



1.事务的概念
事务(Transaction)通常的定义是:作为单个逻辑单元执行的一组操作,要么全部执行,要么全部不执行。它有四个明显的特征:
原子性(Atomicity): 一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被恢复(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样
一致性(Correspondence): 在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
隔离性(Isolation):数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
持久性(Durability):事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
简称ACID
2.mysql的实现(InnoDB)
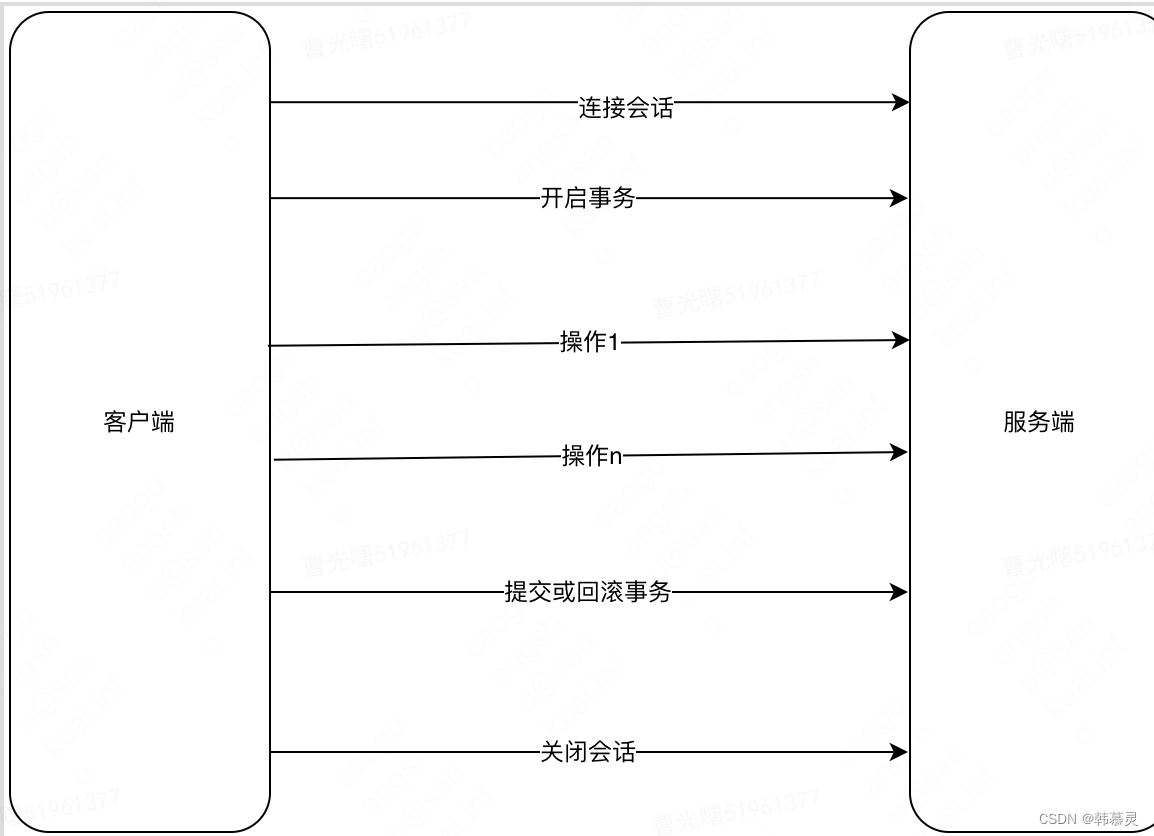
a.mysql事务执行流程
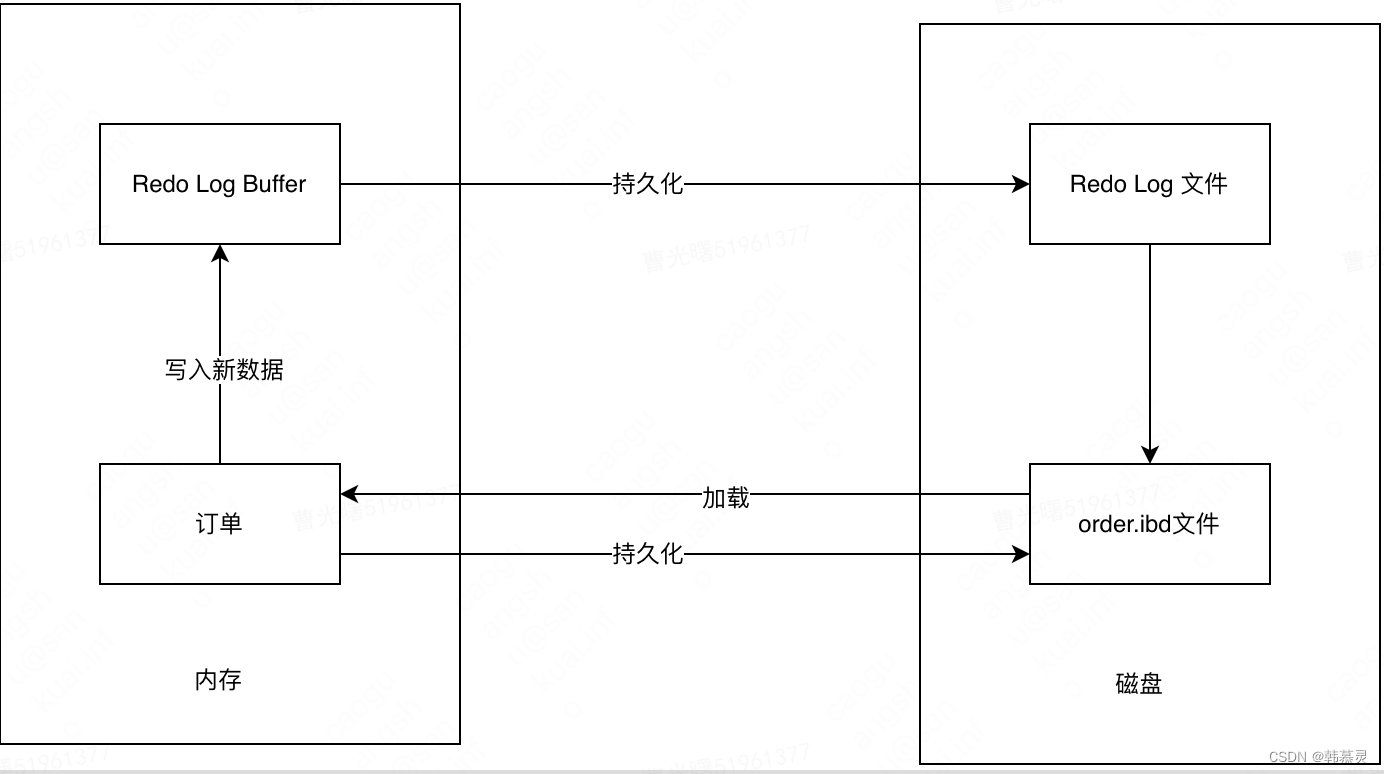
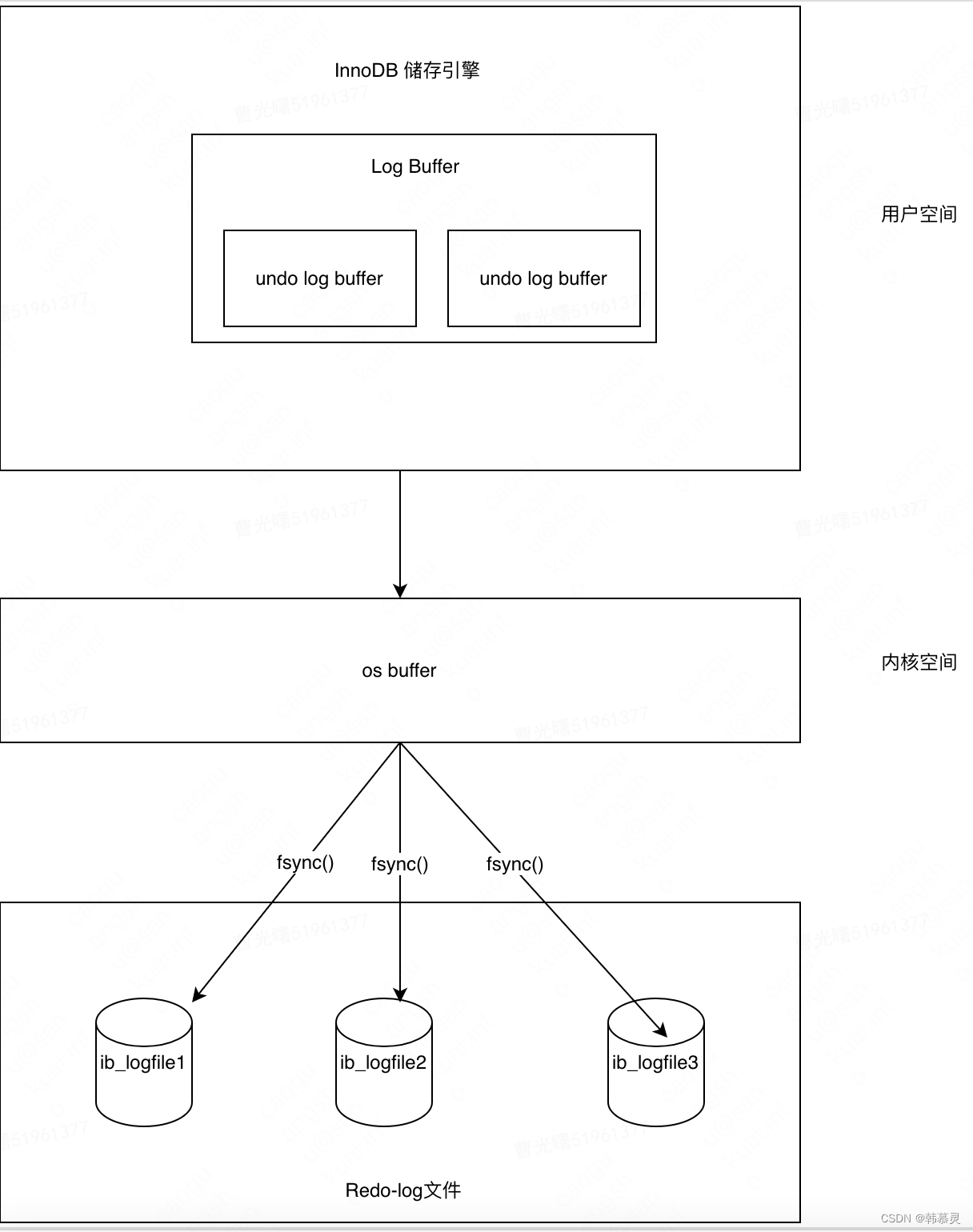
b.RedoLog (重做日志)实现原子性和持久性
1.RedoLog 保证了mysql的事务的原子性和持久性,redolog 主要记录物理日志,也就是说,对磁盘的数据进行的修改操作.
