



一、概述
MySQL作为关系型数据库的核心操作语言,其CRUD(增删改查)四大基础语句构成了数据管理的基石。
INSERT语句作为数据写入的核心指令,通过指定表名和列名与值的对应关系,实现单条或多条数据的精准插入,是数据库初始化和日常数据采集的关键工具,其批量插入功能特别适用于数据迁移和初始化场景。
DELETE和UPDATE语句共同构成了数据修改的双支柱,前者通过WHERE条件精准定位需要删除的记录,结合ORDER BY和LIMIT可实现安全可控的批量删除,有效防范误删风险;后者则通过SET子句动态修改字段值,配合条件筛选能实现从单条记录调整到批量数据更新的各类业务需求,如价格调整、状态变更等日常运维操作。
SELECT语句作为数据检索的中枢神经,其灵活的语法结构支持从简单查询到复杂分析的多层次需求。基础查询通过WHERE条件实现数据过滤,GROUP BY与聚合函数配合可生成统计报表,HAVING子句对分组结果进行二次筛选,ORDER BY确保结果有序呈现,而LIMIT分页机制则是处理海量数据的必备技术。
这四种语句通过事务机制形成完整的数据操作闭环,INSERT确保数据持久化,SELECT提供数据可视化,UPDATE实现数据动态维护,DELETE完成数据生命周期管理。在实际应用中,它们往往需要配合索引优化、事务控制等技术手段,共同构建高效可靠的数据库系统,从电商平台的订单处理到金融系统的交易记录,这些基础语句的熟练运用直接决定了系统数据层的健壮性和响应效率。
二、MySQL增删改查INSERT、DELETE、UPDATE、SELECT四种语句对比表
以下是MySQL四种核心语句的详细对比表格,综合了各语句的功能特点和使用场景:
| 对比维度 | INSERT语句 | DELETE语句 | UPDATE语句 | SELECT语句 |
|---|---|---|---|---|
| 基本功能 | 向表中插入新记录 | 从表中删除记录 | 修改表中现有记录 | 从表中检索数据 |
| 完整语法 | INSERT INTO 表名(列1,列2) VALUES(值1,值2)[,(值3,值4)...] | DELETE FROM 表名 [WHERE条件][ORDER BY列][LIMIT行数] | UPDATE 表名 SET 列1=值1,列2=值2 [WHERE条件][ORDER BY列][LIMIT行数] | SELECT 列1,列2 FROM 表名 [WHERE条件][GROUP BY列][HAVING条件][ORDER BY列][LIMIT行数] |
| 核心子句 | VALUES(必须)、列名列表(可选) | WHERE(强烈建议)、ORDER BY、LIMIT | SET(必须)、WHERE(建议)、ORDER BY、LIMIT | WHERE、GROUP BY、HAVING、ORDER BY、LIMIT |
| 批量操作 | 支持多值列表批量插入 | 通过WHERE条件批量删除 | 通过WHERE条件批量更新 | 天然支持批量查询 |
| 条件过滤 | 无WHERE子句 | WHERE决定删除范围(无WHERE将清空表) | WHERE决定更新范围(无WHERE将更新全表) | WHERE决定查询范围 |
| 排序控制 | 不支持 | 通过ORDER BY指定删除顺序 | 通过ORDER BY指定更新顺序 | 通过ORDER BY指定结果排序 |
| 数量限制 | 隐式由VALUES列表数量决定 | 通过LIMIT控制删除行数 | 通过LIMIT控制更新行数 | 通过LIMIT控制返回行数 |
| 聚合功能 | 不支持 | 不支持 | 不支持 | 支持GROUP BY分组和HAVING过滤 |
| 返回值 | 返回插入行数 | 返回删除行数 | 返回更新行数 | 返回结果集 |
| 安全风险 | 类型/长度校验失败会报错 | 无WHERE条件会清空表 | 无WHERE条件会更新全表 | 大数据量查询可能造成性能问题 |
| 典型场景 | 用户注册、订单创建 | 数据清理、用户注销 | 价格调整、状态变更 | 数据报表、信息展示 |
| 特殊变体 | REPLACE INTO(存在则替换)、INSERT IGNORE(忽略错误) | TRUNCATE TABLE(快速清空表) | JOIN更新(多表关联更新) | 子查询、连接查询、联合查询 |
注:
- 所有语句都支持事务操作,在实际使用中应结合事务机制确保数据一致性。
- INSERT语句的列名列表若省略则必须提供所有列值且顺序与表结构严格一致,而UPDATE和DELETE语句无WHERE条件属于高危操作,生产环境必须谨慎使用。
- SELECT语句作为唯一的数据检索方式,其GROUP BY和HAVING子句可实现复杂的数据分析需求。
三、INSERT语句使用详解
(一)概述
MySQL的INSERT语句是数据操作语言(DML)的核心指令,用于向数据库表中新增数据记录,实现业务数据的持久化存储。其标准语法结构为INSERT INTO 表名 (列1, 列2, ...) VALUES (值1, 值2, ...),通过显式声明列名与值的严格映射关系确保数据完整性。若需为所有列插入数据且值的顺序与表结构完全一致,可省略列名部分。
