




 本文深入探讨微服务架构下Hystrix的作用,包括断路器、线程隔离和服务保护机制,通过示例讲解如何使用Spring Cloud Hystrix进行服务容错保护,涵盖命令请求、服务降级、异常处理、请求缓存和合并等内容。
本文深入探讨微服务架构下Hystrix的作用,包括断路器、线程隔离和服务保护机制,通过示例讲解如何使用Spring Cloud Hystrix进行服务容错保护,涵盖命令请求、服务降级、异常处理、请求缓存和合并等内容。
前言:
在微服务架构中,我们将系统拆分成了很多服务单元,各单元的应用间通过服务注册与订阅的方式相互依赖。
由于每个单元都在不同的进程中运行,依赖通过远程调用的方式执行,这样就有可能因为网络原因或者是依赖服务(被调用方)自身问题出现调用故障或延迟,而这些问题会直接导致调用方的对外服务也出现延迟,若此时调用方的请求不断增加,最后就会因为等待出现故障的依赖方(被调用方)响应形成任务积压,最终导致自身服务的瘫痪(调用方)。
在微服务架构中,存在这那么多的服务单元,若一个单元出现故障,就很容易因依赖关系而引发故障的蔓延,最终导致整个系统的瘫痪,这样的架构相比传统架构更加不稳定。为了解决这样的问题,产生了断路器等一系列的服务保护机制。
在分布式架构中,当某个服务单元发生故障之后,通过断路器的故障监控,向调用方返回一个错误响应,而不是长时间的等待。这样就不会使得线程因调用故障服务被长时间占用不释放,避免的故障在分布式系统中的蔓延。
Spring Cloud Hystrix就实现了断路器、线程隔离等一系列服务保护功能。通过控制那些访问远程系统、服务和第三方库的节点,从而对延迟和故障提供更强大的容错能力。
Hystrix具备服务降级、服务熔断、线程和信号隔离、请求缓存、请求合并以及服务监控等强大功能。
一、快速入门
通过一个简单的示例对Spring Cloud Hystrix进行学习和使用。请参考:Spring Cloud (五)、服务容错保护Hystrix(入门)
--------------------------------------------------原理分析----------------------------------------------------
二、工作流程
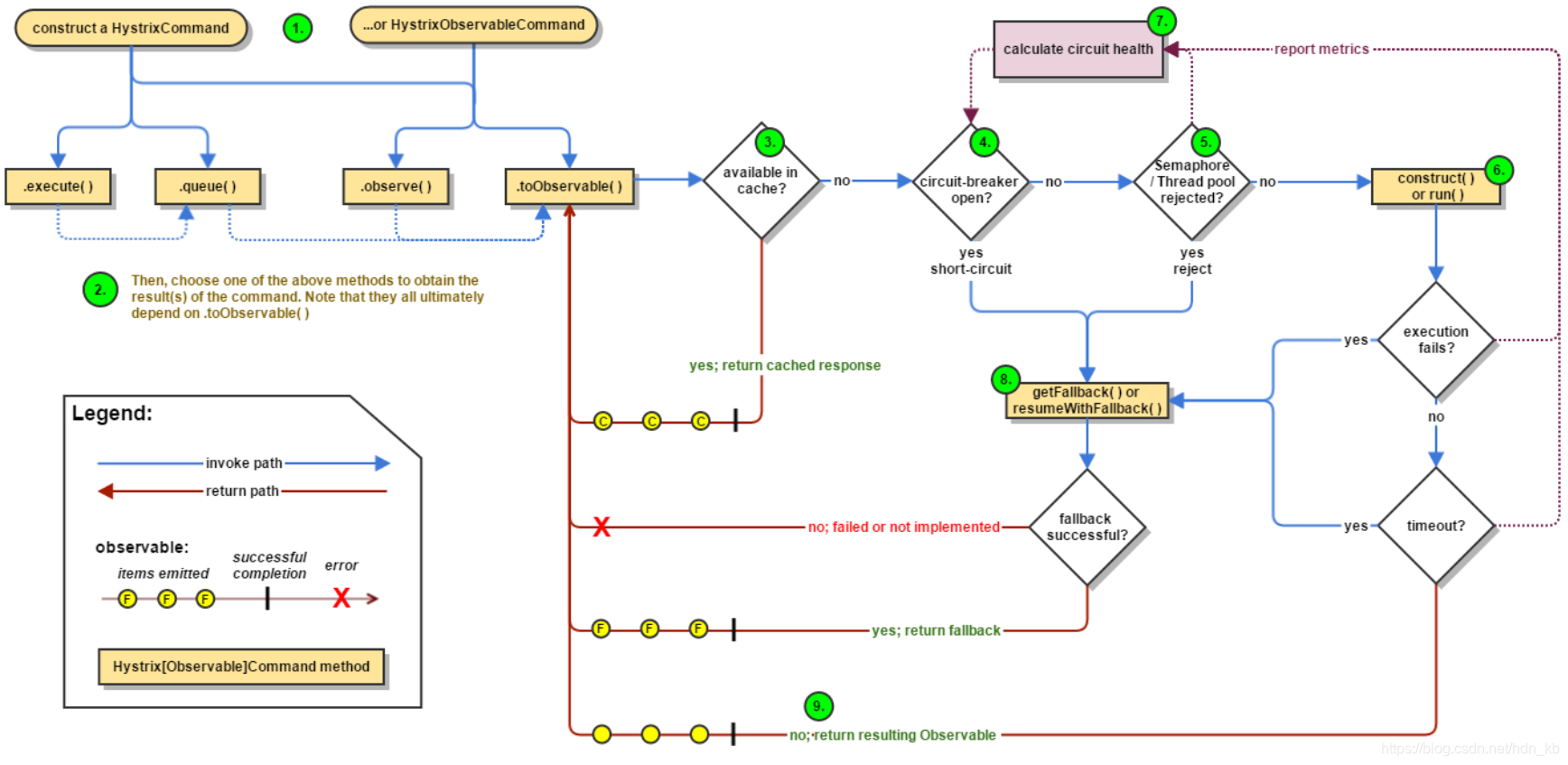
- 1、创建HystrixCommand或HystrixObservableCommand对象。
- 2、执行命令:HystrixCommand(execute()、queue()),HystrixObservableCommand(observe()、toObservable())。
- 3、如果请求缓存功能是被启用的,并且该缓存命中,那么缓存的结果会立即以Observable对象的形式返回。
- 4、检查断路器是否打开,如果是打开的,Hystrix不会执行命令,而直接执行fallback处理逻辑。
- 5、如果与命令相关的线程池和请求队列,或者信号量已经被占满,Hystrix还是不会执行命令,直接执行fallback处理逻辑。
- 6、执行HystrixObservableCommand.construct()或HystrixComamand.run(),如果执行失败或者超时,则执行fallback处理逻辑。
