




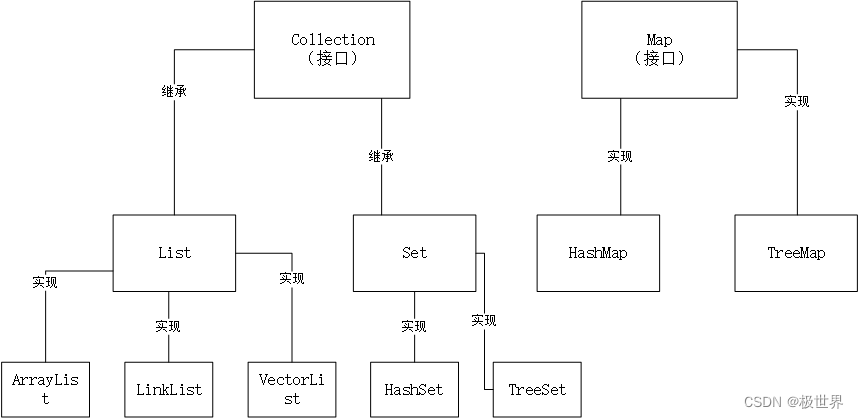
Java集合主要分为Collection和Map两个接口;Collection又分别被List和Set继承;List被AbstractList实现,然后分为3个子类,ArrayList,LinkList和VectorList;Set被AbstractSet实现,又分为2个子类,HashSet和TreeSet;Map被AbstractMap实现,又分为2个子类,HashMap和TreeMap;Map被Hashtable实现。
ArrayList和LinkedList、Vector的区别
ArrayList和LinkedList的区别:
(1)相同点:
LinkedeList和ArrayList都实现了List接口。
ArrayList和LinkedList是两个集合类,用于存储一系列的对象引用(references)。
(2)不同点:
ArrayList底层的实现数组,而LinkedList是双向链表。
ArrayList进行随机访问所消耗的时间是固定的,因此随机访问时效率比较高。
LinkedList是不支持快速的随机访问的,但是在插入删除时效率比较高。
ArrayList和Vector的区别:
(1)相同点:
ArrayList和Vector都是用数组实现的。
默认初始化大小都是10
(2)不同点
Vector多线程是安全的,而ArrayList不是。Vector类中的方法很多有synchronized进行修饰,这样就导致了Vector在效率上无法与ArrayList相比;
两个都是采用的线性连续空间存储元素,但是当空间不足的时候,两个类的增加方式是不同的。(ArrayList每次存储时会检查空间大小,不够时会扩充为原来的1.5倍,Vector会扩充为原来空间的2倍)
原文
https://blog.youkuaiyun.com/glpghz/article/details/107581333
HashSet和TreeSet的区别
相同点:单例集合,数据不可重复
不同点1:底层使用的储存数据结构不同:
1,Hashset底层使用的是HashMap哈希表结构储存
2,而Treeset底层用的是TreeMap树结构储存。
不同点2:储存的数据保存唯一方式不用。
1,Hashset是通过复写hashCode()方法和equals()方法来保证的。
2,而Treeset是通过Compareable接口的compareto方法来保证的。
不同点3:
hashset无序 Treeset有序
储存原理:
hashset:底层数据结构是哈希表,本质就是哈希值储存。通过判断元素的hashcode方法和equals方法来保证元素的唯一性。当哈希值不同时就直接进行储存。
如果相同,会判断一次equals方式是否返回为true ,如果是true 则视为用的同一个元素,不用再储存。 如果是false,这俄格相同哈希值不同内容的元素会放在同一个桶里(
当哈希表中有一个桶结构,每一个捅都有一个哈希值)
Treeset:底层数据结构式一个二叉树,可以对set集合中的元素进行排序,这种结构,可以提高排序性能。根据比较方法的返回值决定的,只要返回的是0,就代表元素重复。
原文
https://blog.youkuaiyun.com/qq_42216184/article/details/84026603