该语句支持三种进阶操作模式:
- 单行插入:精确指定单条记录的列值组合,适用于关键业务操作如用户注册;
- 批量插入:在单条语句中通过多组
VALUES子句插入多行数据(例如VALUES (...), (...), (...)),显著提升数据导入效率; - 查询插入:通过
INSERT ... SELECT语法将其他表的查询结果直接导入目标表,支持字段位置映射与WHERE条件过滤。
执行时需严格遵守约束规则:
未显式赋值的列必须满足允许NULL或存在默认值的条件,否则触发约束违规错误。针对主键/唯一键冲突,MySQL提供INSERT IGNORE(静默跳过)、REPLACE INTO(替换旧记录)及ON DUPLICATE KEY UPDATE(冲突时更新)等扩展语法以增强灵活性。
作为MySQL数据持久化的核心通道,INSERT语句通过INSERT INTO 表名(列1,列2) VALUES(值1,值2)的基础语法架构,将离散的业务数据转化为结构化记录。其设计精妙之处在于:列名与值的严格映射保障了数据完整性,多值组语法支持批量写入提升效率,而约束校验机制则自动拦截非法数据。在实际开发中,该语句既承担着用户注册、订单生成等常规业务场景的数据落地,也通过INSERT IGNORE等变体处理数据冲突。值得注意的是,其执行效率直接影响系统吞吐量,在高并发场景下往往需要配合事务批处理或延迟插入策略进行优化,这种基础语句的性能表现往往成为衡量数据库架构水平的重要标尺。
(二)语法结构解析
INSERT INTO 表名 (列1,列2) VALUES (值1,值2)[, (值3,值4)...];
(三)逐词解析
1、INSERT INTO:
INSERT:SQL关键字,表示要执行插入操作-
INTO:可选关键字,用于提高可读性,表示数据将插入到哪个表中
2、表名:
-
指定要插入数据的目标表名称
-
例如:
employees、products等 -
表名区分大小写(取决于MySQL服务器配置)
3、(列1,列2):
-
括号内指定要插入数据的列名列表
-
列名之间用逗号分隔
-
可以省略,但必须为表中所有列提供值且顺序一致
4、VALUES:
-
SQL关键字,表示后面跟随的是要插入的值
5、(值1,值2):
-
对应前面列名的值列表
-
值的数量必须与列数匹配
-
值的顺序必须与列顺序一致
6、[, (值3,值4)...]:
-
可选部分,用于批量插入多行数据
-
每组括号表示一行数据
-
每组值必须与列定义匹配
(四)完整示例
-- 向员工表插入单条记录
INSERT INTO employees (
employee_id,
first_name,
last_name,
email,
hire_date,
job_id,
salary
) VALUES (
207,
'张',
'三',
'zhangsan@example.com',
'2023-08-10',
'IT_PROG',
8500.00
);
-- 批量插入产品记录
INSERT INTO products (
product_id,
product_name,
category_id,
price,
stock_quantity
) VALUES
(1001, '无线鼠标', 3, 99.99, 50),
(1002, '机械键盘', 3, 299.99, 30),
(1003, '蓝牙耳机', 4, 199.99, 20);
输出结果:
单条记录插入输出结果:
Query OK, 1 row affected (0.03 sec)
批量插入记录输出结果:
Query OK, 3 rows affected (0.05 sec)
Records: 3 Duplicates: 0 Warnings: 0
输出结果说明
单条插入:
-
返回"Query OK"表示执行成功
-
"1 row affected"表示影响了一行数据
-
括号内是执行时间
批量插入:
-
"3 rows affected"表示成功插入了3条记录
-
"Records: 3"表示处理了3条记录
-
"Duplicates: 0"表示没有重复记录
-
"Warnings: 0"表示没有警告信息
(五)示例解析
1、单行插入示例解析
(1)INSERT INTO employees:指定要向employees表插入数据
(2)列名列表:
-
employee_id:员工ID -
first_name:名 -
last_name:姓 -
email:电子邮箱 -
hire_date:雇佣日期 -
job_id:职位ID -
salary:薪资
(3)VALUES子句:
-
207:员工ID值 -
'张':名字符串值 -
'三':姓字符串值 -
'zhangsan@example.com':邮箱字符串值 -
'2023-08-10':日期字符串值 -
'IT_PROG':职位ID字符串值 -
8500.00:薪资数值
2、批量插入示例解析
(1)INSERT INTO products:指定要向products表插入数据
(2)列名列表:
-