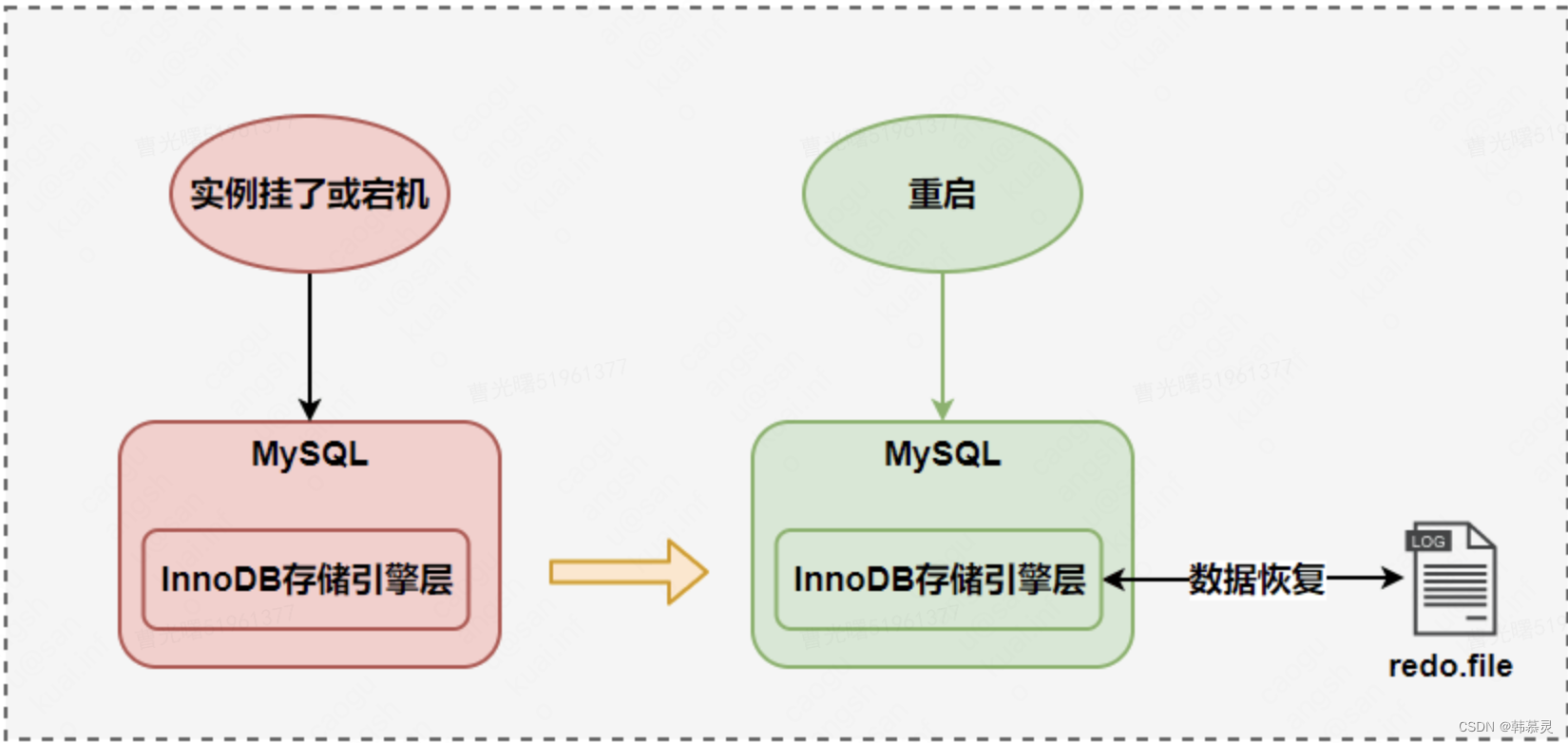
2.redo的刷盘规则
1) 开启事务,发出提交事务指令后是否刷新日志,由变量 innodb_flush_log_at_trx_commit 决定
2)每秒钟刷新一次,刷新日志频率由 innodb_flush_log_at_timeout 值 决定,默认1s.
