




 本文详细探讨了Java集合框架中的核心数据结构,如HashMap、HashSet、ArrayList、LinkedList等的内部实现原理,包括线程安全、扩容策略、哈希冲突解决及红黑树应用等关键概念。
本文详细探讨了Java集合框架中的核心数据结构,如HashMap、HashSet、ArrayList、LinkedList等的内部实现原理,包括线程安全、扩容策略、哈希冲突解决及红黑树应用等关键概念。
hashmap的put过程

0.1.set不允许出现重复元素,并且无序
hashset的底层依然是hashmap.
1.线程同步:即当有一个线程在对内存进行操作时,其他线程都不可以对这个内存地址进行操作,直到该线程完成操作, 其他线程才能对该内存地址进行操作,而其他线程又处于等待状态
2.Arraylist 与 LinkedList 异同
ArrayList和LinkedList都实现了List接口,有以下的不同点:
1、ArrayList是基于索引的数据接口,它的底层是数组。它可以以O(1)时间复杂度对元素进行随机访问。与此对应,LinkedList是以元素列表的形式存储它的数据,每一个元素都和它的前一个和后一个元素链接在一起,在这种情况下,查找某个元素的时间复杂度是O(n)。
2、相对于ArrayList,LinkedList的插入,添加,删除操作速度更快,因为当元素被添加到集合任意位置的时候,不需要像数组那样重新计算大小或者是更新索引。
3、LinkedList比ArrayList更占内存,因为LinkedList为每一个节点存储了两个引用,一个指向前一个元素,一个指向下一个元素。
为什么数组比链表查询速度更快?
- 数组由于是紧凑连续存储,可以随机访问,通过索引快速找到对应元素,而且相对节约存储空间。但正因为连续存储,内存空间必须一次性分配够,所以说数组如果要扩容,需要重新分配一块更大的空间,再把数据全部复制过去,时间复杂度 O(N);而且你如果想在数组中间进行插入和删除,每次必须搬移后面的所有数据以保持连续,时间复杂度 O(N)。
- 链表因为元素不连续,而是靠指针指向下一个元素的位置,所以不存在数组的扩容问题;如果知道某一元素的前驱和后驱,操作指针即可删除该元素或者插入新元素,时间复杂度O(1)。但是正因为存储空间不连续,你无法根据一个索引算出对应元素的地址,所以不能随机访问;而且由于每个元素必须存储指向前后元素位置的指针,会消耗相对更多的储存空间。
3.ArrayList 与 Vector 区别
Vector类的所有方法都是同步的。可以由两个线程安全地访问一个Vector对象、但是一个线程访问Vector的话代码要在同步操作上耗费大量的时间。在原来的空间存不下的时候增长为原来的2倍空间大小
Arraylist不是同步的,所以在不需要保证线程安全时时建议使用Arraylist。在原来空间存不下数据的时候增长为原来的1.5倍空间大小
两者都是通过数组来存储数据的,都允许直接按序号索引元素。
4.HashMap 和 Hashtable 的区别
- 线程是否安全: HashMap 是非线程安全的,HashTable 是线程安全的;HashTable 内部的方法基本都经过
synchronized修饰。(如果你要保证线程安全的话就使用 ConcurrentHashMap 吧!); - 效率: 因为线程安全的问题,HashMap 要比 HashTable 效率高一点。另外,HashTable 基本被淘汰,不要在代码中使用它;