product_id:产品ID -
product_name:产品名称 -
category_id:类别ID -
price:价格 -
stock_quantity:库存数量
(3)三组VALUES值:
-
第一行:无线鼠标产品信息
-
第二行:机械键盘产品信息
-
第三行:蓝牙耳机产品信息
(六)关键注意事项
列与值匹配:
-
列数和值数必须相同
-
数据类型必须兼容(字符串用引号,数字不用)
自增列处理:
-
对于自增主键,可以指定NULL或0让MySQL自动生成值
-
也可以完全省略自增列
默认值:
-
如果列有默认值且插入时未指定,将使用默认值
-
可以使用DEFAULT关键字显式指定使用默认值
NULL值:
-
允许NULL的列可以显式插入NULL
-
不允许NULL的列必须提供有效值
性能考虑:
-
批量插入比多次单行插入性能更好
-
大容量插入考虑暂时禁用索引
四、DELETE语句使用详解
(一)概述
MySQL的DELETE语句是数据操作语言(DML)的核心指令,用于从数据库表中删除符合条件的记录行,实现数据的清理与生命周期管理。其标准语法结构为DELETE FROM 表名 [WHERE 条件],通过WHERE子句精确限定删除范围,若省略条件将清空整表数据——这一特性使其成为需要谨慎使用的高风险操作。
该语句支持三种典型应用场景:
- 精确删除:通过主键或唯一键定位单条记录(如
DELETE FROM users WHERE user_id=1001),适用于敏感数据擦除; - 条件批量删除:结合复杂逻辑表达式(如
WHERE create_time < '2020-01-01' AND status='inactive'),实现过期数据清理; - 关联删除:通过子查询或JOIN语法(如
DELETE t1 FROM table1 t1 JOIN table2 t2 ON...),支持跨表依赖数据的级联处理。
执行时需特别注意约束规则:
若表存在外键引用,需根据ON DELETE规则触发级联删除或阻止操作;事务环境下建议先SELECT验证待删数据,再执行删除以避免误操作。针对性能优化,大批量删除应采用分批次提交或临时表策略,避免长事务阻塞。
作为数据维度的终结者,DELETE语句通过WHERE条件的精确控制,在数据归档、合规清理等场景中发挥关键作用。其设计哲学体现在:条件表达式提供精准操作靶向,事务机制保障操作原子性,而外键约束则维护数据关联纯洁性。实际应用中,该语句既用于常规日志轮转、用户注销等业务场景,也通过LIMIT子句实现可控的渐进式删除。需要强调的是,其执行效率直接影响存储回收速度和系统负载,在OLTP系统中通常需要配合低峰期执行计划,这种基础语句的合理使用程度直接反映数据库运维的成熟度水平。
(二)语法结构解析
DELETE FROM 表名 [WHERE 条件] [ORDER BY 列] [LIMIT 行数];
(三)逐词解析
1、DELETE FROM:
-
DELETE:SQL关键字,表示要执行删除操作 -
FROM:指定要从哪个表中删除数据
2、表名:
-
指定要删除数据的目标表名称
-
例如:
employees、orders等 -
表名区分大小写(取决于MySQL服务器配置)
3、[WHERE 条件]:
-
可选子句,用于指定删除哪些行的条件
-
如果不指定WHERE条件,将删除表中的所有行
-
条件可以使用比较运算符(=, <>, >, <等)和逻辑运算符(AND, OR, NOT)
4、[ORDER BY 列]:
-
可选子句,指定删除行的顺序
-
通常与LIMIT一起使用,控制哪些行先被删除
-
可以指定ASC(升序,默认)或DESC(降序)
5、[LIMIT 行数]:
-
可选子句,限制要删除的最大行数
-
对于大表删除操作,使用LIMIT可以分批删除
-
可以指定偏移量:
LIMIT 偏移量, 行数
(四)完整示例
-- 删除特定员工记录
DELETE FROM employees
WHERE employee_id = 207;
-- 批量删除过期订单(按创建时间排序,每次删除100条)
DELETE FROM orders
WHERE status = 'expired'
AND created_at < DATE_SUB(NOW(), INTERVAL 1 YEAR)
ORDER BY created_at
LIMIT 100;
-- 删除测试用户(无WHERE条件会清空整个表)
DELETE FROM test_users;
输出结果:
单行删除输出结果:
Query OK, 1 row affected (0.02 sec)
批量删除输出结果:
Query OK, 100 rows affected (0.15 sec)
清空表输出结果:
Query OK, 3245 rows affected (1.23 sec)
输出结果说明
单行删除:
-
"1 row affected"表示成功删除了1条记录
-
执行时间显示为0.02秒
批量删除:
-
"100 rows affected"表示成功删除了100条过期订单
-
执行时间显示为0.15秒
全表删除:
-