HashMap 和 TreeMap 的区别:
原文
https://blog.youkuaiyun.com/weixin_43281498/article/details/123434620
Java中的List、Set和Map的各自特征及使用场景:
Java中的集合分为单列集合Collection和双列集合Map。
先通过这张图看看Collection和Map的各自体系。
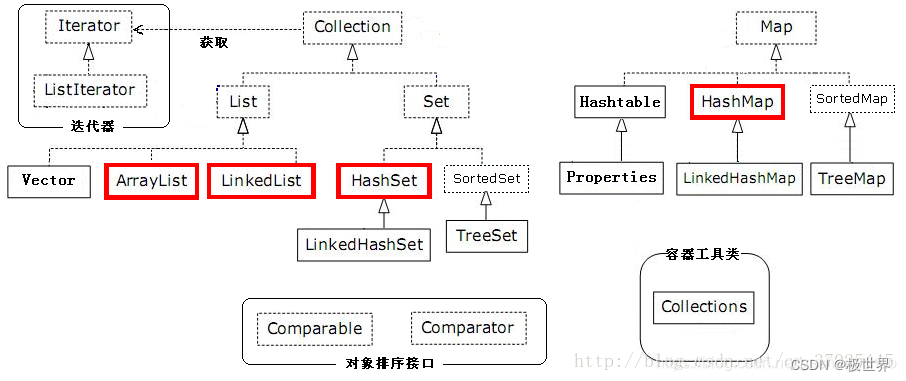
首先看单列集合Collection中的List及Set的各自特征。
List(有序,可重复)
ArrayList
底层数据结构是数组,查询快,增删慢
线程不安全,效率高
Vector
底层数据结构是数组,查询快,增删慢
线程安全,效率低
LinkedList
底层数据结构是链表,查询慢,增删快
线程不安全,效率高
Set(无序,唯一)
HashSet
底层数据结构是哈希表。
LinkedHashSet
底层数据结构由链表和哈希表组成。
由链表保证元素有序。
由哈希表保证元素唯一。
TreeSet
底层数据结构是红黑树。(是一种自平衡的二叉树)
根据比较的返回值是否是0来决定保证元素唯一性
两种排序方式
自然排序(元素具备比较性)
让元素所属的类实现Comparable接口
比较器排序(集合具备比较性)
让集合接收一个Comparator的实现类对象
接下来是双列集合Map的特征
Map(双列集合)
注:Map集合的数据结构仅仅针对键有效,与值无关。存储的是键值对形式的元素,键唯一,值可重复。
HashMap
底层数据结构是哈希表。线程不安全,效率高
哈希表依赖两个方法:hashCode()和equals()
执行顺序:
首先判断hashCode()值是否相同
是:继续执行equals(),看其返回值
是true:说明元素重复,不添加
是false:就直接添加到集合
否:就直接添加到集合
最终:
自动生成hashCode()和equals()即可
LinkedHashMap
底层数据结构由链表和哈希表组成。
由链表保证元素有序。
由哈希表保证元素唯一。
Hashtable
底层数据结构是哈希表。线程安全,效率低
哈希表依赖两个方法:hashCode()和equals()
执行顺序:
首先判断hashCode()值是否相同
是:继续执行equals(),看其返回值
是true:说明元素重复,不添加
是false:就直接添加到集合
否:就直接添加到集合
最终:
自动生成hashCode()和equals()即可
TreeMap
底层数据结构是红黑树。(是一种自平衡的二叉树)
根据比较的返回值是否是0来决定保证元素唯一性
两种排序方式
自然排序(元素具备比较性)
让元素所属的类实现Comparable接口
比较器排序(集合具备比较性)
让集合接收一个Comparator的实现类对象
那么到底什么时候需要用什么样的集合呢?
画一张图总结下
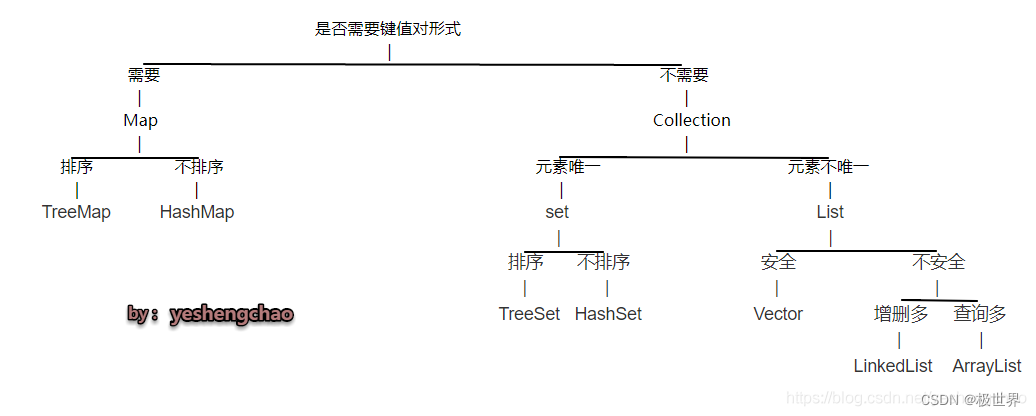
原文:
https://blog.youkuaiyun.com/codest/article/details/120093254

















 699
699

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