3) 当事务存在checkpoint 的时候,在一定程度上代表了刷鞋到磁盘的日志所处的LSN的位置。其中LSN(Log sequence Number) 标识日志的逻辑序列号。
刷新Redo 日志的方式由innodb_flush_log_at_trx_commit 决定的
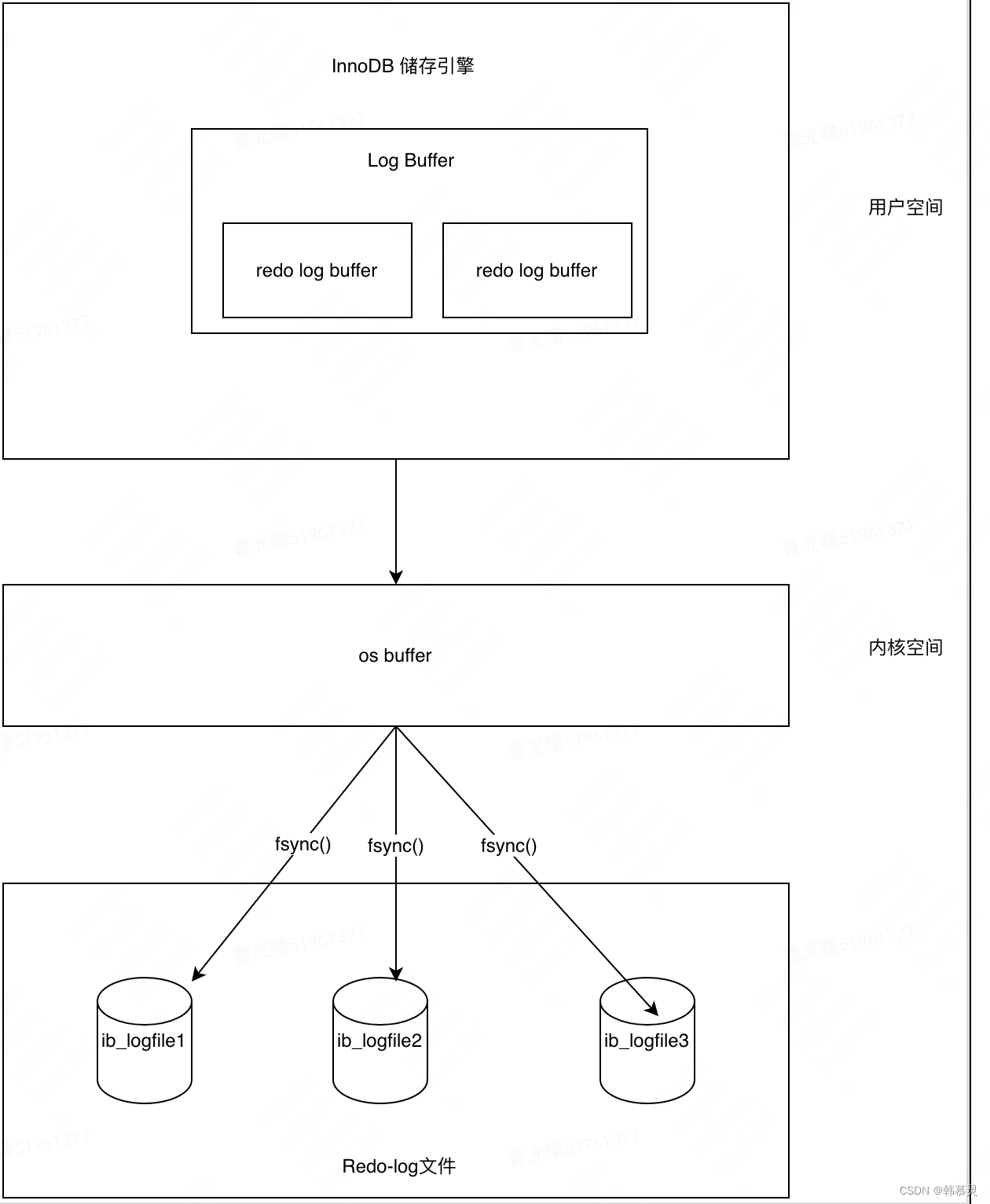
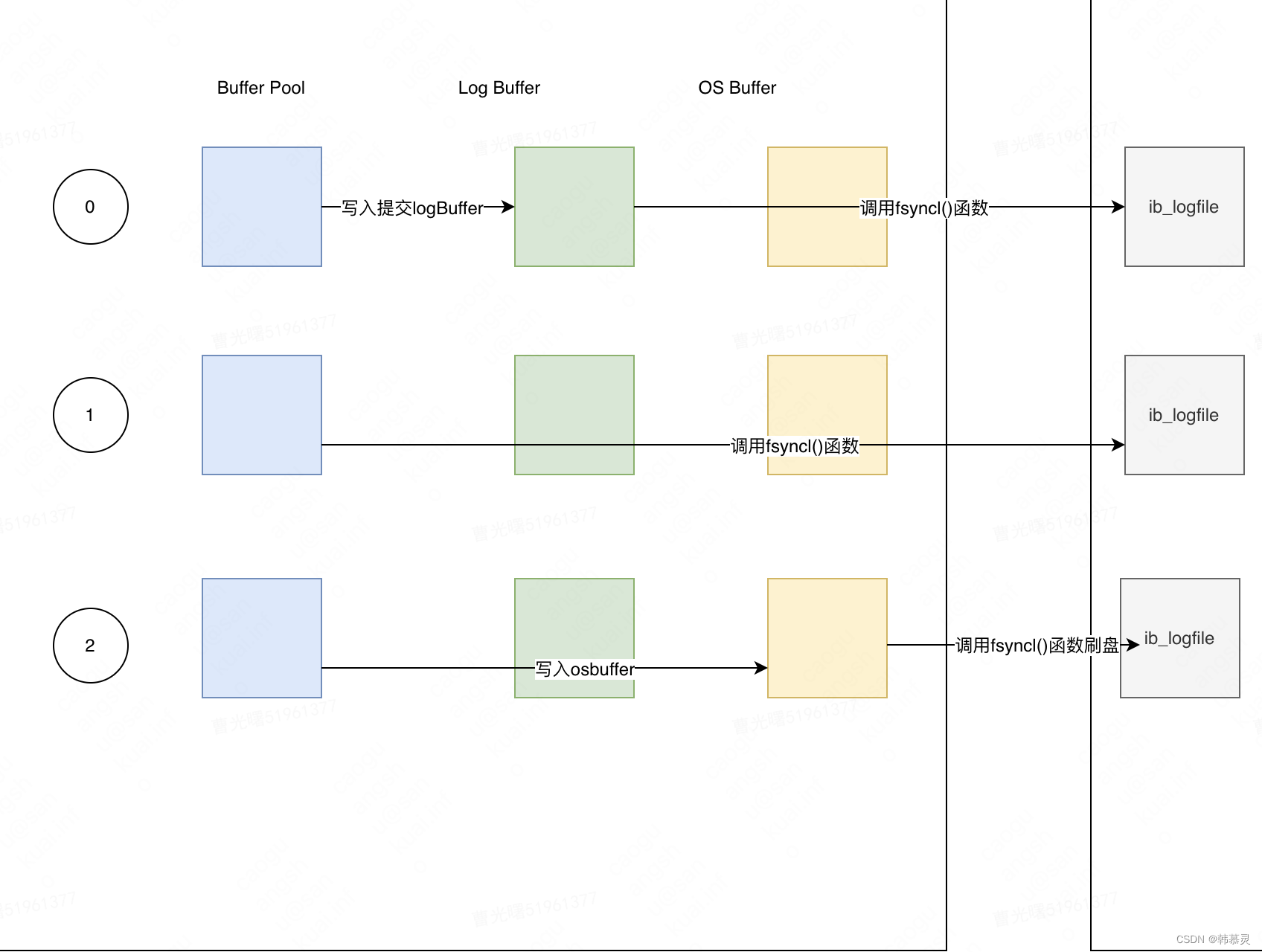
1.如果innodb_flush_log_at_trx_commit 变量设置为0,则每次提交事务的时候,不会将log buffer 中的日志写入os buffer,而是通过一个单独的线程,每秒写入OS Buffer
并且调用 fsync() 函数写入磁盘的Redo log 文件。这种方式不是实时的写入磁盘,是每隔1s 写入一次日志,如果系统崩溃,会丢失1s 数据。
2.如果该变量设置为1,则每次提交事务都会将Log Buffer的日志写入OS buffer,并且会调用fsync()函数写入磁盘的Redo Log 文件中,这种系统崩溃不会丢失数据,但是性能比较差
3.如果变量设置为2,则每次提交事务的时候,都只是将 数据写入OS buffer,之后1s,通过fsync() 函数同步到Redo Log 中
C.UndoLog 实现一致性
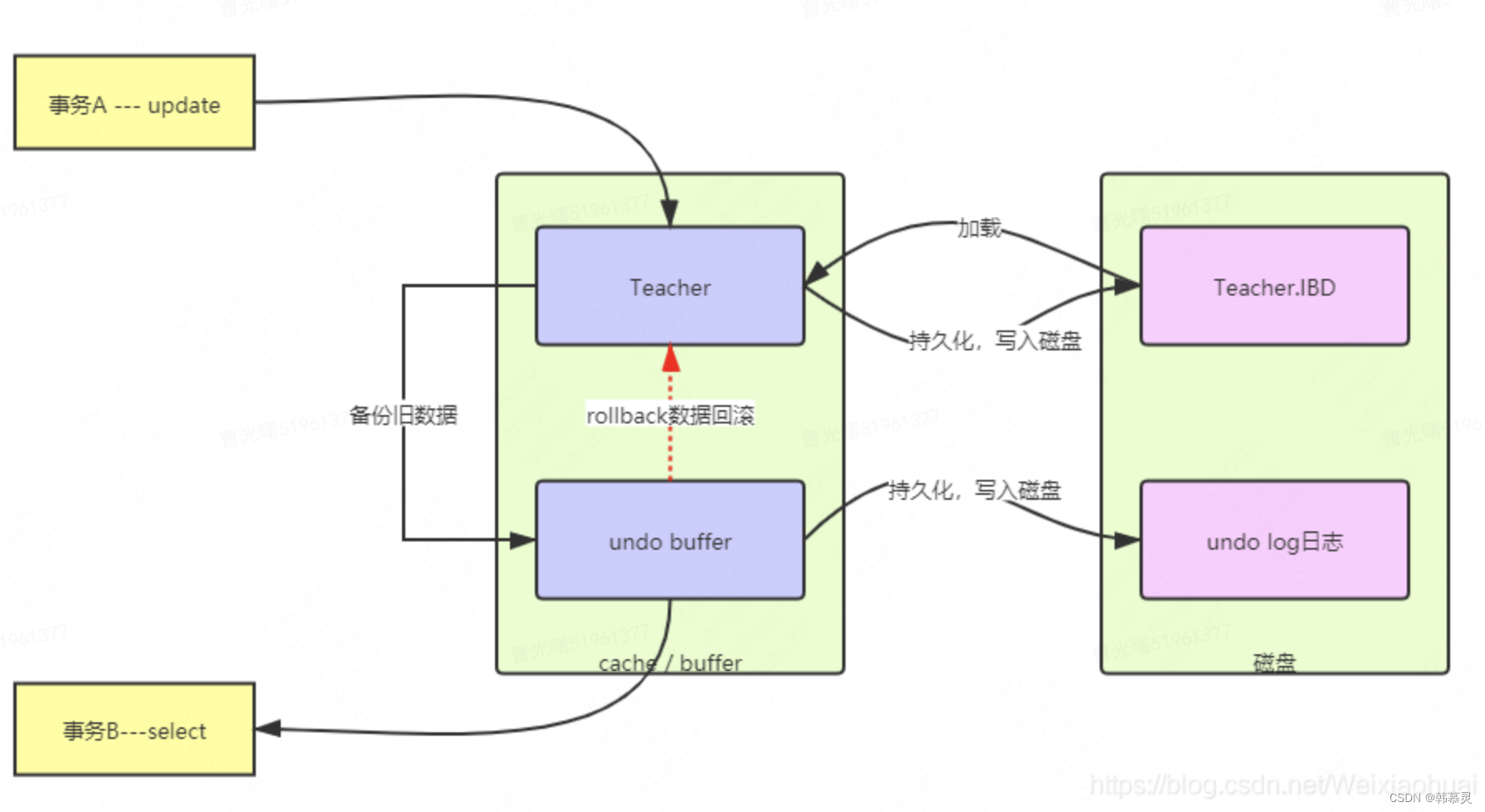
Undo Log 给mysql的mvcc 提供了支持, Undo log 主要做用是当事务回滚时用于将数据恢复到修改前的样子。提供的日志记录是和当前执行的sql语句语义相反的日志。
Undo Log 在mysql中主要起到了两方面的作用: 回滚事务,以及多版本的并发事务,为MVCC提供支持。
Undo Log 在事务开始之前产生,当事务提交的时候,并不会立刻的删除相应的Undo Log,此时,InnoDB 储存引擎会将当前事务对应的UnDolog 放入待删除的列表,接下来通过后台线程 purge thread 进行删除处理。
Undo Log 刷盘规则
