
inputChar.add("V");
}
//分析表
public static final String stateTable[][]={
// { } [ ] : , s n # TRUE FALSE null J O M P A E V
/*0*/ {"S4","","S21","","","","","","","","","","1","2","","","3","",""},
/*1*/ {"","","","","","","","","R0","","","","","","","","","",""},
/*2*/ {"","","","","","","","","R1","","","","","","","","","",""},
/*3*/ {"","","","","","","","","R2","","","","","","","","","",""},
/*4*/ {"","S5","","","","","S11","","","","","","","","6","8","","",""},
/*5*/ {"","R3","","R3","","R3","","","R3","","","","","","","","","",""},
/*6*/ {"","S7","","","","","","","","","","","","","","","","",""},
/*7*/ {"","R4","","R4","","R4","","","R4","","","","","","","","","",""},
/*8*/ {"","R5","","","","S9","","","","","","","","","","","","",""},
/*9*/ {"","","","","","","S11","","","","","","","","10","8","","",""},
/*10*/ {"","R6","","","","","","","","","","","","","","","","",""},
/*11*/ {"","","","","S12","","","","","","","","","","","","","",""},
/*12*/ {"S4","","S21","","","","S16","S17","","S18","S19","S20","","14","","","15","","13"},
/*13*/ {"","R7","","","","R7","","","","","","","","","","","","",""},
/*14*/ {"","R12","","R12","","R12","","","","","","","","","","","","",""},
/*15*/ {"","R13","","R13","","R13","","","","","","","","","","","","",""},
/*16*/ {"","R14","","R14","","R14","","","","","","","","","","","","",""},
/*17*/ {"","R15","","R15","","R15","","","","","","","","","","","","",""},
/*18*/ {"","R16","","R16","","R16","","","","","","","","","","","","",""},
/*19*/ {"","R17","","R17","","R17","","","","","","","","","","","","",""},
/*20*/ {"","R18","","R18","","R18","","","","","","","","","","","","",""},
/*21*/ {"S4","","","S22","","","S16","S17","","S18","S19","S20","","14","","","15","23","25"},
/*22*/ {"","R8","","R8","","R8","","","R8","","","","","","","","","",""},
/*23*/ {"","","","S24","","","","","","","","","","","","","","",""},
/*24*/ {"","R9","","R9","","R9","","","R9","","","","","","","","","",""},
/*25*/ {"","","","R10","","S26","","","","","","","","","","","","",""},
/*26*/ {"S4","","S21","","","","S16","S17","","S18","S19","S20","","14","","","15","27","25"},
/*27*/ {"","","","R11","","","","","","","","","","","","","","",""},
};
//产生式
public static final String[][] production={
{"S","J"},{"J","O"},{"J","A"},{"O","{}"},{"O","{M}"},{"M","P"},{"M","P,M"},
{"P","s:V"},{"A","[]"}, {"A","[E]"},{"E","V"},{"E","V,E"},{"V","O"},{"V","A"},
{"V","s"},{"V","n"}, {"V","t"},{"V","f"},{"V","u"}
};
}
3、创建stateMachine类进行最终的语法分析。Parse()用于解析json字符串的每个token,如果解析成功,则返回true。在analyse()进行每个token的字符串值的解析。
package Parser;
import Lex.JsonLex;
import Lex.TOK;
import Lex.Token;
import MyException.UnexpectedException;
import java.util.Stack;
/**
* Created by think on 2017/6/10.
*/
public class StateMachine {
private JsonLex lex = null;
private Integer status = null;
//符号栈
private Stack<Integer> stateStack=new Stack<>();
//符号栈
private Stack<String> symbolStack=new Stack<>();
public StateMachine(String str){
stateStack.push(0);
symbolStack.push("#");
if (str == null)
throw new NullPointerException("语法解析构造函数不能传递null");
lex = new JsonLex(str);
}
public boolean isNum(char c) {
return (c >= '0' && c <= '9');
}
//解析每个Token的字符串值
public boolean analyse(int lineNum,int colNum,String c) throws UnexpectedException {
status = stateStack.peek();
String tempStr= StateClass.stateTable[status][StateClass.inputChar.indexOf(c)];
if(tempStr==""){
throw new UnexpectedException(lineNum,colNum,"不合法标识符");
}else if (tempStr.charAt(0)=='S'){
stateStack.push(Integer.parseInt(tempStr.substring(1)));
symbolStack.push(c);
return true;
}else if (tempStr.charAt(0)=='R'){
int x=Integer.parseInt(tempStr.substring(1));
int len=StateClass.production[x][1].length();
for(int i=0;i< StateClass.production[x][1].length();i++){
stateStack.pop();
symbolStack.pop();
}
return analyse(lineNum,colNum,StateClass.production[x][0]);
}else if(isNum(tempStr.charAt(0))){
stateStack.push(Integer.parseInt(tempStr));
symbolStack.push(c);
return true;
}else if(tempStr=="acc"){
return true;
}
return false;
}
//解析json字符串
public boolean parse() throws UnexpectedException {
Token tk = null;
tk=lex.next();
tk=lex.next();
Integer oldStatus = status;
while(tk!=Token.EOF){
String analyseStr= TOK.CAST_LOCAL_STRS[tk.getType()];
if(analyse(tk.getLineNum(),tk.getBeginCol(),analyseStr)==false){
System.out.print("未知错误");
return false;
}
String tempC=symbolStack.peek();
if(tempC=="J"||tempC=="O"||tempC=="M"||tempC=="P"||tempC=="A"||tempC=="E"||tempC=="V"){
continue;
}
tk=lex.next();
}
return true;
}
}
三、文件读取和写入
1、创建FileIO类进行文件读取和写入。其中readFile用于读取文件内容并返回字符串,writeFile用于将字符串写入到指定文件中,如果文件不存在,则创建文件。
package FileIO;
/**
* Created by think on 2017/6/12.