"3245 rows affected"表示清空了整个测试用户表
-
执行时间显示为1.23秒,因数据量较大而耗时较长
(五)示例解析
单行删除示例解析
-
DELETE FROM employees:指定要从employees表删除数据 -
WHERE employee_id = 207:只删除employee_id等于207的记录 -
执行后:仅删除匹配条件的单行数据
批量删除示例解析
-
DELETE FROM orders:指定要从orders表删除数据 -
WHERE status = 'expired':只删除状态为'expired'的订单 -
AND created_at < DATE_SUB(NOW(), INTERVAL 1 YEAR):且创建时间超过1年 -
ORDER BY created_at:按创建时间排序(先删除最早的记录) -
LIMIT 100:每次最多删除100条记录 -
执行后:批量删除符合条件的记录,每次最多100条
清空表示例解析
-
DELETE FROM test_users:指定要从test_users表删除数据 -
无WHERE条件:删除表中的所有行(相当于清空表)
-
执行后:test_users表变为空表
(六)关键注意事项
WHERE条件重要性:
-
没有WHERE条件会删除整个表的所有数据
-
删除前务必确认WHERE条件的准确性
外键约束:
-
如果表有外键约束,删除可能被阻止
-
可以使用
ON DELETE CASCADE自动删除相关记录
性能考虑:
-
大表删除操作可能很耗时
-
使用LIMIT分批删除可以减少锁表时间
事务处理:
-
重要删除操作应在事务中进行
-
可以先SELECT确认要删除的记录
与TRUNCATE区别:
-
TRUNCATE TABLE更快但不记录日志
-
DELETE可以带条件,TRUNCATE只能清空整个表
恢复数据:
-
DELETE操作可以回滚(在事务中)
-
删除前建议备份重要数据
自增列处理:
-
DELETE不会重置自增计数器
-
如需重置,需使用TRUNCATE或ALTER TABLE
五、UPDATE语句使用详解
(一)概述
MySQL的UPDATE语句是数据操作语言(DML)的核心指令,用于修改数据库表中已存在的记录数据,实现业务数据的动态更新。其标准语法结构为UPDATE 表名 SET 列1=值1, 列2=值2 [WHERE 条件],通过SET子句指定修改内容,WHERE子句精确限定更新范围——若省略条件将更新全表数据,这一特性使其成为需要严格权限控制的高危操作。
该语句支持四种典型应用模式:
- 精确更新:通过主键定位单条记录(如
UPDATE products SET price=299 WHERE id=1005),适用于商品调价等精准操作; - 条件批量更新:结合逻辑表达式(如
UPDATE orders SET status='shipped' WHERE create_date<'2025-08-01'),实现批量状态流转; - 计算更新:支持表达式运算(如
UPDATE accounts SET balance=balance-100),适用于金融扣款等场景; - 关联更新:通过JOIN语法(如
UPDATE t1 JOIN t2 ON... SET t1.col=t2.col)实现跨表数据同步。
执行时需特别注意约束规则:
修改后的数据必须符合列类型定义和约束条件(如NOT NULL、UNIQUE等),否则触发错误。针对并发更新冲突,MySQL提供行级锁机制保证原子性,事务环境下建议配合SELECT...FOR UPDATE实现悲观锁控制。性能优化方面,大批量更新建议采用索引条件、分批次提交或临时表策略。
作为数据动态维护的核心工具,UPDATE语句通过SET-WHERE的二元结构,在用户资料修改、库存调整等场景中发挥关键作用。其设计精髓体现在:SET子句支持表达式计算提供灵活更新能力,WHERE条件实现精准数据定位,而事务机制确保操作可靠性。实际应用中,该语句既用于常规业务数据维护,也通过LIMIT子句实现可控的渐进式更新。需要强调的是,其执行效率直接影响系统响应速度,在OLTP系统中通常需要建立有效索引并避免全表更新,这种基础语句的优化水平直接体现数据库架构师的技术功底。
(二)语法结构解析
UPDATE 表名 SET 列1=值1, 列2=值2 [WHERE 条件] [ORDER BY 列] [LIMIT 行数];
(三)逐词解析
1、UPDATE:
-
SQL关键字,表示要执行更新操作
-
必须作为语句的第一个词出现
2、表名:
-
指定要更新数据的目标表名称
-
可以是单个表名,如
employees -
也可以是多表更新时的多个表名(用逗号分隔)
3、SET:
-
SQL关键字,表示后面跟随的是要更新的列和值
-
必须出现在表名之后
4、列1=值1, 列2=值2:
-
指定要更新的列及其新值
-
可以更新一个或多个列
-
等号左边是列名,右边是新值或表达式
-
多个列更新用逗号分隔
5、[WHERE 条件]:
-
可选子句,指定更新哪些行的条件
-
如果不指定WHERE条件,将更新表中的所有行
-