- 7、Hystrix将请求"成功“、”失败“、”拒绝“、”超时“等信息报告给断路器,断路器会维护一组计数器统计这些数据。断路器绘制用这些统计数据来决定是否要将断路器打开,来对某个依赖服务的请求进行”熔断/短路“,知道恢复期结束。若在恢复期结束后,根据统计数据判断如果还是未达到健康指标,就再次”熔断/短路“。
- 8、命令执行失败,Hystrix会进入fallback尝试会回退处理,也就是”服务降级“。
- 9、返回成功的响应。
三、依赖隔离
Hystrix采用”舱壁模式“实现线程池的隔离,它会为每一个依赖服务创建一个独立的线程池,这样的话,就算某个依赖服务出现延迟过高的情况,也只是对该依赖服务的调用产生影响,而不会拖慢其他的依赖服务。
Hystrix为每一个依赖服务维护一个线程池,当线程载满,不会进行线程排队,直接执行fallback或者抛出异常。
总之,通过对依赖服务实现线程池隔离,可让我们的应用更加健壮,不会因为个别依赖服务出现问题而引起非相关服务的异常。同时,也使得我们的应用变得更加灵活,可以在不停止服务的情况下,配合动态配置刷新实现性能配置上的调整(后续会通过Spring Cloud Config与Spring Cloud Bus的联合使用来介绍)。
Hystrix针对线程池延迟的开销设计了另外的解决方案:信号量
信号量和线程池的区别:信号量的开销远比线程池小,但它不能设置超时和实现异步访问。
只有依赖服务在足够可靠的情况下才使用信号量。
在HystrixCommand和HystrixObservableCommand中有两处支持信号量的使用:
1、命令执行:可以在application.properties中设置隔离策略为SEMAPHORE,Hystrix会使用信号量替代线程池来控制依赖服务的并发。表示HystrixCommand.run()执行时的隔离策略。
hystrix.command.HystrixCommandKey.execution.isolation.strategy=SEMAPHORE
2、降级逻辑:当Hystrix尝试降级逻辑时,它会在调用线程中使用信号量。
信号量的默认值为10,我们也可以通过动态刷新的方式来控制并发线程的数量。
--------------------------------------------------------使用详解---------------------------------------------
以下请求命令、服务降级、异常处理内容可参考Spring Cloud (六)、Hystrix的使用详解——命令请求、服务降级、异常处理
请求缓存请参考Spring Cloud (七)、Hystrix的使用详解——请求缓存
请求合并请参考Spring Cloud (八)、Hystrix的使用详解——请求合并
四、请求命令
这里的请求既可以实现同步请求也可以实现异步请求,使用的注解@HystrixCommand
同步请求:主要是内部调用execute()方法,直接返回结果。
异步请求:主要是内部调用queue()方法,通过返回的Future对象再调用get方法来获取结果。
同步实现(注解方式):