D.MVCC 实现隔离性
a.快照读和当前读
通常做法是加一个版本号或者时间戳字段,在更新数据的同时版本号 + 1 或者更新时间戳。查询时,将当前可见的版本号与对应记录的版本号进行比对,如果记录的版本小于可见版本,则表示该记录可见
MVCC 的实现依赖于:隐藏字段、Read View、undo log。在内部实现中,InnoDB 通过数据行的 DB_TRX_ID 和 Read View 来判断数据的可见性,如不可见,则通过数据行的 DB_ROLL_PTR 找到 undo log 中的历史版本。每个事务读到的数据版本可能是不一样的,在同一个事务中,用户只能看到该事务创建 Read View 之前已经提交的修改和该事务本身做的修改
在内部,InnoDB 存储引擎为每行数据添加了三个 隐藏字段open in new window:
-
DB_TRX_ID(6字节):表示最后一次插入或更新该行的事务 id。此外,delete 操作在内部被视为更新,只不过会在记录头 Record header 中的 deleted_flag 字段将其标记为已删除
-
DB_ROLL_PTR(7字节) 回滚指针,指向该行的 undo log 。如果该行未被更新,则为空
-
DB_ROW_ID(6字节):如果没有设置主键且该表没有唯一非空索引时,InnoDB 会使用该 id 来生成聚簇索引
-
ReadView 用来做可见性判断,数据结构如下:
class ReadView { /* ... */ private: trx_id_t m_low_limit_id; /* 大于等于这个 ID 的事务均不可见 */ trx_id_t m_up_limit_id; /* 小于这个 ID 的事务均可见 */ trx_id_t m_creator_trx_id; /* 创建该 Read View 的事务ID */ trx_id_t m_low_limit_no; /* 事务 Number, 小于该 Number 的 Undo Logs 均可以被 Purge */ ids_t m_ids; /* 创建 Read View 时的活跃事务列表 */ m_closed; /* 标记 Read View 是否 close */ }