条件可以使用比较运算符和逻辑运算符
6、[ORDER BY 列]:
-
可选子句,指定更新行的顺序
-
通常与LIMIT一起使用,控制哪些行先被更新
-
可以指定ASC(升序,默认)或DESC(降序)
7、[LIMIT 行数]:
-
可选子句,限制要更新的最大行数
-
对于大表更新操作,使用LIMIT可以分批更新
-
可以指定偏移量:
LIMIT 偏移量, 行数
(四)完整示例
-- 更新特定员工薪资
UPDATE employees
SET salary = salary * 1.1,
last_raise_date = CURRENT_DATE()
WHERE employee_id = 207;
-- 批量更新产品价格(按价格排序,每次更新50条)
UPDATE products
SET price = ROUND(price * 0.9, 2),
discount_flag = 1
WHERE category_id = 3
AND stock_quantity > 10
ORDER BY price DESC
LIMIT 50;
-- 更新所有用户状态(无WHERE条件会更新整个表)
UPDATE users
SET last_login_ip = NULL,
login_count = 0;
输出结果:
更新特定员工薪资输出结果:
Query OK, 1 row affected (0.02 sec)
Rows matched: 1 Changed: 1 Warnings: 0
批量更新产品价格输出结果:
Query OK, 50 rows affected (0.08 sec)
Rows matched: 50 Changed: 50 Warnings: 0
更新所有用户状态输出结果:
Query OK, 1024 rows affected (0.25 sec)
Rows matched: 1024 Changed: 1024 Warnings: 0
输出结果说明
单行更新:
-
"1 row affected"表示成功更新了1条记录
-
"Rows matched: 1"表示找到1条匹配记录
-
"Changed: 1"表示实际修改了1条记录
-
执行时间显示为0.02秒
批量更新:
-
"50 rows affected"表示成功更新了50条产品记录
-
"Rows matched: 50"表示找到50条匹配记录
-
"Changed: 50"表示实际修改了50条记录
-
执行时间显示为0.08秒
全表更新:
-
"1024 rows affected"表示更新了整个用户表的1024条记录
-
"Rows matched: 1024"表示找到1024条匹配记录
-
"Changed: 1024"表示实际修改了1024条记录
-
执行时间显示为0.25秒
(五)示例解析
单行更新示例解析
-
UPDATE employees:指定要更新employees表 -
SET salary = salary * 1.1:将薪资提高10% -
last_raise_date = CURRENT_DATE():将最后加薪日期设为今天 -
WHERE employee_id = 207:只更新employee_id为207的记录 -
执行后:仅更新匹配条件的单行数据
批量更新示例解析
-
UPDATE products:指定要更新products表 -
SET price = ROUND(price * 0.9, 2):将价格打9折并四舍五入到2位小数 -
discount_flag = 1:设置折扣标志为1 -
WHERE category_id = 3:只更新类别ID为3的产品 -
AND stock_quantity > 10:且库存数量大于10 -
ORDER BY price DESC:按价格降序排序(先更新价格高的) -
LIMIT 50:每次最多更新50条记录 -
执行后:批量更新符合条件的记录,每次最多50条
全表更新示例解析
-
UPDATE users:指定要更新users表 -
SET last_login_ip = NULL:将所有用户的最后登录IP设为NULL -
login_count = 0:将所有用户的登录次数重置为0 -
无WHERE条件:更新表中的所有行
-
执行后:users表中所有记录都被更新
(六)关键注意事项
WHERE条件重要性:
-
没有WHERE条件会更新整个表的所有数据
-
更新前务必确认WHERE条件的准确性
多表更新:
-
可以同时更新多个表
-
需要使用JOIN语法指定表间关系
表达式使用:
-
SET子句中可以使用各种表达式和函数
-
可以引用列的当前值进行计算
性能考虑:
-
大表更新操作可能很耗时
-
使用LIMIT分批更新可以减少锁表时间
事务处理:
-
重要更新操作应在事务中进行
-
可以先SELECT确认要更新的记录
外键约束:
-
更新主键或外键列时需注意约束关系
-
可以使用
ON UPDATE CASCADE自动更新相关记录
自增列处理:
-
通常不应更新自增列的值
-
如需重置自增计数器,需使用ALTER TABLE
六、SELECT语句使用详解
(一)概述