//同步请求
@HystrixCommand
public User getUserByName(String name){
return restTemplate.getForObject("http://HELLO-SERVICE/user/{name}",User.class,name);
}异步实现(注解方式):
//异步请求
@HystrixCommand
public Future<User> getUserByNameAsync(String name){
return new AsyncResult<User>() {
@Override
public User invoke() {
return restTemplate.getForObject("http://HELLO-SERVICE/user/{name}",User.class,name);
}
};
}除了传统的同步执行与异步执行之外,我们还可以将HystrixCommand通过Observable来实现响应式执行方式。通过observe()和toObserve()方法可以返回Observable对象。
两种响应式的区别:
observe()返回的是一个Hot Observable,该命令会在observe()调用的时候立即执行,当Observable每次被订阅的时候会重放它的行为。
toObserver()返回的是一个Cold Observable,该命令不会再调用toObservable()执行之后立即执行,只有当所有订阅者都订阅他之后才会执行。
而对响应式注解的实现依然是使用@HystrixCommand。在使用@HystrixCommand注解实现响应式命令时,可以通过observable-ExecutionMode参数控制是使用observe()还是toObservable()执行方式。
- @HystrixCommand(observableExecutionMode=ObservableExecution-Mode.EAGER):EAGER是该参数的模式值,表示使用observe()执行方式。
- @HystrixCommand(observableExecutionMode=ObservableExecution-Mode.LAZY):EAGER是该参数的模式值,表示使用toObservable()执行方式。
五、服务降级
fallback是Hystrix命令执行失败时使用的后备方法,用来实现服务的降级处理逻辑。
通过注解实现服务降级只需要使用@HystrixCommand中的fallbackMethod参数来指定具体的服务降级实现方法。需要将具体的Hystrix命令与fallback实现函数定义在同一个类中,并且fallbackMethod的值必须与实现fallback方法的名字相同。
如果服务降级实现的方法不是一个稳定的逻辑,可能会发生异常,那么我们可以为时间降级服务的方法添加@HystrixCommand注解以生成Hystrix命令,同时使用fallbackMethod来制定服务降级逻辑。
以下情况可以不去实现降级逻辑:
- 执行写操作的命令。
- 执行批处理或离线计算的命令。
六、异常处理
1、异常传播:在命令执行中抛出不触发服务降级的异常时使用:
