



大家读完聚德有帮助记得关注和点赞!!!
抽象
音频在说话人验证、支持语音的智能设备和音频会议等应用中发挥着至关重要的作用。但是,音频作(例如 deepfakes)会传播错误信息,从而带来重大风险。我们的实证分析表明,现有的深度伪造音频检测方法通常容易受到反取证 (AF) 攻击,尤其是那些使用生成对抗网络攻击的方法。在本文中,我们提出了一种名为 SHIELD 的新型协作学习方法来防御生成式 AF 攻击。为了暴露 AF 签名,我们集成了一个辅助生成模型,称为防御 (DF) 生成模型,它通过结合输入和输出来促进协作学习。此外,我们设计了一个三元组模型,以使用辅助生成模型捕获真实和 AF 攻击音频与真实生成和攻击生成的音频的相关性。拟议的 SHIELD 加强了对生成式 AF 攻击的防御,并在各种生成模型中实现了稳健的性能。对于三种不同的生成模型,拟议的 AF 将 ASVspoof2019 的平均检测准确率从 95.49% 降低到 59.77%,In-the-Wild 的平均检测准确率从 99.44% 降低到 38.45%,HalfTruth 的平均检测准确率从 98.41% 降低到 51.18%。所提出的 SHIELD 机制对 AF 攻击具有鲁棒性,对于 ASVspoof2019、In-the-Wild 和 HalfTruth 数据集,匹配平均准确率分别为 98.13%、98.58% 和 99.57%,不匹配设置平均准确率分别为 98.78%、98.62% 和 98.85%。
1介绍
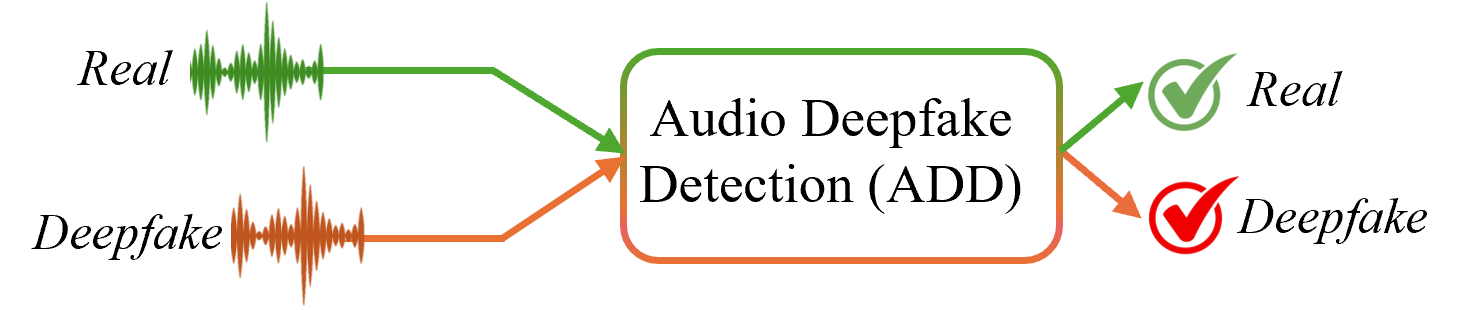
(一)
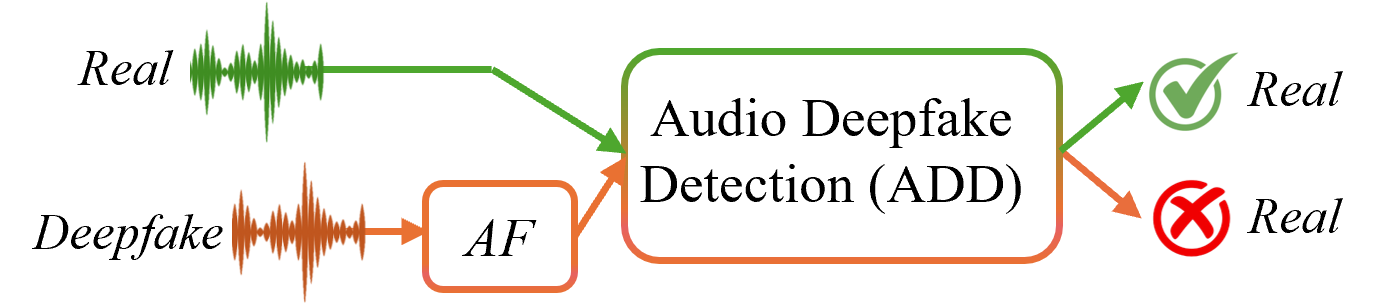
(二)
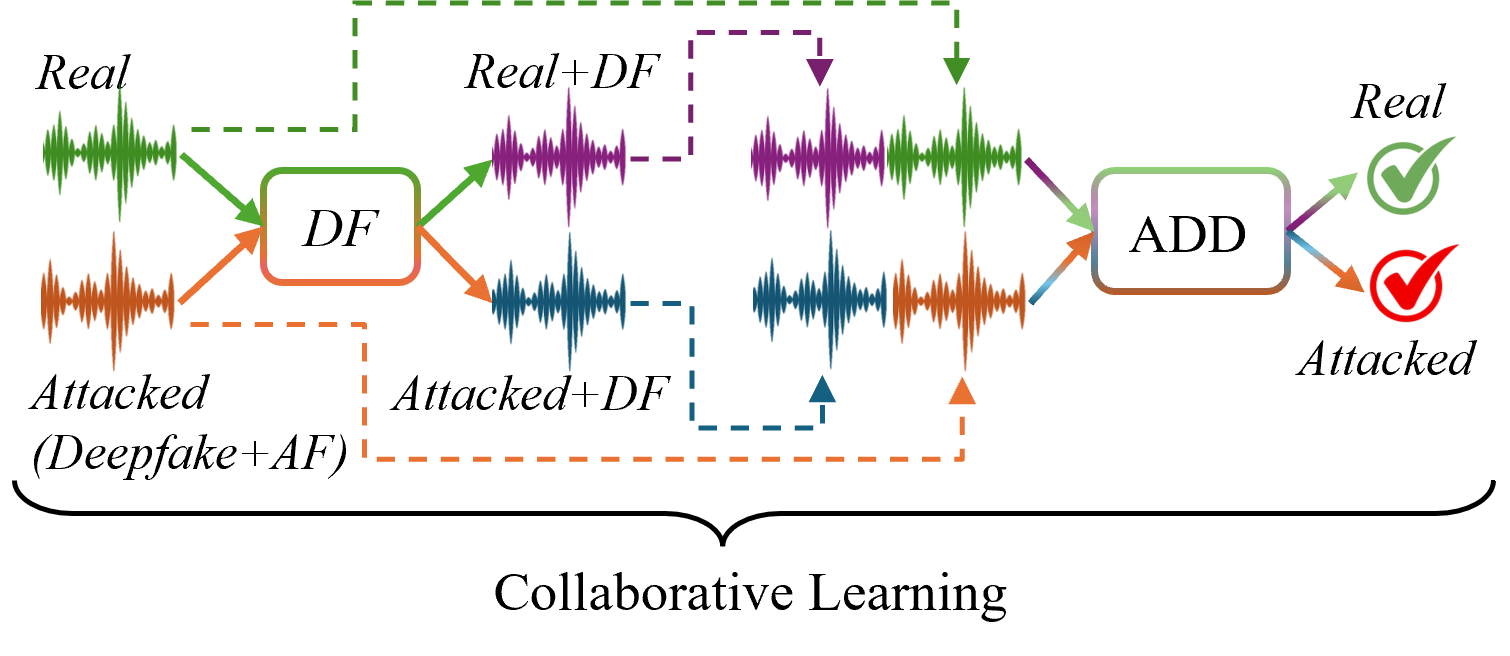
(三)
图 1:传统 ADD、AF 攻击的概念概述,以及针对 AF 攻击的拟议 SHIELD 框架。 (a) 传统的 ADD 方法有效地区分了真实样本和 deepfake 样本。 (b) 但是,应用于深度伪造的 AF 攻击会降低检测性能,使这些方法容易受到攻击。 (c) 相比之下,所提出的基于协作学习的 SHIELD 通过结合辅助生成签名 (DF) 来支持 ADD 模型,从而提高了鲁棒性。
生成式人工智能的进步显著改善了合成语音的生成,实现了类似人类的音频深度伪造。现代文本转语音和语音克隆系统现在能够生成听起来与真实人类语音几乎相同的音频深度伪造语音。这使得人类听众、自动说话人验证 (ASV) 系统和深度伪造检测工具难以识别真实语音和深度伪造语音之间的区别[15,12].这些音频深度伪造已被用于严重威胁,例如身份欺诈、错误信息活动和高影响力的社会工程攻击。
由于免费或廉价的语音克隆工具的可访问性,这种威胁进一步放大,这些工具需要最少的技术专业知识来执行模拟。这些工具通常需要一个人几秒钟声音的简短语音样本,以复制他们的语气、音调、口音和说话风格。最近的报告[23]显示,受身份欺诈影响的公司中有 37% 是使用 AI 生成的语音克隆作为目标的,这使得音频深度伪造成为最常见的冒充攻击类型。根据 IBM 的最新报告和 2024 年身份欺诈调查[8],与 deepfake 相关的欺诈企图增加了 3,000%,凸显了对有效且可靠的音频深度伪造检测 (ADD) 方法的迫切需求。