MySQL的SELECT语句是数据查询语言(DQL)的核心指令,作为数据库操作中使用频率最高的命令(占比超过60%),承担着从数据库中检索数据的核心职能。其标准语法结构为SELECT 列名 FROM 表名 [WHERE 条件] [GROUP BY 分组] [HAVING 过滤] [ORDER BY 排序] [LIMIT 限制],通过模块化子句实现多维度数据提取,其中WHERE条件缺省时将返回全表数据——这一特性要求开发人员必须建立明确的查询边界意识。
SELECT语句的四大能力层级
1、基础查询
-
精确字段选择:
SELECT id,name FROM employees(避免SELECT *的性能陷阱) -
条件过滤:
WHERE支持BETWEEN、IN、LIKE等运算符,配合AND/OR构建复杂逻辑 -
结果排序:
ORDER BY salary DESC实现降序排列,支持多字段组合排序
2、高级特性
-
聚合计算:
GROUP BY配合COUNT()、SUM()等函数实现数据统计 -
结果筛选:
HAVING对聚合结果进行二次过滤(与WHERE作用于原始数据的区别) -
分页控制:
LIMIT 10 OFFSET 20实现高效分页查询
3、多表操作
-
连接查询:
INNER/LEFT JOIN实现表关联,需特别注意N+1查询问题 -
子查询:嵌套SELECT作为条件或临时数据集,存在性能优化空间
-
集合运算:
UNION合并结果集时自动去重(UNION ALL保留重复项)
4、 性能优化
-
索引命中:EXPLAIN分析执行计划,避免全表扫描
-
查询重构:将复杂查询分解为临时表或视图
-
缓存利用:合理使用SQL_CACHE指令和查询结果缓存
工程实践要点
-
在OLTP系统中,单条SELECT语句执行时间应控制在100ms以内
-
大数据量查询必须配合
LIMIT使用,避免内存溢出 -
敏感字段查询需实现数据脱敏,如
SELECT CONCAT(LEFT(id_card,3),'****') -
分布式环境下需注意跨分片查询的协调成本
作为数据库交互的"万用钥匙",SELECT语句通过其模块化语法结构,在数据报表生成、业务分析看板等场景中展现强大威力。其设计哲学体现在:投影(SELECT子句)与选择(WHERE子句)的分离实现关注点分离,关系代数理论转化为直观的SQL语法。需要特别强调的是,其执行效率直接影响系统整体性能,在微服务架构中往往成为接口响应时间的决定性因素,这种基础语句的优化水平直接体现开发人员的数据库功底。
(二)语法结构解析
SELECT 列1,列2 FROM 表名 [WHERE 条件] [GROUP BY 列] [HAVING 条件] [ORDER BY 列] [LIMIT 行数];
(三)逐词解析
1、SELECT:
-
SQL关键字,表示要执行查询操作
-
必须作为语句的第一个词出现
2、列1,列2:
-
指定要查询的列名列表
-
可以使用
*表示所有列 -
可以使用表达式、函数和别名
-
多个列用逗号分隔
3、FROM:
-
SQL关键字,表示后面跟随的是数据来源的表
-
必须出现在SELECT子句之后
4、表名:
-
指定要查询的数据来源表
-
可以是单个表或多个表(使用JOIN连接)
-
可以使用表别名简化引用
5、[WHERE 条件]:
-
可选子句,指定筛选行的条件
-
条件可以使用比较运算符和逻辑运算符
-
支持子查询作为条件
6、[GROUP BY 列]:
-
可选子句,用于对结果集进行分组
-
通常与聚合函数一起使用
-
可以指定一个或多个分组列
7、[HAVING 条件]:
-
可选子句,对分组后的结果进行筛选
-
类似于WHERE,但作用于分组后的数据
-
可以使用聚合函数作为条件
8、[ORDER BY 列]:
-
可选子句,指定结果集的排序方式
-
可以指定ASC(升序,默认)或DESC(降序)
-
可以按多个列排序,优先级从左到右
9、[LIMIT 行数]:
-
可选子句,限制返回的行数
-
可以指定偏移量:
LIMIT 偏移量, 行数 -
常用于分页查询
(四)完整示例
-- 基本查询:获取特定员工信息
SELECT
employee_id,
CONCAT(first_name, ' ', last_name) AS full_name,
salary,
department_name
FROM
employees
JOIN departments ON employees.department_id = departments.department_id
WHERE
salary > 5000
AND hire_date > '2020-01-01';
-- 分组统计:按部门统计平均薪资
SELECT
department_id,
department_name,
COUNT(*) AS employee_count,
AVG(salary) AS avg_salary,
MAX(salary) AS max_salary
FROM
employees
JOIN departments USING (department_id)
GROUP BY