*/
import java.io.*;
public class FileIO {
//从文件读取内容
public static String readFile(String path) throws IOException{
BufferedReader in = new BufferedReader(new FileReader( path));
String str="";
int c;
while((c = in.read())!=-1)
{
str=str+(char)c;
}
in.close();
return str;
}
//向文件写入内容
public static void writeFile(String path,String str) throws IOException{
File toFile = new File(path);
if (!toFile.exists()) {
toFile.createNewFile();
}
FileWriter fw = null;
fw = new FileWriter(toFile);
fw.write(str);
fw.close();
}
}四、按路径得到Json元素值
1、创建Json文件,完成将json字符串解析为Map和list格式并完成按路径存取。其中maps栈用于保存所有对象map,lists栈用于保存所有数组,islist栈判断是否为list,keys栈用来保存key。
方法getStructure()用于得到解析后的map和list结构,search()用于根据路径得到元素值,printSearchResult()用于打印提取的结果值。
package Json;
import FileIO.FileIO;
import Lex.JsonLex;
import Lex.TOK;
import Lex.Token;
import MyException.UnexpectedException;
import java.io.IOException;
import java.util.*;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import static java.lang.System.exit;
/**
* Created by think on 2017/6/13.
*/
public class Json {
Stack<Map> maps=new Stack<Map>(); //用来表示多层的json对象
Stack<List> lists=new Stack<List>(); //用来表示多层的list对象
Stack<Boolean> islist=new Stack<Boolean>();//判断是不是list
Stack<String> keys=new Stack<String>(); //用来表示多层的key
String keytmp=null;
Object valuetmp=null;
public JsonLex jl;
Token token = null;
String nowString="";
Object searchValue=null;
int level;//记录提取元素是的层数
public Json(String str)throws UnexpectedException{
jl=new JsonLex(str);
}
//用于得到json字符串解析后得到的map和list结构
public Object getStructure() throws UnexpectedException {
while ((token = jl.next()) != Token.EOF) {
switch (TOK.CAST_STRS[token.getType()]) {
case "OBJB": //如果是{map进栈
maps.push(new HashMap());
islist.push(false);
break;
case"DESC"://如果是:表示这是一个属性建,key进栈
keys.push(nowString);
nowString="";
break;
case "ARRB"://如果是]list进栈
islist.push(true);
lists.push(new ArrayList());
break;
case "SPLIT":
boolean listis=islist.peek();
if(nowString.length()>0)
valuetmp=nowString;
nowString="";
if(!listis){
keytmp=keys.pop();
maps.peek().put(keytmp, valuetmp);
}else
lists.peek().add(valuetmp);
break;
case "ARRE":
islist.pop();
if(nowString.length()>0)
valuetmp=nowString;
nowString="";
lists.peek().add(valuetmp);
valuetmp=lists.pop();
break;
case "OBJE":
islist.pop();
keytmp=keys.pop();
if(nowString.length()>0)
valuetmp=nowString;
nowString="";
maps.peek().put(keytmp, valuetmp);
valuetmp=maps.pop();
break;
case "STR":
nowString=token.getValue();
break;
case "NUM":
nowString=token.getValue();
break;
case "TRUE":
case "FALSE":
case "NULL":
nowString=TOK.CAST_LOCAL_STRS[token.getType()];
break;
}
}
return valuetmp;
}
//查找指定路径的元素
public Object search(Object object,String[] path) throws UnexpectedException{
if(level<path.length) {
if (path[level].matches("(\\w*)(\\[)(0|[1-9][0-9]*)(\\])")) {
int m = path[level].lastIndexOf("[");
int p = path[level].lastIndexOf("]");
String arrayName = path[level].substring(0, m);
int index = Integer.parseInt(path[level].substring(m + 1, p));
if (object instanceof HashMap) {
if (((HashMap) object).get(arrayName) instanceof ArrayList) {
level++;
ArrayList obj=((ArrayList) ((HashMap) object).get(arrayName));
Object obj2=obj.get(index);
searchValue=obj2;
search(searchValue,path);
}
}
}else {
if(object instanceof HashMap){
String kstr=path[level];
searchValue=((HashMap) object).get(kstr);
level++;
search(searchValue,path);
}
}
}
return searchValue;
}
//打印找到的元素值
public void printSearchResult(Object object){
if (object instanceof HashMap) {
System.out.print("对象:" + object);
} else if (object instanceof ArrayList) {
System.out.print("数组:" + object);
}else if (object==null){
System.out.print( object);
}else if(object instanceof String){
if('0'<((String) object).charAt(0)&&((String) object).charAt(0)<='9'){
if(((String) object).indexOf('.')!=-1){
System.out.print("浮点数:" + object);
}else{
System.out.print("数字:" + object);
}
}else if(((String) object).equalsIgnoreCase("true")||((String) object).equalsIgnoreCase("false")) {
System.out.print("布尔值:" + object);
}else if(((String) object).equalsIgnoreCase("null")){
System.out.print("空值:" + object);
} else {
System.out.print("字符串:" + object);
}
}
}
}

















 8876
8876

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