为了应对这一日益增长的威胁,研究界开发了各种 ADD 系统[24,7,14,2,13,3,16]依赖于深度学习和特征表示来识别合成音频伪影,如图 LABEL:fig:intro_a 所示。尽管大多数基于深度学习的 ADD 方法在已知数据集和生成方法上表现出强大的性能,但它们通常无法推广到看不见的数据。更关键的是,大多数 ADD 极易受到反取证 (AF) 攻击,这些攻击会给欺骗检测模型带来微小的、通常难以察觉的扰动,如图 LABEL:fig:intro_b 所示。这些攻击不仅损害了 ADD 方法的完整性,还引发了人们对它们在实际应用中的实际部署以对抗音频深度伪造的担忧。
尽管在图像领域已经探索了几种防御策略[30]和[31]取证、关于防御 ADD 方法免受 AF 攻击,特别是生成 AF 攻击的研究仍然有限。因此,现有文献缺乏对 AF 攻击将如何影响 ADD 系统的重要研究。一些值得注意的研究[11,35]已经开始解决这一差距。例如,Kawa 等人。[11]和吴等人。[35]在 AF 条件下检查了基于 ASV 的系统,并引入了空间平滑和对抗训练作为潜在的防御措施。尽管这些努力解决了基于扰动的攻击,但它们忽略了生成式自动对焦攻击。
更具体地说,现有工作[11,35]主要关注对深度伪造的传统基于扰动的自动对焦攻击,不考虑通过生成对抗网络(GAN)生成的生成自动对焦攻击。因此,生成 AF 攻击对 ADD 方法的影响仍然是一个开放且未充分探索的研究领域。据我们所知,这项工作是第一个提出一种防御机制,旨在防止 ADD 方法中的可转移生成 AF 攻击。
在本文中,我们介绍了一种名为SHIELD的新型协作学习框架,以增强ADD方法对生成式AF攻击的鲁棒性。与图LABEL:fig:intro_a所示的传统ADD管道不同,所提出的SHIELD在ADD阶段之前包含防御(DF)生成模型,这有助于输入和输出表示之间的协作学习,如图LABEL:fig:intro_c所示。辅助 DF 生成模型通过重建输入来暴露 AF 伪影,揭示对抗特征。此外,我们还设计了一个基于三元组的模型来捕获真实和自动对焦攻击的音频样本之间的内部和相互依赖关系。这种结构提高了模型在对抗条件下区分真实输入和深度伪造输入的能力。
如图LABEL:fig:intro_c所示,仅依赖图LABEL:fig:intro_a中传统ADD机制的传统方法可能会被AF输入欺骗,而图LABEL:fig:intro_c中提出的方法,通过协作学习得到增强,有效地减轻了这些威胁。本文的主要贡献如下。
- 我们对 ADD 方法引入生成式自动对焦攻击并评估漏洞。
- 我们提出了一种使用协作学习技术的新型防御机制,该机制提高了 ADD 方法对生成性 AF 攻击的鲁棒性。
- 我们应用防御生成和三元组模型,以促进针对 AF 特征的协作学习。
- 我们对 Deepfake 基准数据集进行了全面评估,并证明 AF 攻击显着降低了现有 ADD 方法的性能。相比之下,所提出的防御方法优于现有方法,特别是在缓解生成式自动对焦攻击带来的挑战方面。
本文的其余部分组织如下:第 2 节提供了有关 ADD 方法及其对 AF 攻击的脆弱性的现有文献。第 3 节详细介绍了所提出的协作学习框架,包括防御生成模型和基于三元组的模型的集成,以捕获音频相关性。第 4 节描述了实验设置、数据集、评估指标,并介绍了结果,并讨论了所提出的方法与 SoTA 方法相比的有效性。最后,第 5 节结束了本文,并提出了未来研究的方向。
2相关作品
本节概述了现有的 ADD 方法,重点介绍了在识别其对 AF 攻击的脆弱性方面取得的进展,并讨论了为应对这些挑战而提出的防御机制。
2.1音频深度伪造检测
ADD 方法通常分为两类:基于手工特征(例如 MFCC、CQCC、LFCC)与高斯混合模型等分类器相结合的传统方法,以及利用深度学习直接从原始或转换后的音频中学习丰富特征表示进行分类的现代方法。