department_id, department_name
HAVING
AVG(salary) > 6000
ORDER BY
avg_salary DESC
LIMIT 5;
-- 分页查询:获取第2页的产品数据(每页10条)
SELECT
product_id,
product_name,
price,
category_name
FROM
products
JOIN categories USING (category_id)
ORDER BY
product_id
LIMIT 10, 10;
输出结果:
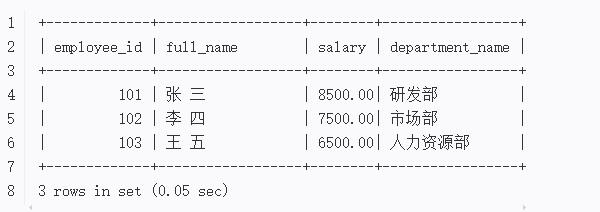
基本查询:获取特定员工信息输出结果:
分组统计:按部门统计平均薪资输出结果:

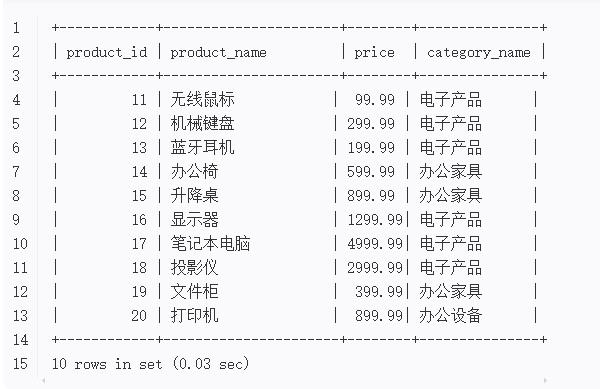
分页查询:获取第2页的产品数据输出结果:
输出结果说明
基本查询:
-
返回符合条件的员工信息,包含员工ID、全名、薪资和部门名称
-
结果以表格形式显示,包含列名和数据行
-
底部显示查询到的行数和执行时间
分组统计:
-
按部门分组计算员工数量、平均薪资和最高薪资
-
使用HAVING子句过滤平均薪资大于6000的部门
-
结果按平均薪资降序排列并限制为5条记录
分页查询:
-
使用LIMIT 10,10实现分页,跳过前10条记录,获取接下来的10条
-
结果按产品ID排序,包含产品ID、名称、价格和分类名称
-
底部显示查询到的行数和执行时间
(五)示例解析
基本查询示例解析
SELECT子句:
-
employee_id:员工ID -
CONCAT(first_name, ' ', last_name) AS full_name:拼接姓名为全名并设置别名 -
salary:薪资 -
department_name:部门名称
FROM子句:
-
从employees表查询
-
使用JOIN连接departments表
WHERE子句:
-
salary > 5000:筛选薪资大于5000的员工 -
hire_date > '2020-01-01':筛选2020年后入职的员工
分组统计示例解析
SELECT子句:
-
包含部门ID和名称
-
使用COUNT统计员工数
-
使用AVG计算平均薪资
-
使用MAX获取最高薪资
GROUP BY子句:
-
按部门ID和名称分组
HAVING子句:
-
筛选平均薪资大于6000的部门
ORDER BY子句:
-
按平均薪资降序排序
LIMIT子句:
-
只返回前5条记录
分页查询示例解析
LIMIT 10, 10:
-
跳过前10条记录(第1页)
-
返回接下来的10条记录(第2页)
(六)查询数据时可用DISTINCT关键字去除结果中的重复记录
1、基础语法
SELECT DISTINCT column_name FROM table_name;
这种方式会返回指定列的唯一值列表。
2、多列去重
SELECT DISTINCT column1, column2 FROM table_name;
只有当多列的值完全一致时才会被视为重复记录。
3、注意事项
- 对NULL值的处理:所有NULL值会被视为相同值归为一组
- 性能影响:大数据量时效率较低,建议配合LIMIT使用
- 与GROUP BY的区别:DISTINCT只去重不计算聚合值
4、替代方案
- GROUP BY:适合需要同时分组统计的场景
- ROW_NUMBER():MySQL 8.0+支持,适合保留特定记录(如最新数据)
- UNION:天然具有去重特性
5、实际应用示例
查询员工表中不重复的部门编号:
SELECT DISTINCT dept_no FROM employees;
查询不同性别和部门的组合:
SELECT DISTINCT gender, dept_no FROM employees;
(七)关键注意事项
执行顺序:
-
FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY → LIMIT
-
理解执行顺序有助于编写高效查询
性能优化:
-
避免使用
SELECT *,只查询需要的列 -
为常用查询条件创建索引
-
大表查询考虑使用LIMIT分批处理
JOIN操作:
-
明确指定JOIN条件避免笛卡尔积
-
了解INNER JOIN、LEFT JOIN等区别
子查询:
-
可以在SELECT、FROM、WHERE等子句中使用子查询
-
复杂的子查询可以考虑使用临时表或CTE
NULL值处理:
-
使用IS NULL/IS NOT NULL判断NULL值
-
聚合函数通常忽略NULL值
别名使用:
-
列别名提高可读性
-
表别名简化复杂查询
UNION操作:
-
可以合并多个SELECT语句的结果
-
要求列数和数据类型匹配
七、WHERE子句比较运算符在增删改查四种语句中的使用
(一)常用WHERE子句比较运算符分类表
|
类别 |
运算符 |
说明 |
示例 |
注意事项 |
|---|---|---|---|---|
|
基础比较 |
|
等于 |
|
NULL需用IS NULL |
|
|