1.m_low_limit_id:目前出现过的最大的事务 ID+1,即下一个将被分配的事务 ID。大于等于这个 ID 的数据版本均不可见
2.m_up_limit_id:活跃事务列表 m_ids 中最小的事务 ID,如果 m_ids 为空,则 m_up_limit_id 为 m_low_limit_id。小于这个 ID 的数据版本均可见
3.m_ids:Read View 创建时其他未提交的活跃事务 ID 列表。创建 Read View时,将当前未提交事务 ID 记录下来,后续即使它们修改了记录行的值,对于当前事务也是不可见的。m_ids 不包括当前事务自己和已提交的事务(正在内存中)

b.undo-log 实现mvcc
-
当事务回滚时用于将数据恢复到修改前的样子
-
另一个作用是 MVCC ,当读取记录时,若该记录被其他事务占用或当前版本对该事务不可见,则可以通过 undo log 读取之前的版本数据,以此实现非锁定读
-
insert undo log :指在 insert 操作中产生的 undo log。因为 insert 操作的记录只对事务本身可见,对其他事务不可见,故该 undo log 可以在事务提交后直接删除。不需要进行 purge 操作
-
update undo log :update 或 delete 操作中产生的 undo log。该 undo log可能需要提供 MVCC 机制,因此不能在事务提交时就进行删除。提交时放入 undo log 链表,等待 purge线程 进行最后的删除
插入数据时候

修改数据时
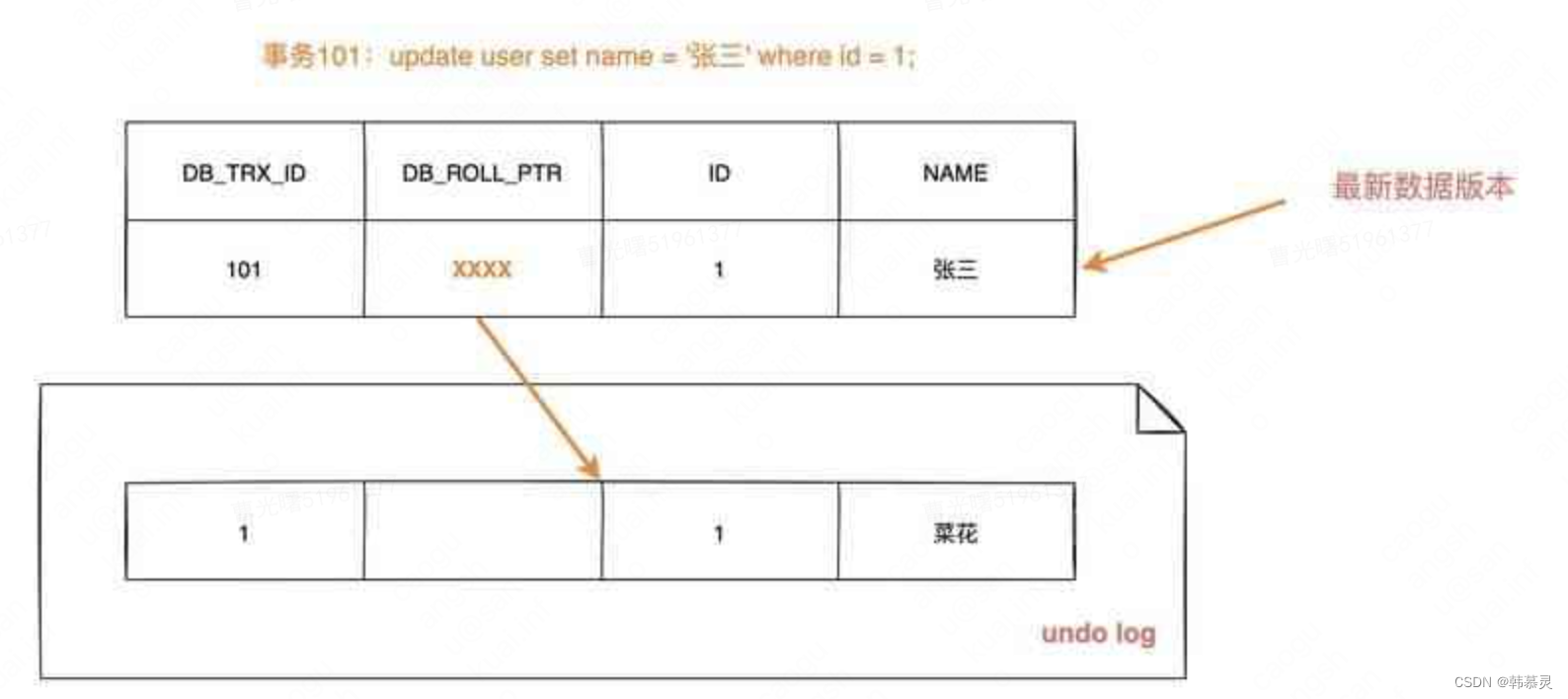
不同事务或者相同事务的对同一记录行的修改,会使该记录行的 undo log 成为一条链表,链首就是最新的记录,链尾就是最早的旧记录。
数据可见性算法