在使用注解实现Hystrix命令时,支持忽略指定异常类型功能,只需要通过设置@HystrixCommand注解的ignoreException参数,如下:
@HystrixCommand(ignoreExceptions = {ArithmeticException.class},fallbackMethod = "userFallback")
public User getUserByName(String name){
int i = 1 / 0;
return restTemplate.getForObject("http://HELLO-SERVICE/user/{name}",User.class,name);
}
public User userFallback(String name,Throwable e){
logger.info("获取出发服务降级的异常内容:"+e.getMessage());
return new User();
}来看以上代码的定义,当getUserByName方法抛出了ArithmeticException类型的异常时,Hystrix命令不会触发fallback降级逻辑,而是直接抛出异常/by zero。
2、异常获取:需要对不同异常做针对性处理时,就需要获取当前抛出的异常。
用注解的方式来实现异常获取,只需要在fallback实现方法的参数中增加Throwable e对象的定义,这样在方法内部就可以通过e.getMessage()方法获取出发服务降级的具体异常内容了。如下代码:
@HystrixCommand(fallbackMethod = "userFallback")
public User getUserByName(String name){
int i = 1 / 0;
return restTemplate.getForObject("http://HELLO-SERVICE/user/{name}",User.class,name);
}
public User userFallback(String name,Throwable e){
logger.info("获取出发服务降级的异常内容:"+e.getMessage());
return new User();
}七、命令名称、分组以及线程池划分
命令分组:Hystrix会根据组来组织和统计命令的告警、仪表盘等信息。除此之外,Hystrix命令默认的线程划分时根据命令分组来实现的,让相同组名的命令使用同一个线程池。
使用@HystrixCommand注解的时候,可以使用属性来设置命令名称(commandKey)、分组(groupKey)和线程池的划分(threadPoolKey):
八、请求缓存
请求缓存:在同一请求中多次访问服务提供者提供的接口时,保证只访问一次服务提供者提供的接口,在这同一次请求中第一次访问的结果会被缓存,其他的访问将会从缓存中获取结果,从而保证多次访问的结果相同。
使用注解的方式来实现请求缓存:
| 注解 | 描述 | 属性 |
|---|---|---|
| @CacheResult | 命令用来标记请求返回的结果应该被缓存(开启缓存),它必须与@HystrixCommand注解结合使用 | cacheKeyMethod |
