




C++STL库探究
STL即标准模板库,封装了一些常用的数据结构和算法
它的价值是从小来说,给用户直接提供了一套高效的算法接口,并且让算法和数据容器分离,让算法变成不依赖数据类型,不依赖存储结构的逻辑代码。大的来说它将抽象概念通过泛型技术描述出来,对于庞大的系统利用组件分层设计。
六大组件
容器通过空间配置器获得存储空间,算法利用迭代器获取容器内容,仿函数协助算法完成不同策略变化,适配器可以修饰仿函数和容器。
容器:利用数据结构,线性树形哈希,来存储数据
算法:利用迭代器实现和数据结构无关的代码,或者依赖容器的算法
迭代器:容器和算法之间的胶水,算法看到统一的++, –遍历方法,容器有自己的遍历方式
空间配置器:提高零碎内存分配效率,解决内存碎片,防止空间浪费。
仿函数:比如在算法中需要更加普通化,sort函数需要传入定制的比较规则,把比较规则封装成类,再重载(),之后可以通过无名对象方式调用仿函数得到结果。
适配器:修饰仿函数时,根据语义需求创造出灵活的表达式供算法使用。修饰容器,直接封装其接口,像stack封装deque。
空间配置器
在容器背后默默奉献的角色,因为C++本身的动态内存分配机制不够高效并且有内存碎片问题,所以诞生了空间配置器。它不仅可以分配内存空间,甚至可以索取硬盘空间。
它把原先new和delete的两个阶段分开设计,分配空间是alloc,构造对象是construct,还有填充函数用于内存填充/拷贝/移动。
重点研究的是分配空间的alloc模块。
alloc分配内存采用两级设计,避免了内存碎片的问题。大于128字节直接用一级配置器向系统堆空间申请内存,小于128字节使用二级配置器,利用内存池和自由链表管理内存。
内存池配合16个自由链表,8,16…128字节的内存块挂在链表上,类似哈希筒的方式管理回收内存。
模型:
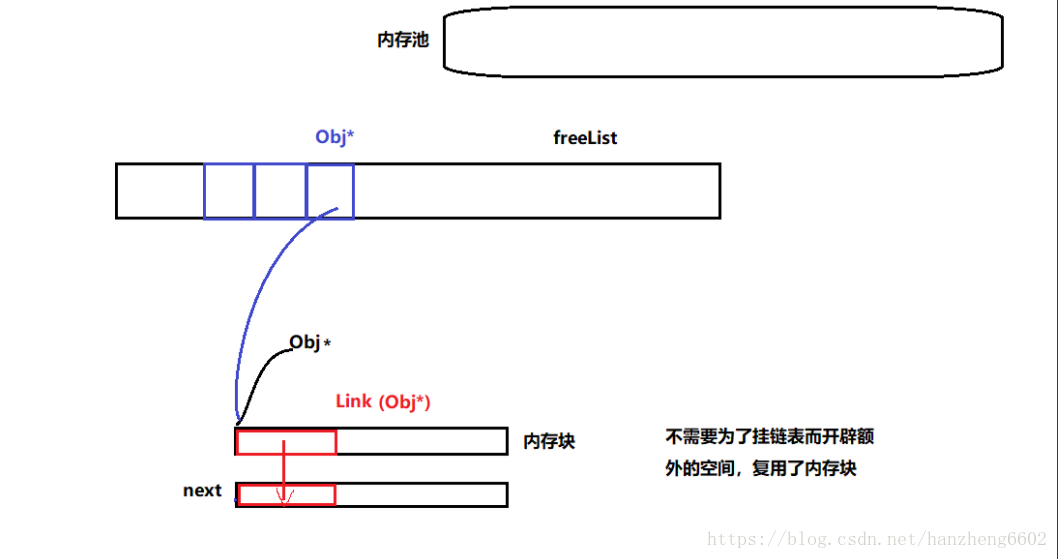
分配一块空间的流程:

回收内存?
用户申请时可以用定位new,用完了空间不是直接malloc返回给系统,而是调用Deallocate,把用完的空间挂在对应了freelist链表底下。
这样在频繁申请释放的场景下,不需要再去向系统申请空间,而是直接取链表底下挂的空间,提高了效率。在release下大约有10倍时间上的差距。
线程安全?
模板参数列表有开启线程的开关,若定义了多线程使用,就在向操纵某一个freelist下标的链表之前加锁,当其他线程取不同字节的空间是不会触发锁的,因此能减小锁竞争力度,释放也一样。在操纵内存池时加入单独的互斥锁。
不管是几级配置,给用户使用的都是同一的一个alloc接口,透明!
迭代器
迭代器是实现容器,算法泛化的重要组件。在容器内部提供迭代器的实现,在算法层面直接去应用迭代器,算法看到的是统一的 ++, – , == 这些操作。而本质上是在容器里对指针进行了运算符重载。
vector底层是连续的地址空间,所以原生指针就可以胜任迭代器。
list的迭代器把链表的遍历方式封装为++,–。
迭代器失效?
vector只要引起空间重新配置,原有迭代器都设置无效。
/*例如执行这样的代码*/
vector<int> v = {1, 35,54,2,3};
for(auto it = v.begin(); it != v.end(); it++){
if(i++ < 2)
v.erase(it);
}
//抛出迭代器失效的异常,it在删除指向元素之后就无效了
//erase的实现是这样的,利用erase的返回值重新复制it
iterator erase(iterator position){
if(position +1 != end()){
copy(position +1, finish, position);//拷贝
}
--finish;
destory(finish);
return position;
}
//正确的姿势
for (auto it = v.begin(); it != v.end(); ) {
if(i++ < 2)
it = v.erase(it);
else{
it++;
}
}总结:迭代器失效分三种情况考虑,分别为数组型,链表型,树型数据结构。
数组型数据结构:该数据结构的元素是分配在连续的内存中,insert和erase操作,都会使得删除点和插入点之后的元素挪位置,所以,插入点和删除掉之后的迭代器全部失效。
解决方法:erase(*iter)的返回值是下一个有效迭代器的值。 iter =cont.erase(iter);
链表型数据结构:对于list型的数据结构,使用了不连续分配的内存,删除运算使指向删除位置的迭代器失效,但是不会失效其他迭代器.解决办法两种,erase(*iter)会返回下一个有效迭代器的值,或者erase(iter++).
树形数据结构: 使用红黑树来存储数据,插入不会使得任何迭代器失效;删除运算使指向删除位置的迭代器失效,但是不会失效其他迭代器.erase迭代器只是被删元素的迭代器失效,但是返回值为void,所以要采用erase(iter++)的方式删除迭代器。
仿函数
仿函数就是重载了类的(),让其使用着像函数一样。一般是通过无名对象传参,或者函数指针也是狭义的仿函数。
仿函数可以实现智能指针的删除器,可以实现算法的灵活性。
bubble_sort
template<typename T>
class Great {
public:
bool operator()(const T& left, const T& right) {
return left > right;
}
};
template<typename T, typename Com>
void bubble_sort(T* arr, int size, Com cmp) {
bool flag = true;
for (int i = 0; i < size - 1; i++) {
flag = true;
for (int j = 0; j < size - 1 - i; j++) {
if (cmp(arr[j], arr[j + 1])) {
swap(arr[j], arr[j + 1]);
flag = false
}
}
if(flag){
return;
}
}
}
void test_bubble() {
int arr[] = { 5,6,8,7,9 };
//传入无名对象,在算法里可以直接当函数调用
bubble_sort(arr, sizeof(arr) / sizeof(arr[0]), Great<int>());
}容器
C++有三个重要的顺序容器,vector,list和deque。顺序是指容器内的元素可以被按序排列。
关联容器主要为了查询元素是否存在,并且获取元素。有map和set。
选择vector ,list ,deque ?
在c语言中根据元素个数是否确定就能决定使用array或者list。但是对于顺序容器,都是动态增长的,主要准则是关注插入和访问特性。
vector 封装的是数组,是一段连续的内存空间,因此任意插入和删除效率很低,插入的话需要先把后续元素向后搬移,是On的复杂度。但是随机访问性很好。
list 封装了带头节点的双向循环链表,非连续地址空间,插入删除只需要调整前后结点指向,是O1的复杂度。但是不支持随机访问,每个结点还有额外的指针空间开销。
deque 是逻辑上的连续空间,但底层是许多连续空间拼接起来的,虽然支持随机访问,但是开销很大,只有在对容器头尾操作才有优势。
vector实现细节
关键技术是增容时机,SGI版本在插入元素之前先判断容量是不是满了,若满则开辟两倍大的空间,搬移元素到新空间,释放旧空间。
开辟新空间不一定在原来的地址上,因为不能保证原空间后有足够大的新空间,意味着原来的迭代器失效。
数据结构用三个迭代器,start ,finish,end分别指向已用空间,未用空间,空间末尾。迭代器是直接封装了数据类型的指针,因为指针完全胜任对连续空间的操作。
vector没有提供方法使容量减小,可以通过创建tmp对象,swap的小手段。
list实现细节
list封装的就是带头节点双向循环链表,所以它的实现都是基于链表的操作。
它的迭代器比较特殊,由于是非连续地址空间,迭代器必须支持++,–的操作。这需要对指针再次封装,定义它的++–操作。
deque和vector的差异
- deque在头端操作时间复杂度可以达到O1
- deque没有vector的容量概念,随时拼接上连续的空间,没有原空间不足搬移元素三步骤,扩容性比vector好,代价是迭代器复杂了
- 随机访问的性能要比vector差
排序deque元素可以先将元素复制到vector中,在vector中排序后复制回deque。
关联容器
关联容器是为了提高元素查询效率诞生的,存放结构变成了key-value。一种基于红黑树,一种基于哈希。
map,set,multi系列,由于底层是红黑树,所以是有序的,但是不能修改结点元素会破坏树的性质。键值必须是可比较,不可变,可拷贝的对象,这是创建红黑树结点的要求。
unorder系列基于哈希,为了进一步提高查询效率,哈希结构决定了它的无序性。
关联容器和序列容器的差异
- 查询的效率,逐个比较——key和地址绑定
- 无序存放,空间浪费
- 哈希筒方式的哈希冲突处理

















 2938
2938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