不等于 |
| ||
|
|
大于 |
| ||
|
|
小于 |
| ||
|
|
大于等于 |
| ||
|
|
小于等于 |
| ||
|
特殊比较 |
|
NULL安全等于 |
|
可比较NULL值 |
|
|
是NULL值 |
| ||
|
|
非NULL值 |
| ||
|
|
布尔真值 |
| ||
|
|
布尔假值 |
| ||
|
范围比较 |
|
区间包含 |
|
闭区间 |
|
|
区间排除 |
| ||
|
|
值列表匹配 |
| ||
|
|
值列表排除 |
| ||
|
字符串处理 |
|
模式匹配 |
|
|
|
|
反向匹配 |
| ||
|
|
正则匹配 |
| ||
|
|
发音相似 |
|
仅英文 | |
|
JSON处理 |
|
JSON路径提取 |
|
返回带引号值 |
|
|
JSON裸值提取 |
| ||
|
空间数据 |
|
几何包含 |
| |
|
|
精确空间包含 |
| ||
|
子查询 |
|
存在性判断 |
| |
|
|
任意满足 |
| ||
|
|
全部满足 |
| ||
|
位运算 |
|
按位与 |
| |
|
` |
` |
按位或 |
`WHERE permissions | |
|
全文检索 |
|
全文搜索 |
|
需建全文索引 |
(二)增删改查四种语句的WHERE子句运算符适用性对照表
| 语句类型 | WHERE子句位置 | 运算符可用性说明 | 典型应用场景示例 |
|---|---|---|---|
| SELECT | 直接使用 | ⭐️ 所有运算符均可使用 | SELECT * FROM users WHERE age > 18 AND name LIKE '张%' |
| DELETE | 直接使用 | ⭐️ 所有运算符均可使用 | DELETE FROM logs WHERE create_time < '2025-01-01' |
| UPDATE | 直接使用 | ⭐️ 所有运算符均可使用 | UPDATE products SET stock=0 WHERE status='discontinued' |
| 标准INSERT | ❌ 无WHERE子句 | ➖ 不适用 | INSERT INTO users VALUES (1, '张三') |
| INSERT...SELECT | 嵌套SELECT语句中使用 | ⭐️ 所有运算符可在嵌套SELECT的WHERE中使用 | INSERT INTO vip_users SELECT * FROM users WHERE score >= 90 |
(三)跨语句通用运算符简单示例
-- 1. 比较运算符通用示例
UPDATE employees SET salary=8000 WHERE dept_id = 10;
DELETE FROM temp_data WHERE timestamp <= NOW() - INTERVAL 7 DAY;
-- 2. 范围运算符通用示例
SELECT * FROM orders WHERE amount BETWEEN 100 AND 500;
DELETE FROM sessions WHERE last_activity NOT BETWEEN '2025-08-01' AND '2025-08-10';
-- 3. 空值判断通用示例
UPDATE contacts SET flag=1 WHERE mobile IS NOT NULL;
SELECT * FROM applications WHERE attachment_url IS NULL;
-- 4. 模式匹配通用示例
DELETE FROM spam_messages WHERE content LIKE '%广告%';
UPDATE products SET category='other' WHERE name NOT LIKE 'A-%';
-- 5. 子查询通用示例
UPDATE inventory
SET restock_flag=1
WHERE item_id IN (SELECT item_id FROM sales WHERE qty > 100);
DELETE FROM user_devices
WHERE user_id = ANY (SELECT id FROM users WHERE banned=1);
(四)注意事项
-
性能影响:DELETE/UPDATE中的WHERE条件应特别关注索引使用情况
-
安全风险:生产环境执行DELETE/UPDATE前建议先用SELECT验证条件
-
事务控制:修改语句建议在事务中执行(BEGIN...COMMIT)
-
语法差异:部分高级运算符(如JSON操作符)需MySQL 5.7+版本支持
所有WHERE子句运算符在SELECT/DELETE/UPDATE和INSERT...SELECT中的行为完全一致,这是SQL标准的核心特性之一。

















 4403
4403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