- 对Null key 和Null value的支持: HashMap 中,null 可以作为键,这样的键只有一个,可以有一个或多个键所对应的值为 null。。但是在 HashTable 中 put 进的键值只要有一个 null,直接抛出 NullPointerException。
- 初始容量大小和每次扩充容量大小的不同 : ①创建时如果不指定容量初始值,Hashtable 默认的初始大小为11,之后每次扩充,容量变为原来的2n+1。HashMap 默认的初始化大小为16。之后每次扩充,容量变为原来的2倍。②创建时如果给定了容量初始值,那么 Hashtable 会直接使用你给定的大小,而 HashMap 会将其扩充为2的幂次方大小。也就是说 HashMap 总是使用2的幂作为哈希表的大小,后面会介绍到为什么是2的幂次方。
- 底层数据结构: JDK1.8 以后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。Hashtable 没有这样的机制。
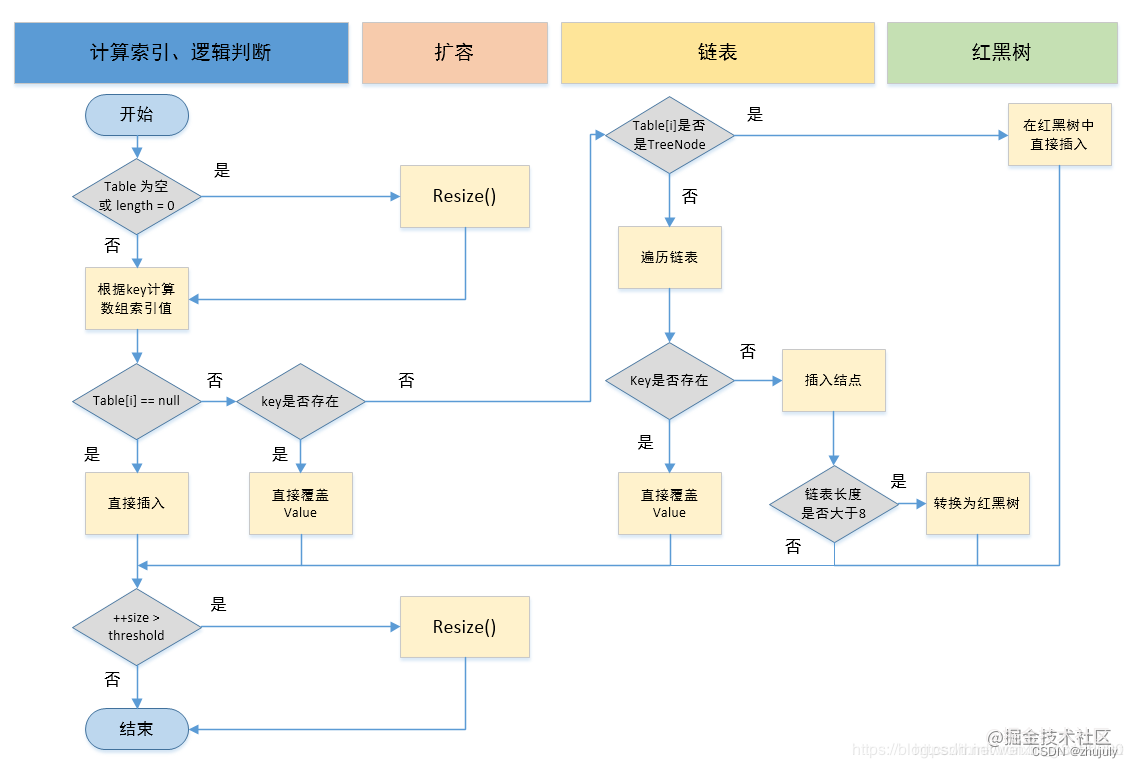
Hashmap的底层就是拉链法存储的。。就是数组与链表相结合。
使用散列函数 计算地址,具有相同地址的放在同一个链表中。
用hashcode找到一个地址如果地址位置上是空的就放进去,如果不是空的就放到地址后面的拉链上(调用.equals()方法去找)
如果定位到的数组包含链表,对于添加操作,其时间复杂度为O(n),首先遍历链表,存在即覆盖,否则新增
对于查找操作来讲,仍需遍历链表,然后通过key对象的equals方法逐一比对查找。所以,性能考虑,HashMap中的链表出现越少,性能才会越好。
计算Hash当然是用key来算的,但是计算Hash的过程有点复杂,
int hash = hash(key.hashCode());发生冲突关于entry节点插入链表还是链头呢?
JDK7:插入链表的头部,头插法
JDK8:插入链表的尾部,尾插法
https://www.jianshu.com/p/a7767e6ff2a2
-
HashMap的默认长度为16和规定数组长度为2的幂,是为了降低hash碰撞的几率。
5.LinkedHashMap
LinkedHashMap继承了HashMap
LinkedHashMap存入数值是有序的,HashMap是无序的。
就是说先map.put()插入数据,然后再把数据遍历出来的话,HashMap遍历出来跟插入的顺序不一致,而LinkedHashMap就是一致的。
6.HashSet
HashSet的底层就是HashMap
HashsSet的值存储在HashMap的Key上面,value部分无所谓了
HashSet的add()方法的底层就是HashMap的put()方法
HashSet重写了HashMap的equals()和HashCode方法
HashMap是用key来计算hashcode,HashSet使用成员对象来计算Hashcode
7.set元素是不能有重复的 通过quuels()方法确定是否重复
8.Iterator和Listiterator的区别
JAVA中ListIterator和Iterator详解与辨析_longshengguoji的博客-优快云博客
9.violate
关键字关键是保证了有序性和和可见性
有序性是指:violate修饰的语句前
面的语句不会在violate修饰的语句后面执行,violate修饰的语句后面的语句不会在violate修饰的语句前面执行
可见性:violate修饰的语句执行完会立即将内容写入内存,以供下一个要使用该内容的语句使用