深度学习方法因其对高维音频表示进行建模的能力而受到重视。因此,近年来,大多数ADD系统都采用了深度学习特征提取和分类。例如,Tak 等人。[24]引入了 RawNet2,它通过 CNN 和 GRU 处理原始波形,以在 ASVspoof2019 上实现最先进的性能。尽管消除了手工制作的特征提取,但这种方法对看不见的欺骗技术表现出敏感性。同样,Khan 等人。[14]引入了 SpotNet,这是一种 CNN 模型,它使用针对边缘设备优化的 Mel 频谱图。对此,Khan 等人。[16]后来结合了注意力机制来识别合成语音中的帧级不一致,实现了对最近的部分深度伪造数据集(如 HalfTruth)的稳健检测。
进一步的进步侧重于利用预训练模型来提高泛化和鲁棒性。例如,Zhang 等人。[39]使用预训练的 rawboost 和 wav2vec-XLS-R 进行 ADD,这减少了对标记数据的依赖并提高了泛化性。同时,Grinberg 等人。[4]和 Lim 等人,[19]集成了显著性图和 Grad-CAM 等可解释性技术,以支持法医分析。Wu 等人。[36]通过 CLAD 解决非对抗性作,CLAD 是一种对比学习框架,可最大限度地降低对音量变化和噪声注入的敏感性。鉴于为了保护内容隐私,Li 等人提出了 SafeEar[18],这是一个将语义和声学信息解耦的框架,仅使用声学提示进行检测。
作为对这些努力的补充,融合了手工制作和学习特征的具有多特征融合的混合模型在泛化方面显示出可喜的结果。例如,Yang 等人。[37]提出了一个集成手工和基于学习的功能的系统,实现了更好的跨数据集泛化。同样,Ahmadiadli 等人。[17]通过结合手工制作和神经特征,同时明确建模特定于伪造的伪影而不是说话人的特征,引入了一个独立于身份的检测系统,这被证明可以有效地抵御以前看不见的欺骗攻击。
尽管最近取得了进展,但许多 ADD 系统仍然与特定数据集紧密耦合,并且在真实世界或对抗条件下会失败。这突出了对具有更强泛化和稳健性的模型的需求。我们的工作通过引入一个集成可转移对抗性签名的检测框架来解决这一差距,从而实现更具弹性和适应性的 ADD。
2.2音频 Deepfake 检测的漏洞
尽管 ADD 系统已经有了很大的改进,但它们仍然容易受到对抗性攻击,这些攻击会引入难以察觉的扰动(通常低于 -30 dB SNR),从而纵决策边界,同时为人类听众保留音频保真度[22].这些攻击暴露了泛化、对信号衰减的稳健性以及对可转移或生成攻击的抵抗力方面的关键漏洞。
最初的漏洞研究侧重于基于梯度的白盒攻击。例如,Kawa 等人。[11]对 ADD 系统(包括 RawNet3)进行了全面评估[24],以对抗白盒和可转移性场景中的对抗性攻击。结果表明,对抗性训练,特别是适应性训练,可以增强模型弹性。然而,该研究[11]主要关注传统的基于扰动的攻击,没有解决更高级的生成对抗策略。
威胁态势随着 Farooq 等人的出现而演变。[32]引入基于可转移 GAN 的对抗性攻击框架。这种方法成功地针对不同的 ADD 系统,显著降低了它们在不同场景中的准确性,并突出了现有防御中的关键漏洞。所提出的基于集成的方法通过利用潜在的空间不连续性实现了 89% 的攻击成功率,即使在强大的检测器中也是如此,这表明对抗性迁移学习可以利用集成模型中的共享漏洞。
在此之后,生成式对抗网络的出现从根本上改变了威胁形势。例如,Rabhi 等人。[22]证明,即使是高级检测器也可以使用基于 GAN 的对抗性攻击有效绕过,从而将检测准确性降低到几乎为零。他们的研究结果强调了对近期对抗性攻击的通用、轻量级防御机制的迫切需求。另一方面,在最近的调查中,频域漏洞已被确定为特别容易被 ADD 系统利用。例如,Zhang 等人。[40]介绍 F-SAT,这是一种频率选择性对抗训练方法,专注于高频组件,这些组件经常被攻击者利用。报告的结果表明,所提出的方法提高了对干净样本和对抗样本的检测精度,从而突出了频域特性在对抗训练中的重要性。