在 InnoDB 存储引擎中,创建一个新事务后,执行每个 select 语句前,都会创建一个快照(Read View),快照中保存了当前数据库系统中正处于活跃(没有 commit)的事务的 ID 号。其实简单的说保存的是系统中当前不应该被本事务看到的其他事务 ID 列表(即 m_ids)。当用户在这个事务中要读取某个记录行的时候,InnoDB 会将该记录行的 DB_TRX_ID 与 Read View 中的一些变量及当前事务 ID 进行比较,判断是否满足可见性条件
-
如果记录 DB_TRX_ID < m_up_limit_id,那么表明最新修改该行的事务(DB_TRX_ID)在当前事务创建快照之前就提交了,所以该记录行的值对当前事务是可见的
-
如果 DB_TRX_ID >= m_low_limit_id,那么表明最新修改该行的事务(DB_TRX_ID)在当前事务创建快照之后才修改该行,所以该记录行的值对当前事务不可见。跳到步骤 5
-
m_ids 为空,则表明在当前事务创建快照之前,修改该行的事务就已经提交了,所以该记录行的值对当前事务是可见的
-
如果 m_up_limit_id <= DB_TRX_ID < m_low_limit_id,表明最新修改该行的事务(DB_TRX_ID)在当前事务创建快照的时候可能处于“活动状态”或者“已提交状态”;所以就要对活跃事务列表 m_ids 进行查找(源码中是用的二分查找,因为是有序的)
-
如果在活跃事务列表 m_ids 中能找到 DB_TRX_ID,表明:① 在当前事务创建快照前,该记录行的值被事务 ID 为 DB_TRX_ID 的事务修改了,但没有提交;或者 ② 在当前事务创建快照后,该记录行的值被事务 ID 为 DB_TRX_ID 的事务修改了。这些情况下,这个记录行的值对当前事务都是不可见的。跳到步骤 5
-
在活跃事务列表中找不到,则表明“id 为 trx_id 的事务”在修改“该记录行的值”后,在“当前事务”创建快照前就已经提交了,所以记录行对当前事务可见
-
-
在该记录行的 DB_ROLL_PTR 指针所指向的 undo log 取出快照记录,用快照记录的 DB_TRX_ID 跳到步骤 1 重新开始判断,直到找到满足的快照版本或返回空