| @CacheRemove | 用来让请求命令的缓存失效,失效的缓存根据定义的Key决定 | commandKey, cacheKeyMethod |
| @CacheKey | 用来在请求命令的参数上标记,使其作为缓存的Key值,如果没有标记则会使用所有的参数。如果同时还使用了@CacheResult和@CacheRemove注解的cacheKeyMethod方法指定缓存Key的生成,那么该注解将不会起作用 | value |
缓存Key:Hystrix会根据Key值来区分是否重复的请求,如果Key值相同,那么该依赖只会在第一个请求到达时被真实地调用一次,然后将结果缓存,其他的请求则是直接从缓存中返回结果。
缓存清理:Hystrix会根据Key值将相同缓存Key的结果进行清理,然后再对失效的缓存进行清理。保证在更新之后可以获得最新的结果。这里需要注的是,@CacheRemove注解的commandKey必须要指定,来找到正确的请求命令缓存的位置。
九、请求合并
请求合并:将多个单个请求合并成一个请求,去调用服务提供者。
来看以下的例子(图都是亲手画的哦~~~):
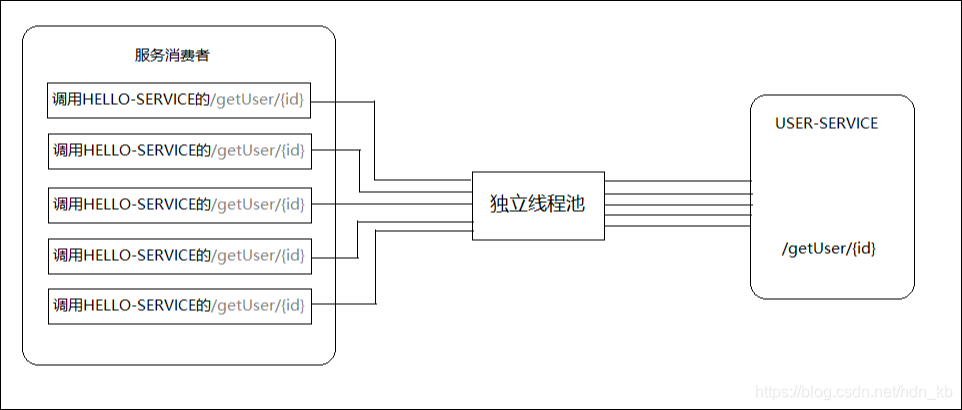
当没有使用HystrixCollapser请求合并器之前的线程使用情况。可以看到,当服务消费者同时对HELLO-SERVICE的/getUser/{id}接口发起5个请求时,会向依赖该服务的独立线程池中申请5个线程来完成各自的操作。
以下时使用的HystrixCollapser请求合并器的情况,在相同情况下的线程占用如下图所示。由于同一时间发生5个请求处于请求合并器的一个时间窗口,这些发向/getUser/{id}接口的请求被请求合并器拦截下来,并在合并器中进行组合,然后将这些请求合并成一个请求发向HELLO-SERVICE的批量接口/getUsers?ids={ids}。在获取到批量结果之后,通过请求合并器再将批量结果拆分并分配给每个被合并的请求。
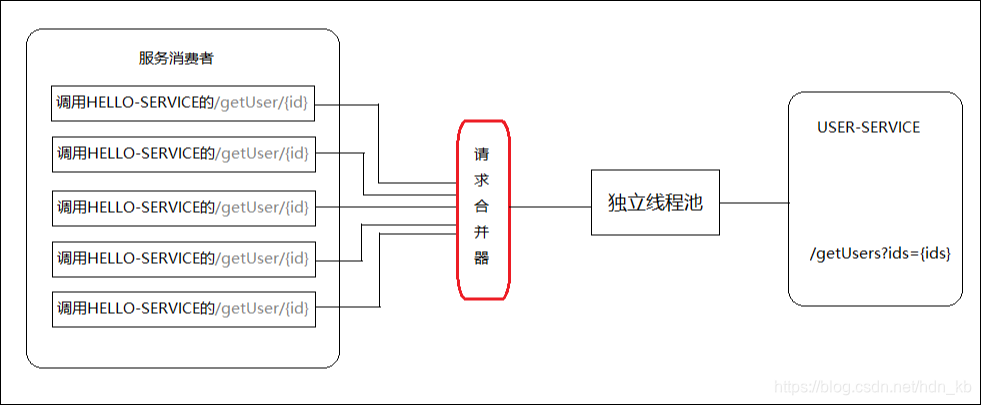
从上图中可以看到,通过使用请求合并器可以有效减少对线程池中资源的占用。所以在资源有效并且短时间内会产生高并发请求的时候,为避免连接不够而引起的延迟可以考虑使用请求合并器的方式来处理和优化。
使用注解来实现请求合并器例子,参考:
@Service
public class UserService {
private Logger logger = Logger.getLogger(String.valueOf(UserService.class));
@Autowired
RestTemplate restTemplate;
//请求合并的方法
//@HystrixCollapser(batchMethod = "findAll",scope = com.netflix.hystrix.HystrixCollapser.Scope.GLOBAL,collapserProperties = {@HystrixProperty(name = "timerDelayInMilliseconds",value = "3000")})