总体而言,这些研究揭示了一个核心局限性:大多数 ADD 系统本质上并不是为了克服对抗性干扰或超出其训练分布而泛化。这表明需要能够将对抗鲁棒性集成到其核心架构中的检测框架。所提出的方法通过将可转移的对抗签名直接引入检测管道来解决这一差距,从而实现更具弹性和自适应的 ADD。
3方法
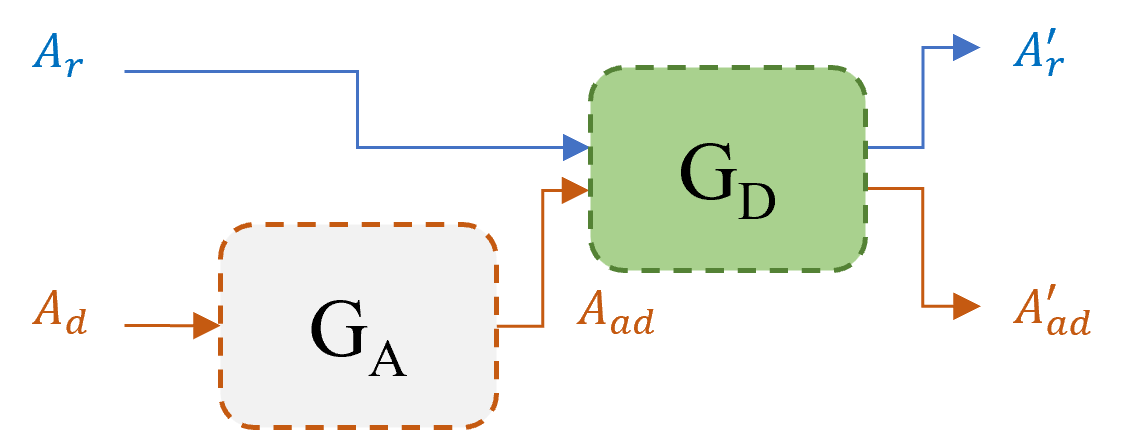
(一)
(二)
图 2:提议的 SHIELD 架构:(a) 深度伪造音频 (一个d)通过 AF (G一个) 模型生成 AF 攻击的 deepfake 音频 (一个一个d).随后,防御 (GD) 模型用于生成实际生成的 (一个r′) 和受攻击生成的 (一个一个d′) 音频。(b) 真实和真实生成的音频 (一个r一个r′),以及被攻击和被攻击生成的音频 (一个一个d一个一个d′)连接在一起,以使用三元组学习捕获判别性特征。输入和输出的集成GD有助于探索它们之间的关系以检测生成 AF 特征。
本节概述了架构概述,包括协作学习、GAN 的训练策略以及拟议防御的三元组学习方法。
3.1问题陈述
生成式人工智能(尤其是 GAN)的快速发展通过创建更逼真的深度伪造音频给 ADD 方法带来了重大挑战。此外,GAN 被广泛用作 AF 攻击,以在不留下视觉签名的情况下更改深度伪造内容并欺骗 ADD 方法。因此,检测生成式自动对焦攻击,尤其是生成模型执行的攻击,变得越来越重要。为了解决这个问题,我们提出了基于协作学习的 SHIELD,旨在防御生成式自动对焦攻击,并采用安全的 ADD 方法来检测受自动对焦攻击的音频。我们集成了 DF 生成模型,以促进协作学习并提供强大的音频攻击检测。由于生成式自动对焦会留下独特的特征,因此在ADD方法之前添加DF生成模型有助于探索真实与真实DF样本以及被攻击样本与被攻击样本之间的相关性,从而实现更好的分离。合并 DF 生成模型背后的假设是,如果样本是真实的并且通过 DF,则原始真实版本和真实 DF 版本之间的相关性将很低,因为它们表现出不同的特征。但是,如果样本受到 AF 攻击,然后通过 DF,则被攻击和被攻击的 DF 版本之间的相关性将很高,因为它们具有相似的特征。
3.2所提方法的架构
图2说明了所提出方法的工作流程和架构,该方法包括两个主要阶段:(a)DF生成模型的集成,如图LABEL:图:arch_a的顶部所示,以及(b)使用三元组模型的协作学习,如图LABEL:fig:arch_b的底部所示。以下小节将介绍详细信息。AF 攻击使用生成模型 (G一个) 生成受 AF 攻击的 Deepfakes(一个一个d) 来欺骗 ADD 方法。在所提出的方法中,我们集成了一个辅助生成模型(GD)作为有助于协作学习的防御模型。在第二阶段,我们使用组合样本通过三元组学习为真实样本和深度伪造样本生成不同的嵌入。
3.2.1协作学习辅助生成模型
假设一个r和一个d分别表示真实音频和{假音频。通常,当使用生成模型 (G一个),它会生成一个受攻击的音频 (一个一个d),其定义如下:

什么时候一个一个d提供给 ADD 方法时,它无法正确地将其识别为深度伪造品,而是将其错误地分类为真实的。
为了防御 AF,我们使用辅助生成模型作为防御 (GD) 生成真实生成的 (一个r′) 和受攻击生成的 (一个一个d′) 音频,定义如下:

和

