







 本文介绍了如何使用Selenium接管已登录的Chrome浏览器来爬取淘宝联盟的优惠券信息,包括图片URL、优惠券标题、券前价格、券后价格、佣金率和佣金。通过定位HTML标签,提取所需数据,避免了JS逆向。文章还展示了处理价格和佣金信息的代码示例,并提到Selenium爬取速度较慢的问题。
本文介绍了如何使用Selenium接管已登录的Chrome浏览器来爬取淘宝联盟的优惠券信息,包括图片URL、优惠券标题、券前价格、券后价格、佣金率和佣金。通过定位HTML标签,提取所需数据,避免了JS逆向。文章还展示了处理价格和佣金信息的代码示例,并提到Selenium爬取速度较慢的问题。
本文将介绍使用selenium爬取某宝优惠券的方法,之所以使用selenium是因为我不会js逆向,如果你已经参透了淘宝联盟的js逆向方法,那么直接使用接口调数据就行了。
使用selenium接管chrome浏览器
由于淘宝联盟需要先登录,为了避免每次打开selenium都要重新登录,我们让selenium接管已经登录过账号的chrome浏览器进程进行爬虫。
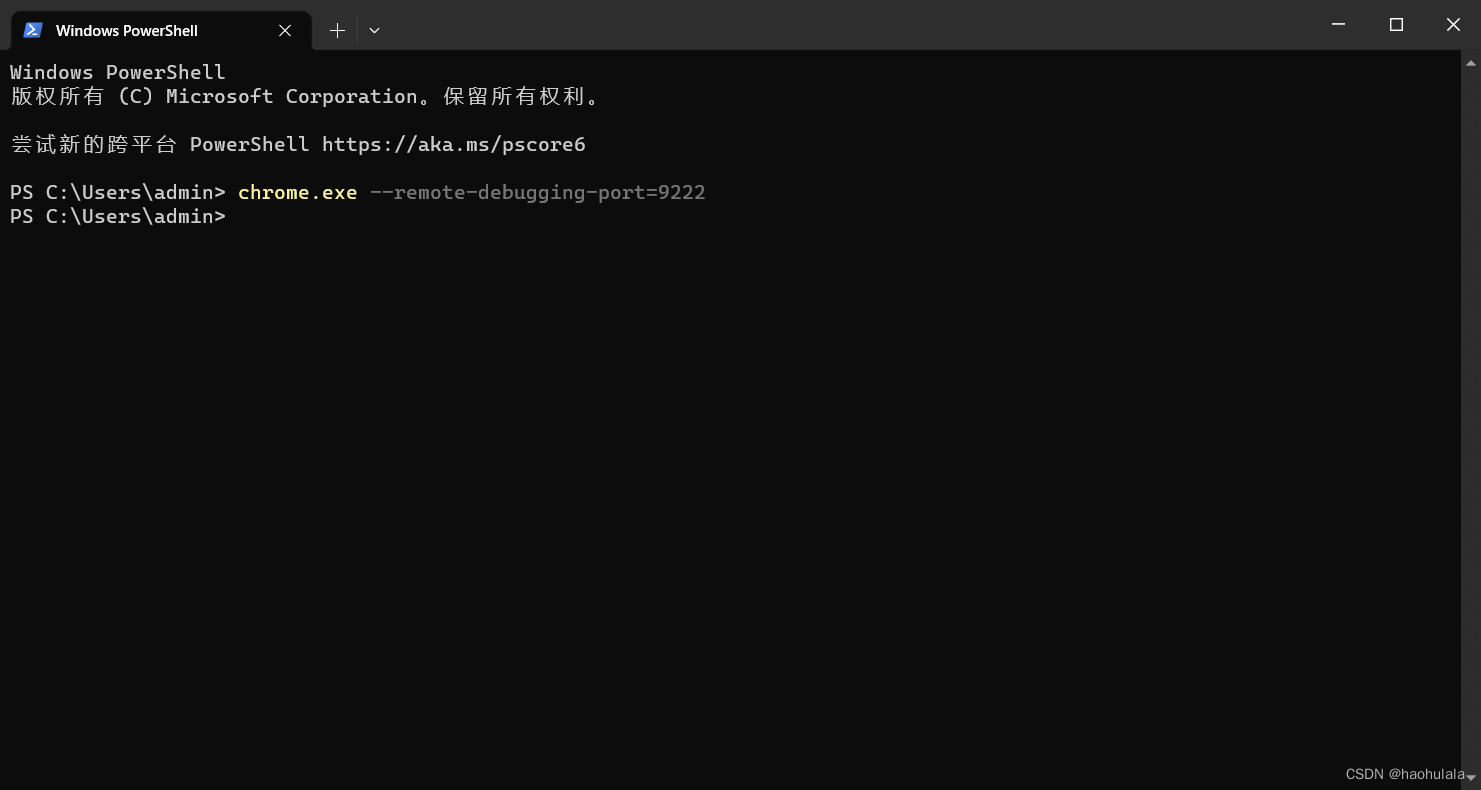
在打开的浏览器中输入某宝联盟首页,然后扫码登录即可阿里妈妈 https://pub.alimama.com/portal/v2/pages/promo/goods/index.htm