@HystrixCollapser(batchMethod = "findAll",collapserProperties = {@HystrixProperty(name = "timerDelayInMilliseconds",value = "3000")})
public Future<User> find(String id){
//这里本应该访问服务提供者提供(HELLO-SERVICE)的/getUser/{id}接口
logger.info("======执行了find方法========");
return null;
}
//合并请求之后调用的方法
@HystrixCommand
public List<User> findAll(List<String> ids){
logger.info("======执行了findAll方法========"+ids);
return restTemplate.getForObject("http://hello-service/getUsers?ids={1}", List.class, StringUtils.join(ids, ","));
}
}从以上代码中我们可以看到,在请求HELLO-SERVICE的/getUser/{id}接口的方法上通过@HystrixCollapser注解为其创建了合并请求器,通过batchMethod属性指定了批量请求的实现方法为findAll方法(即请求HELLO-SERVICE的/getUsers?ids={ids}接口的命令),同时通过collapserProperties属性为合并请求器设置了相关的属性,@HystrixProperty(name = "timerDelayInMilliseconds",value = "3000")将合并请求时间窗设置为3000毫秒;
这个注解@HystrixCollapser(batchMethod = "findAll",scope = com.netflix.hystrix.HystrixCollapser.Scope.GLOBAL,collapserProperties = {@HystrixProperty(name = "timerDelayInMilliseconds",value = "3000")})中的scope属性来设置了请求合并的作用域:GLOBAL将所有线程的请求中的多次服务调用进行合并,REQUEST(默认)将一次请求的多次服务调用进行合并。
因为请求合并器会带来额外开销,所以在使用请求合并器的时候应该考虑以下两个方面:
- 请求命令本身的延迟。
- 延迟时间窗内的并发量。
--------------------------------------------------------属性详解---------------------------------------------
十、Command属性
主要用来控制HystrixCommand命令的行为
1、execution配置:配置的是HystrixCommand.run()执行。
2、fallback配置:用来控制HystrxCommand.getFallback()的执行。