我们整合一个r一个r′和一个一个d一个一个d′协作学习以区分真实样本和 AF 攻击样本。这里一个r一个r′被认为是真实的,并且一个一个d一个一个d′被视为 AF 攻击样本。如一个r和一个r′具有不同的签名,例如一个r包含真实信息,而一个r′包含自动对焦签名 (GD签名)、之间的相关性一个r和一个r′非常低。相比之下,一个一个d和一个一个d′具有相同的生成式签名,例如一个一个d包含G一个签名,而一个一个d′包含GD签名(两者具有相似的生成签名),之间的相关性一个一个d和一个一个d′非常高。这使得使用深度三元组学习协作来区分真实样本和 AF 攻击样本具有很高的置信度。
3.2.2GAN模型的训练策略
由于重点是对深度伪造音频进行生成式自动对焦攻击以欺骗 SoTA ADD 方法,因此我们使用最小-最大优化技术训练 GAN 模型。在此设置中,生成器的目标是生成受攻击的深度伪造音频,成功逃避检测,而不会显着扭曲其质量。
为了实现这一目标,我们在训练过程中结合了感知损失、对抗损失和替代损失[32,27]如图 3 所示的生成器模型。生成器模型接收来自鉴别器和代理 ADD 方法集合的反馈,并相应地更新其参数以执行 AF 攻击。
我们使用组合损失函数优化发电机网络,定义如下:

哪里Gloss是生成器训练损失。Ploss,一个loss和Sloss是点的L1、二元交叉熵和交叉熵损失。
这Ploss,一个loss和Sloss定义如下:
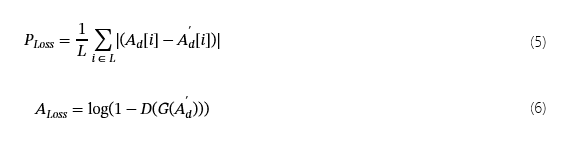
和

判别器模型使用损失函数进行训练,以区分真实和受攻击的 deepfake 音频。此损失函数定义如下:
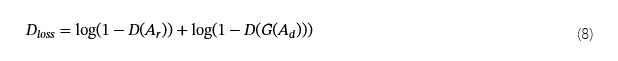
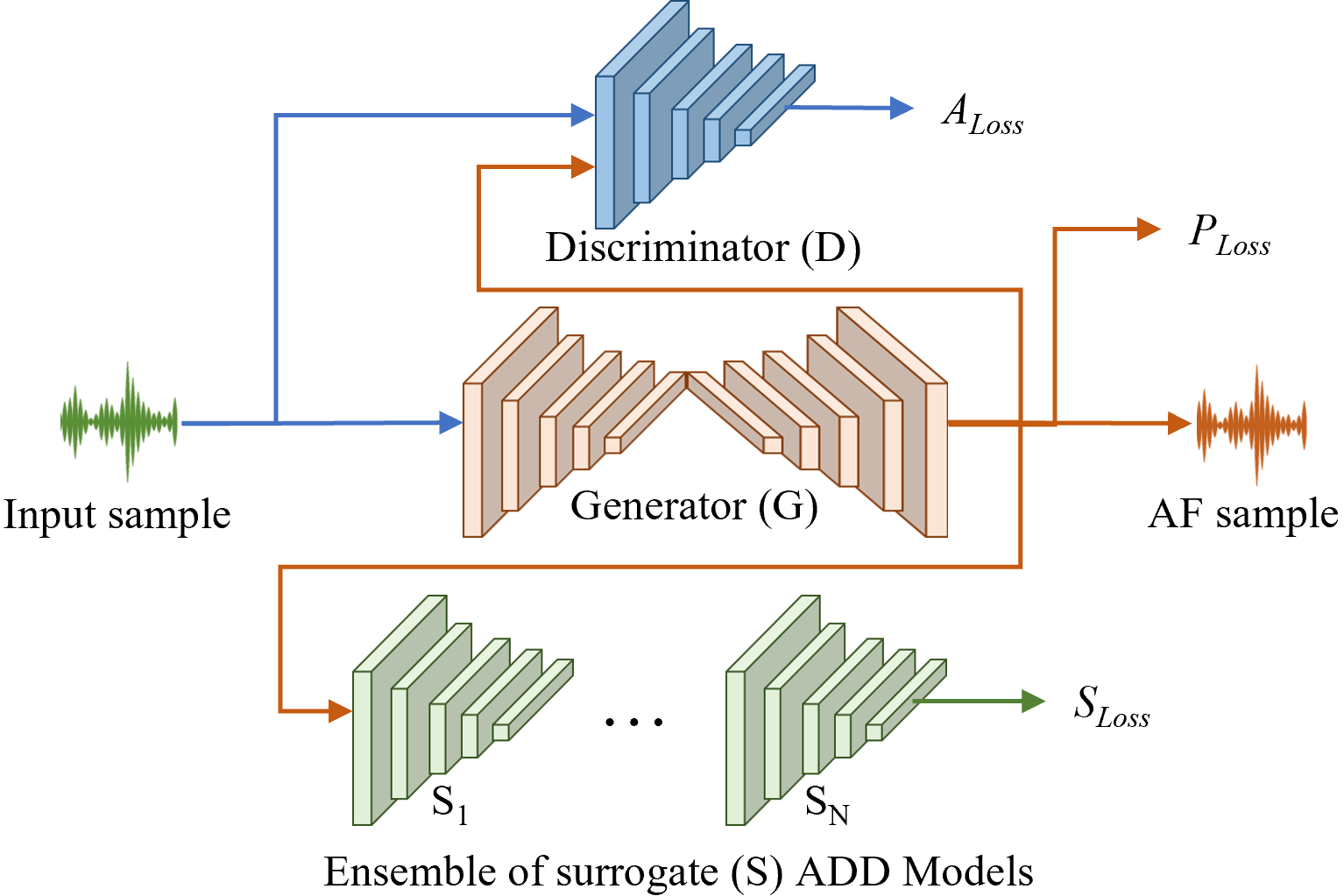
图 3:基于GAN的模型生成针对ADD方法的AF攻击的训练策略。生成器 (G) 网络首先将 AF 应用于输入样本,通过接收来自鉴别器 (D) 和代理 (S) 模型的对抗反馈来欺骗它们来生成 AF 样本。
3.2.3用于生成嵌入的三元组模型
入职后GD,我们连接起来一个r和一个r′将真实音频表示为一个r一个r′.同样地一个一个d和一个一个d′被串联以表示受攻击的音频为一个一个d一个一个d′.随后,我们采用了三元组模型(TM) [5]捕获类内一致性和类间不一致,从而生成区分性特征以进行有效检测。
让F一个,Fp和Fn表示由TM对于锚(一个)、正 (p)和负(n)样本。然后成对欧几里得距离D一个→p之间一个和p和D一个→n之间一个和n计算,定义如下:

和

我们使用保证金排名损失 (Lmr) 训练三元组模型,定义如下:
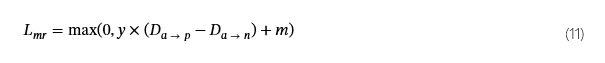
在训练了三元组模型之后,我们设计了一个简单的全连接模型来检测真实音频和被攻击的音频。
4实验

图4:Deepfake的频谱图可视化以及生成的相应攻击样本G1,G2和G3分别。
在本节中,我们将描述实验结果,包括数据集、基线ADD模型的性能、生成式AF攻击的应用以及所提出的防御AF攻击的SHIELD机制。
4.1数据
为了评估基线、AF 和拟议防御的性能,我们使用了三个基准数据集:ASVspoof2019[26]、半真半假[38]和野外[20].这些数据集提供了通过各种语音合成和语音转换技术生成的各种真实和深度伪造样本。
ASV欺骗 2019[26]:ASV恶搞 2019[26]dataset 是一种广泛使用的基准测试,用于评估 ASV 系统中的漏洞。它包括逻辑和物理访问场景,逻辑子集包含使用 17 种不同的 TTS 和 VC 算法生成的 121,461 个音频样本。有关参数化配置的更多详细信息,请参阅[26].
