




 在MySQL中使用ORDER BY和LIMIT进行数据查询时,若存在相同排序值,可能会导致分页查询结果不一致。当数据创建时间精确度不足,如只到时分秒,LIMIT不同值可能返回不同结果。解决办法是在ORDER BY语句中加入唯一主键作为排序条件,以确保结果的稳定性。
在MySQL中使用ORDER BY和LIMIT进行数据查询时,若存在相同排序值,可能会导致分页查询结果不一致。当数据创建时间精确度不足,如只到时分秒,LIMIT不同值可能返回不同结果。解决办法是在ORDER BY语句中加入唯一主键作为排序条件,以确保结果的稳定性。
Mysql查询时使用order by limit的隐患及解决办法
Mysql + order by limit
我们经常会使用order by 和limit 在做数据查询时排序,限定条数或者是分页排序,平时运用中也没有发现什么异常。但最近的一个项目使用这种方法查询时发现了一个严重的问题,我在用Job导入数据时,因为存在同时导入了大量的数据,数据的创建时间DataChange_CreateTime只精确到时分秒,存在同样时间的数据。在用order by limit 分页查询,且筛选一定条数的时候,出现结果不一致的情况。查询数目(即limit 的数据) 为10 和 1000的时候,两者结果最初的10条数据不一致。查询资料发现问题所在,后文也会提供解决办法。记录下来,防止自己再次犯错的同时也给大家提个醒。
类似问题出现情景
现有一张表,表结构如下:

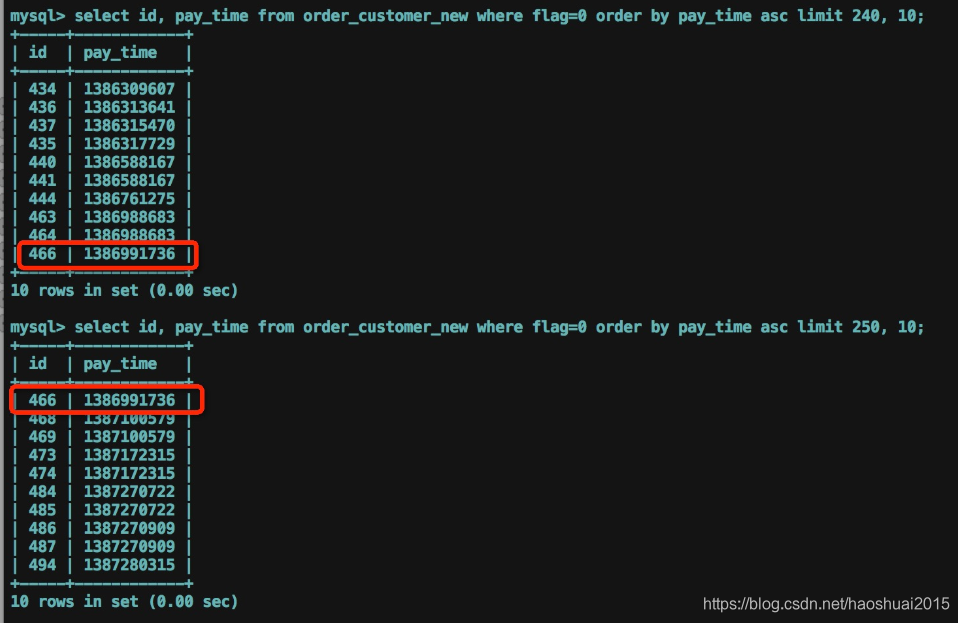
大概5000条数据, 大部分记录的flag都等于0,pay_time字段时间戳格式都正确
我们使用limit分批读取数据:
select id, pay_time from order_customer_new where flag=0 order by pay_time asc limit 250, 10;
读取数据的过程中,发现有时间戳相等的记录,分两次读取,可能会丢失某条记录。如下图所示,id=465的记录就丢失了。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1041
1041

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









