



JStorm是一个类似Hadoop MapReduce的系统,不同的是JStorm是一套基于流水线的消息处理机制,是阿里基于Storm优化的版本,和Storm一样是一个分布式实时计算的系统,从开发角度来说,JStorm所有的概念和Storm都相同,所有的编程代码一行不用改也可以直接放到JStorm运行,也可以做一些优化,JStorm比Storm更稳定、更强大、更快,去掉了很多耗费资源的代码,在实际生产中表现更是非常突出,所以对于使用Storm计算的应用场景来说升级到JStorm更是简单、低成本,以下使用3台服务器说一下JStorm集群的部署流程
部署所需:
- JDK、
- zookeeper
- jstorm
JDK及zookeeper安装完成后安装jstorm
tar –xf /app/jstorm/jstorm-2.2.1.tar.gz
修改storm.yaml
vim /app/jstorm-2.2.1/conf/storm.yaml
配置zookeeper节点

配置nimbus节点
![]()
配置storm.local.dir,表示jstorm的临时数据存放目录

设置supervisor节点执行worker使用的端口列表,默认为68xx,而storm是67xx
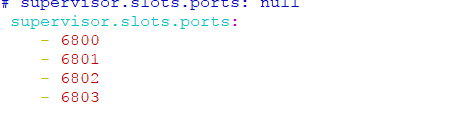
将所有配置文件拷贝至server2及server3
在当前机器,一般是nimbus,也就是提交jar包的机器上执行如下命令:
mkdir ~/.jstorm
cp /app/jstorm-2.2.1/conf/storm.yaml ~/.jstorm/
配置storm ui管理界面
安装tomcat
拷贝jstorm.war至webapps下启动tomcat
启动nimbus
cd /app/jstorm-2.2.1/
nohup bin/jstorm nimbus &
启动supervisor
nohup bin/jstorm supervisor &

















 3206
3206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