半真半假[38]:HalfTruth 数据集[38]旨在评估对部分音频深度伪造的检测,包含 53,612 个样本,这些样本将来自高级 TTS 和语音克隆技术的合成语音与真实录音混合在一起。它收录了 5,592 名男性和 20,962 名女性的声音,确保了多元化的代表性。更多详细信息可以在[38].
在野外[20]:In-the-Wild 数据集包含从采访、在线媒体和其他真实世界来源收集的真实和合成音频,包括噪声和环境变化。与 ASVspoof2019 不同[26]和 HalfTruth[38],其中包含受控合成语音、In-the-Wild[20]在不受约束的条件下呈现 DeepFake 场景。
4.2实验装置
所有实验均在配备 48GB GPU 内存和 180GB RAM 的高性能 Lambda 服务器上进行,确保高效处理大规模音频数据集。我们使用 PyTorch 作为主要的深度学习框架,利用 CUDA 12.1 在 NVIDIA RTX 6000 ADA GPU 上加速计算。
我们使用交叉熵损失函数训练了 SoTA ADD 方法50 个时期,批次大小为 256,学习率为 0.0001。我们训练 GAN 模型 30 个 epoch,从而产生最佳性能。生成器和判别器的批量大小和学习率分别设置为 32 和 0.0001。此外,我们使用预训练的 ADD 方法作为代理模型的集合。我们将三元组模型训练 50 个 epoch 以实现最佳性能。批量大小和学习率分别设置为 32 和 0.0001。我们应用了混合精度训练来优化训练。我们使用 Adam 优化器优化所有模型。为了提高对看不见的测试集的泛化,我们结合了来自所有三个数据集的训练数据来训练所有模型。
表 2:对 match 设置中建议的防御机制的评估。
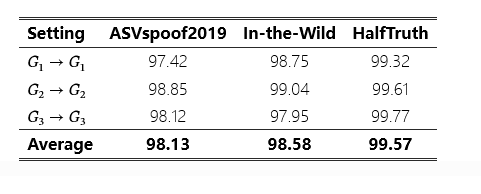
表 3:在不匹配设置中评估建议的防御机制。
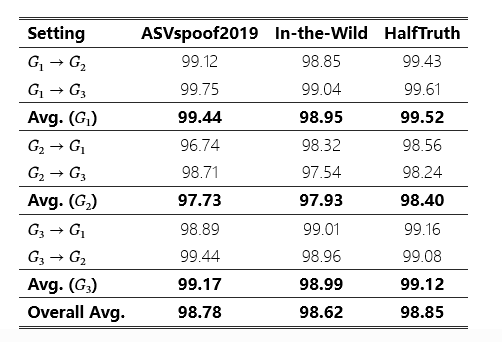
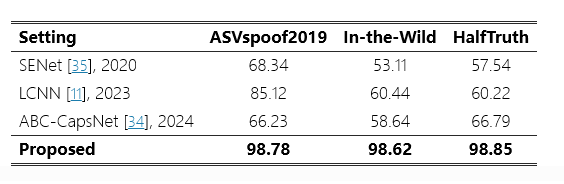
表4:所提方法与SoTA防御机制的性能比较。
4.3性能评估和比较
本节详细评估了基线 ADD 方法、AF 攻击以及针对 AF 攻击的建议 SHIELD。
4.3.1基准数据集的基线深度伪造检测和反取证攻击结果
我们选择了七种SoTA ADD方法,包括RawNet3[10]、原始网络2[24]、原始增强[25]、Res-TSSDNet[7], Inc-TSSDNet[7]、ResNet[6]和 MS-ResNet[33],以评估基准深度伪造数据集的基线性能和 AF 攻击。这些方法代表了最先进的检测技术,利用原始波形和基于频谱图的分析来暴露音频不自然。