Java中violate关键字详解(2)?真正了解violate_NobiGo的博客-优快云博客_java violate
10.ConcurrentHashamap
(jdk1.7)ConcurrentHashMap 与HashMap和Hashtable 最大的不同在于:put和 get 两次Hash到达指定的HashEntry,第一次hash到达Segment,第二次到达Segment里面的Entry,然后在遍历entry链表.
线程安全的,在jdk1.7中ConcurrentHashMap包含一个Segment数组,每个Segment包含一个HashEntry数组,当修改HashEntry数组采用开链法处理冲突,所以它的每个HashEntry元素又是链表结构的元素。
采用分段锁 每个segment继承ReentrantLock
ConcurrentHashMap使用分段锁技术,将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问,能够实现真正的并发访问。
 这是Jdk1.7的结构
这是Jdk1.7的结构
跟垃圾hashtable的比较:
HashTable通过使用synchronized保证线程安全,但在线程竞争激烈的情况下效率低下。因为当一个线程访问HashTable的同步方法时,其他线程只能阻塞等待占用线程操作完毕。
ConcurrentHashMap 1.8的结构
在jdk1.8中(就是高并发的Hashmap) 数组+链表+红黑树
DK1.8的currentHashMap参考了1.8HashMap的实现方式,采用了数组,链表,红黑树的实现方
Java8 ConcurrentHashMap结构基本上和Java8的HashMap一样,不过保证线程安全性。
CAS + synchronized保证并发更新 node存储数据
-当前bucket为空时,使用CAS操作,将Node放入对应的bucket中。
- 出现hash冲突,则采用synchronized关键字。倘若当前hash对应的节点是链表的头节点,遍历链表,若找到对应的node节点,则修改node节点的val,否则在链表末尾添加node节点;倘若当前节点是红黑树的根节点,在树结构上遍历元素,更新或增加节点。
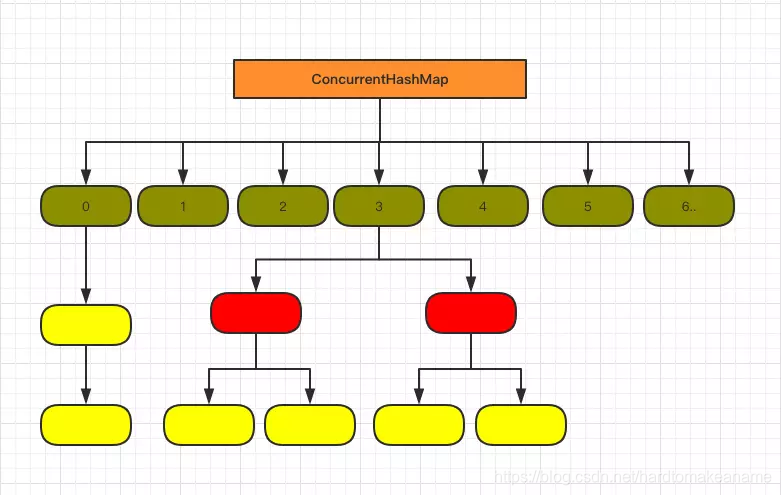 Jdk1.8ConcurrentHashmap的结构
Jdk1.8ConcurrentHashmap的结构
使用CAS

十一:为什么hashmap的长度要是2的幂次方呢
为了减少hash碰撞,使数据尽量分配的均匀
hashmap拿到key之后首先调用hash函数得到一个hash值
static final int hash(Object key) {
int h;
// key.hashCode():返回散列值也就是hashcode
// ^ :按位异或
// >>>:无符号右移,忽略符号位,空位都以0补齐
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}然后利用这个hash值使用hash&(length-1) (这个&运算的时候会先把两边编程二进制)得到具体的 位置
为什么使用hash&(length-1) 就会减少冲突了呢
因为如果length是2的幂次方的话,那么就是1后面几个0,比如16,00001000,减去1那么得到的奇数就变成00000111,
这样一个数跟这个很多1的二进制进行&运算的时候就会不容易碰撞,


















 538
538



 到【灌水乐园】发言
到【灌水乐园】发言