3、circuitBreaker配置:断路由的属性配置,用来控制HystrixCircuitBreaker的行为。
4、metrics配置:Hystrix命令执行中捕获指标信息。
5、requestContext:配置Hystrix命令使用的HystrixRequestContext。
十一、collapser属性
用来控制命令合并额相关行为。
十二、threadPool属性
用来控制Hystrix命令所属线程池的配置。
--------------------------------------------------------仪表盘---------------------------------------------
本部分内容请参考Spring Cloud (九)、Hystrix仪表盘(单体应用监控)-Turbine集群监控
十三、Hystrix仪表盘
主要用来实时监控Hystrix的各项指标信息,通过Hystrix Dashboard反馈的实时信息,可以帮助我们快速发现系统中存在问题,从而及时采取应对措施。
从Hystrix Dashboard的监控首页(如下图),可以知道Hystrix Dashboard共支持三种不同的监控方式:
- 默认的集群监控:通过URL http://turbine-hostname:port/turbine.stream开启,实现默认集群的监控。
- 指定的集群监控:通过URL http://turbine-hostname:port/turbine.stream?cluster=[clusterName]开启,实现对clusterName集群的监控。
- 单体应用的监控:通过URL http://hystrix-app:port/hystrix.stream开启,实现对具体某个服务实例的监控。
前两者对集群的监控需要整合Turbine才能实现。
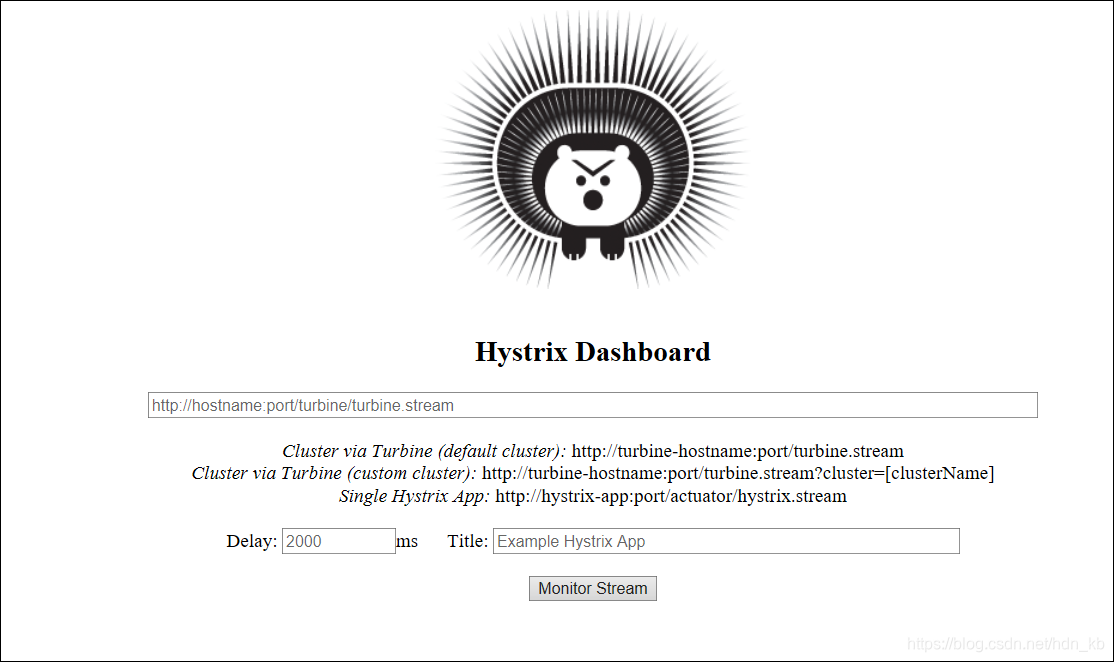
对单个服务进行监控使用的监控端点/hystrix.stream。
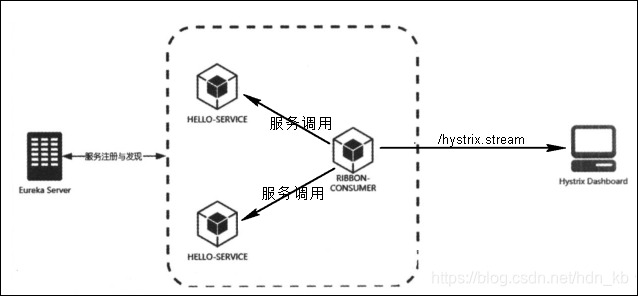
十四、Turbine集群监控
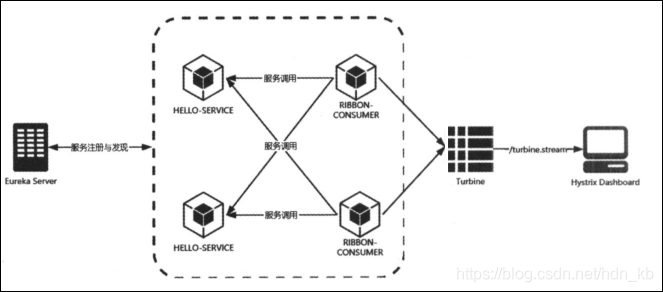
集群监控的端点/turbine.stream。我们需要引入Turbine来汇集监控信息,并将聚合后的信息提供给Hystrix Dashboard来集中显示和监控。
对于集群来说我们关注的是服务集群的高可用性,Turbine会将相同服务作为整体来看待,并汇总成一个监控图。
十五、与消息代理结合
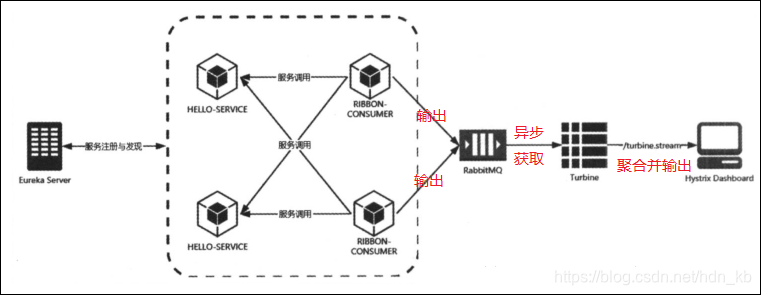
Spring Cloud在封装Turbine的时候,还封装了基于消息代理的手机实现。所以我们可以将所有需要收集的监控信息都输出到消息代理中,然后Turbine服务再从消息代理中异步获取这些监控信息,最后将这些监控信息聚合并输出到Hystrix Dashboard中。

















 399
399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