表 LABEL:base_performance 显示了 ADD 方法在三个不同数据集中的基线性能,例如 ASVspoof2019、In-the-Wild 和 HalfTruth。结果表明,这些ADD方法有效地区分了真实和深度伪造的音频样本,在ASVspoof2019上的平均准确率分别达到95.49%、在In-the-Wild上和98.41%的HalfTruth上的平均准确率。
为了对 ADD 方法进行自动对焦攻击,我们探索了用于音频处理的 SoTA GAN 模型,并微调了三个架构上不同的模型:G1(UNet)[1],G2(塞根)[21]和G3(奥旺)[9].这些模型是根据其多样化的架构以及在语音合成和增强方面的有效性来选择的,使其适用于自动对焦攻击。
表 LABEL:base_performance 中所示的攻击结果显示 ADD 检测性能显着下降。具体来说,ASVspoof2019 的平均准确率分别下降到 59.84%、70.36% 和 49.10%;野外 34.65%、35.75% 和 44.95%;使用 HalfTruth 时分别为 76.75%、49.10% 和 27.70%G1,G2和G3分别。这些结果表明,现有的ADD方法容易受到对抗性扰动的影响,凸显了需要采取更强有力的对策。
4.3.2针对生成式 AF 攻击的拟议 SHIELD 的性能评估
我们进行了两个设置来评估拟议的 SHIELD 对生成式 AF 攻击的影响。首先,匹配场景,其中攻击 (G一个) 和防御 (GD) 使用如图 2 所示的相同生成器模型。第二种是不匹配场景,其中攻击 (G一个) 和防御 (GD) 使用不同的生成器模型。原始网络 3[10]用作我们的三元组模型中的嵌入网络,以协作学习判别特征。它的选择是由于与 SoTA 方法相比具有卓越的性能,如表 LABEL:base_performance 所示。
match 设置中的防御结果如表 2 所示,其中我们使用相同的 GAN 模型来应用 AF 攻击并防御它们,例如G1→G1,G2→G2和G3→G3.所提出的方法对 ASVspoof2019 的平均检测准确率分别为 98.13%、In-the-wild 和 HalfTruth 数据集的 99.57%。这证实了所提出的 SHIELD 可以有效地检测已知的针对深度伪造的生成 AF 攻击,并为 ADD 方法提供了强大的解决方案。
表 3 总结了所提出的 SHIELD 机制在失配设置中的检测性能。在失配设置中,我们使用三个 GAN 模型的不同组合,例如G1→G2,G1→G3,G2→G1,G2→G3,G3→G1和G3→G2以评估性能。与比赛设置类似,该方法在对抗深度伪造的未知 AF 攻击方面表现出很强的有效性。拟议的 SHIELD 在 ASVspoof2019 中实现了 98.78% 的总体平均准确率,在 In-the-Wild 中达到了 98.62%,在 HalfTruth 数据集中实现了 98.85% 的总体平均准确率。与基线 ADD 方法相比,所提出的防御措施在任一情况下在缓解生成式 AF 攻击方面都取得了卓越的性能。
