







 本文介绍了模板匹配模式作为模式识别的一种方法,解释了其在认知图像中的应用原理。该模型认为,人的长时记忆中存储着各种外部模式的袖珍复本——模板,当刺激作用于感官时,会与这些模板进行比较以识别模式。
本文介绍了模板匹配模式作为模式识别的一种方法,解释了其在认知图像中的应用原理。该模型认为,人的长时记忆中存储着各种外部模式的袖珍复本——模板,当刺激作用于感官时,会与这些模板进行比较以识别模式。
人脑是怎样认知图像的?——模板匹配模式(传统模式识别之一)
2007-09-16 23:11
作者是刘建忠
|
这个模型最早是针对机器的模式识别而提出来的,后来被用来解释人的模式识别。
它的核心思想是认为在人的长时记忆中,贮存着许多各式各样的过去在生活中形成的外部模式的袖珍复本。这些袖珍复本即称作模板(Template),它们与外部的模式有一对一的对应关系;当一个刺激作用于人的感官时,刺激信息得到编码并与已贮存的各种模板进行比较,然后作出决定,看哪一个模板与刺激有最佳的匹配,就把这个刺激确认为与那个模板相同。这样,模式就得到识别了。由于每个模板都与一定的意义及其他的信息相联系,受到识别的模式便得到解释或其他的加工。例如,当我们看一个字母A,视网膜接收的信息便传到大脑,刺激信息在脑中得到相应的编码,并与记忆中贮存的各式各样的模板进行比较;通过决策过程判定它与模板A有最佳的匹配,于是字母A就得到识别;而且我们还可以知道,它是英文字母表中的第一个字母,或是考试得到的最好的分数等等。由此可见,模式识别是一个一系列连续阶段的信息加工过程。 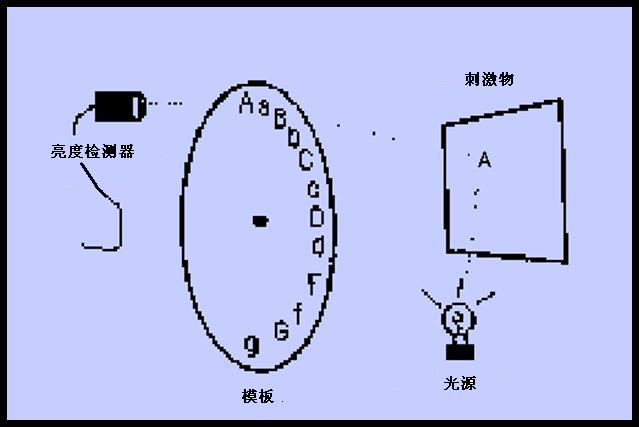
然而现实世界输入视觉系统的景物是复杂的。就拿字符“F”来说,输入“F”字符可能是拉伸的、压缩的、旋转的、歪扭的、断裂的,等等,这使得模板匹配工作变得困难和复杂起来。
主要困难有两个:一是三维景物的匹配;而是集成物体的匹配。
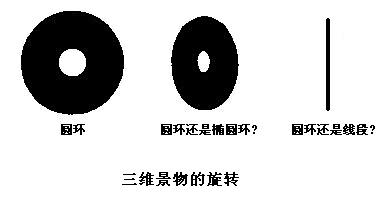
一个圆环可以在三维空间内可以旋转形成上图中图形。不难看出,当物体旋转后会失去一部分信息。此时模板模式对旋转后的图形是判断为椭圆呢?还是圆?
当把一大堆物体,比如几十本书,无规则的放在一起时,面对重叠的物体图像如何进行模板匹配呢?
|

















 3455
3455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