https://pub.alimama.com/portal/v2/pages/promo/goods/index.htm
优惠券卡片对应的html标签
其实我感觉爬虫真的没什么难度,因为前端再写的时候一般都会把重复的元素放到一个循环里面去创建,优惠券卡片也不例外,因此我们只需要找到数组,逐个提取其中的元素即可。
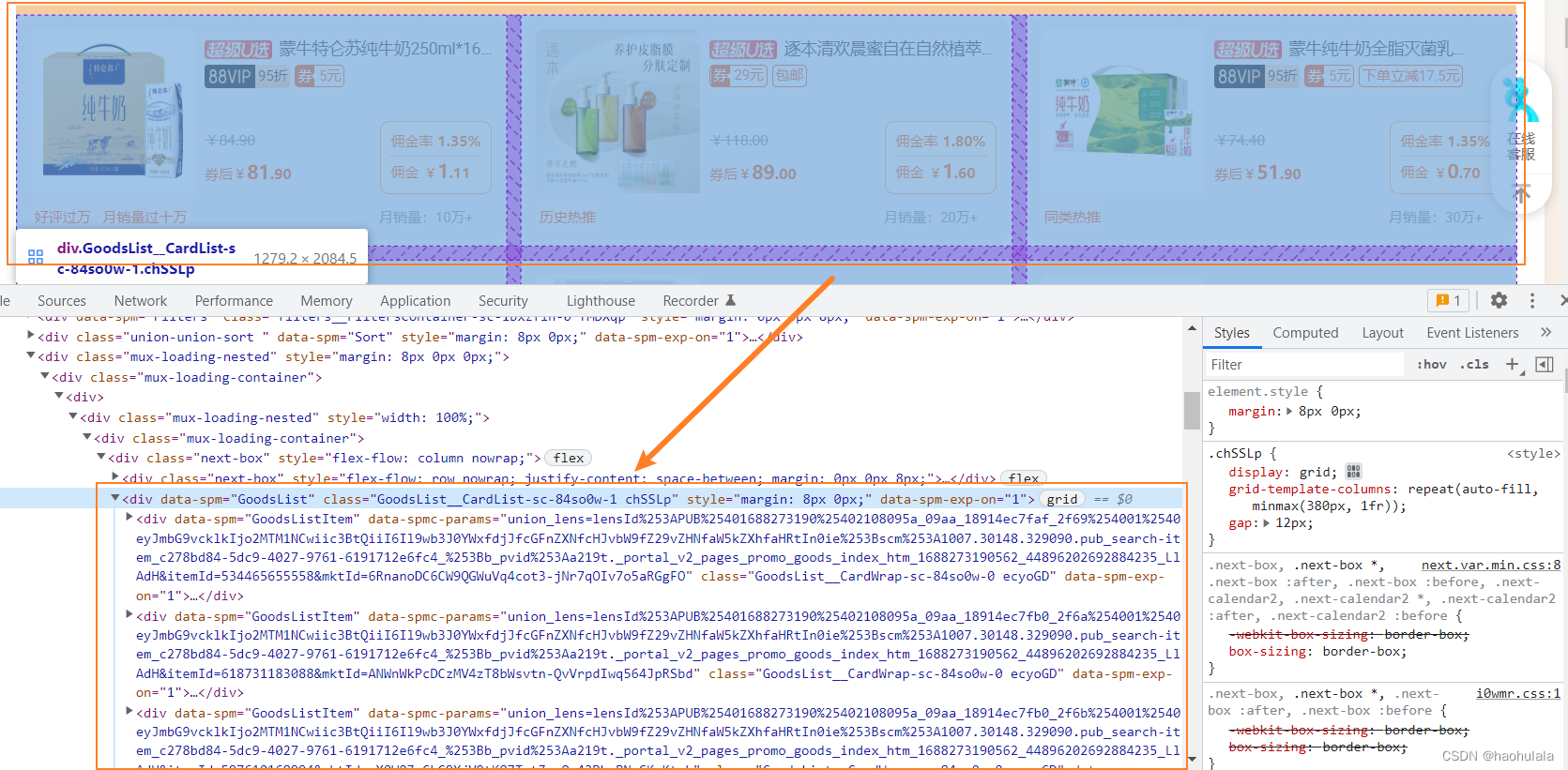
很容易发现,装有优惠券卡片的数组的
class=GoodsList__CardList-sc-84so0w-1 chSSLp
我们只需要找个这个div,然后逐个遍历数据提取信息即可。
我们首先来确定一下,本文主要爬取一张卡片的以下六个信息,分别是
-
图片url
-
优惠券标题
-
券前价格
-
券后价格
-
佣金率
-
佣金
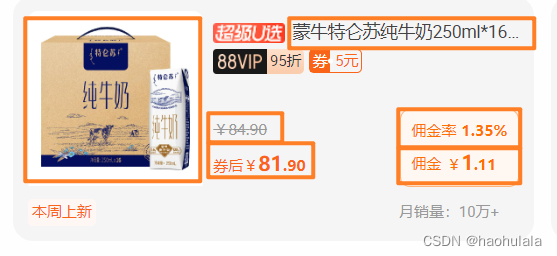
对应上述六个数据,建立一
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 864
864

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