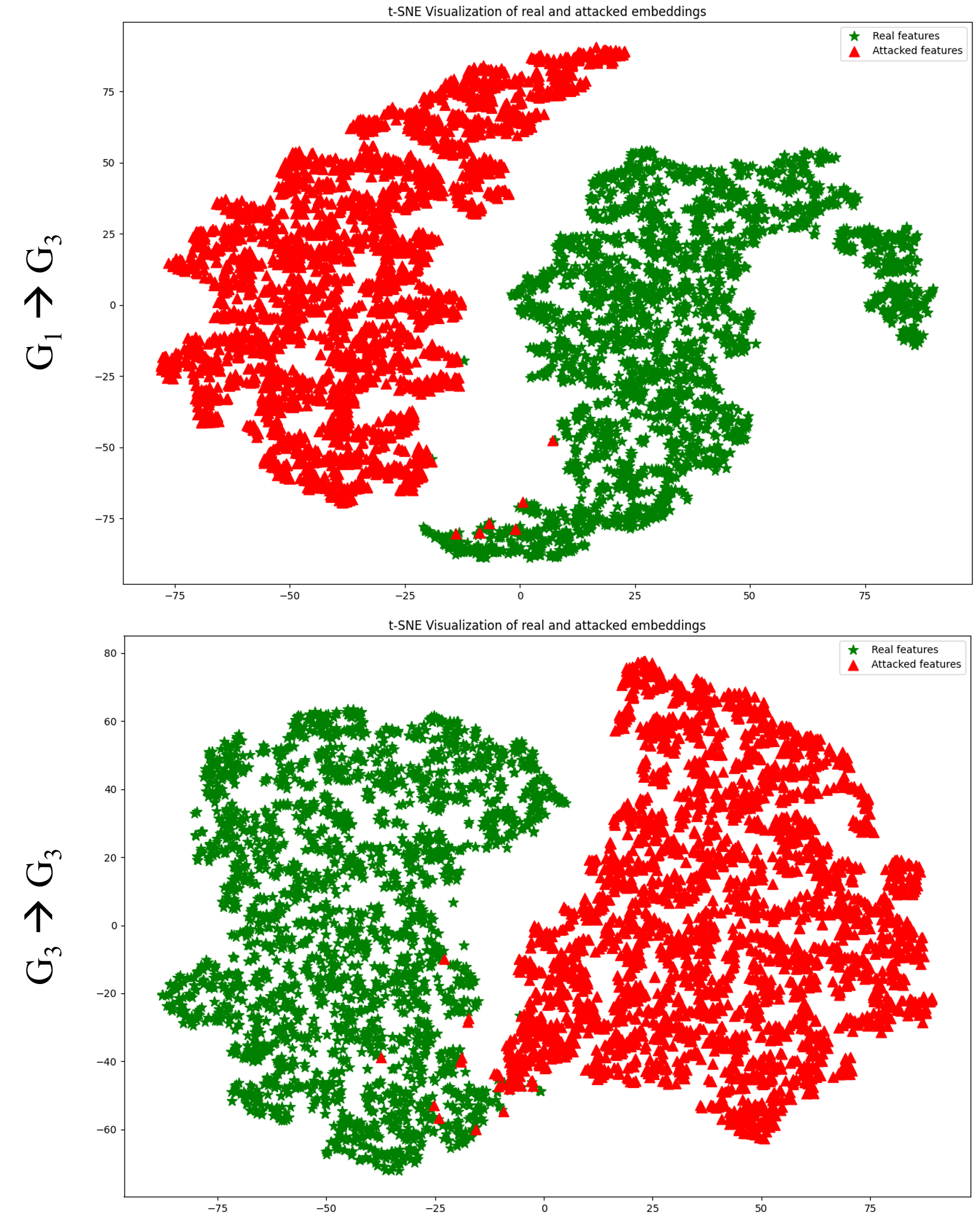
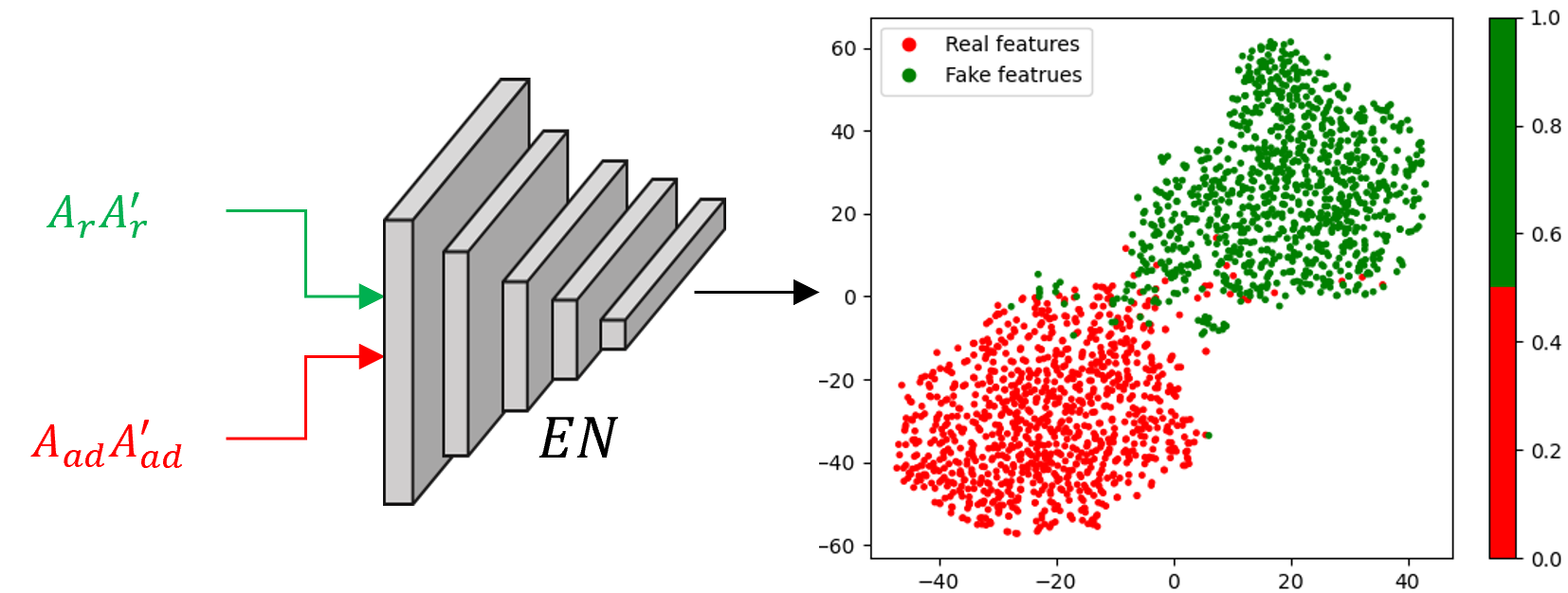
图 5:三元组模型生成的半真值数据集嵌入的 t-SNE 可视化。
4.3.3性能比较
我们将所提出的 SHIELD 与 SoTA 防御机制(例如 ABC-CapsNet)进行了比较[34], LCNN[11]和 SENet[35].我们计算了 SoTA 防御的平均鲁棒性结果G1,G2和G3分别。表4比较了所提出的SHIELD与三种SoTA方法的检测结果。所提出的 SHIELD 比 SENet 提高了 30.44%、45.51% 和 41.31%,优于现有防御方法;比 LCNN 高出 13.66%、38.18% 和 38.63%;在 ASVspoof2019、In-the-Wild 和 HalfTruth 数据集上,ABC-CapsNet 分别为 32.55%、39.98% 和 32.06%,表明 SHIELD 在 AF 攻击下始终超越这些 SoTA 防御。
4.4消融研究
在我们的实验和分析中,我们采用了三种GAN模型来执行AF攻击。为了更好地理解,我们将深度伪造和AF攻击样本的光谱特征可视化,如图4所示,以促进比较质量评估。可视化表明,区分深度伪造和 AF 攻击样本给人类感知带来了重大挑战。此外,这种 AF 攻击巧妙地规避了 SoTA ADD 方法,凸显了它们的功效和当前检测技术的固有局限性。
为了说明三元组模型的有效性,我们在图5中展示了t-SNE表示,利用RawNet3[10]在 HalfTruth 数据集上。具体来说,我们显示了G3→G3(bottom) 匹配和G1→G3(顶部)不匹配配置。可视化清楚地表明,三元组模型有效地将真实样本和AF攻击样本聚类,使它们易于区分。
5结论和未来工作
生成模型的革命使得生成更逼真的深度伪造成为可能,而无需留下任何视觉线索来将其与真实样本区分开来。因此,已经提出了几种 ADD 方法来检测生成签名以揭示深度伪造。 尽管 ADD 取得了进步,但这些方法仍然容易受到生成式 AF 攻击。为了解决这个问题,我们引入了一种新颖的 SHIELD 机制,该机制将辅助生成模型作为协作学习框架中的防御。通过利用三元组学习,我们的方法有效地捕获了深度伪造音频中的生成特征,从而提高了匹配和不匹配场景下基准数据集的检测性能。
虽然我们的方法有效地对抗了生成式自动对焦攻击,但未来的工作将把其适用性扩展到更广泛的对抗性威胁,例如扩散、滤波和其他技术,如噪声注入攻击、时频纵和时间攻击。此外,集成多模态分析可以增强稳健性,因为对抗技术通常针对音频或视频数据等单个模态。


















 2478
2478

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