在事务隔离级别 RC 和 RR (InnoDB 存储引擎的默认事务隔离级别)下,InnoDB 存储引擎使用 MVCC(非锁定一致性读),但它们生成 Read View 的时机却不同
-
在 RC 隔离级别下的 每次select 查询前都生成一个Read View (m_ids 列表)
-
在 RR 隔离级别下只在事务开始后 第一次select 数据前生成一个Read View(m_ids 列表)
3.分布式事务解决方案
3.1 CAP 理论
a.一致性
一致性是指:用户更新操作的时候,要么在所有数据副本都更新成功,要么所有副本都更新失败。也就是说,一致性要求所有数据节点的数据副本修改是原子的,数据都是最新的,从任意数据节点读取的数据都是最新的。
一致性存在如下特点:
1)存在数据同步的过程,应用程序的写操作存在一定的延迟。
2)为了保证各节点数据的一致性,需要对相应的资源进行锁定,待数据同步完成后再释放相应锁定的资源。
3)如果数据写入并且同步成功,所有的节点都会返回最新的数据,相反,如果数据写入或者同步失败,所有节点都不会存在最新写入的数据。
b.可用性
可用性是指客户端访问数据的时候,能够快速得到响应。不存在响应超时或者相应错误的情况。
c.分区容错性
1.一个节点挂掉,不影响其他节点对外提供服务
2.分区容错性是分布式系统必须具备的基础能力。
在满足分区容错性的情况下,可用性和一致性是互相矛盾的。所以cap理论最多满足两个。
3.2 BASE 理论
Base理论是对CAP理论中的ap的一个扩展,它通过牺牲强一致性来获取可用性。Base理论中的base是基本可用,软状态,最终一致性。
a.基本可用
基本可用是指的是分布式系统出现故障的时候,允许其损失的系统部分可用性,比如相应时间的损失,但是要保证系统基本可用。例如电商的业务场景中,添加购物车下单功能出现故障的时候,商品浏览功能仍然可以使用。
b.软状态
软状态指的是系统允许系统存在中间状态,这些中间状态不会影响系统可用性。只是允许系统各个节点中存在数据延迟。例如电商业务场景中,订单支付中,退款中就是软状态。
c.最终一致性
最终一致性是指数据副本经过一定时间后,能够达到最终的一致状态。
3.3 强一致分布式事务解决方案
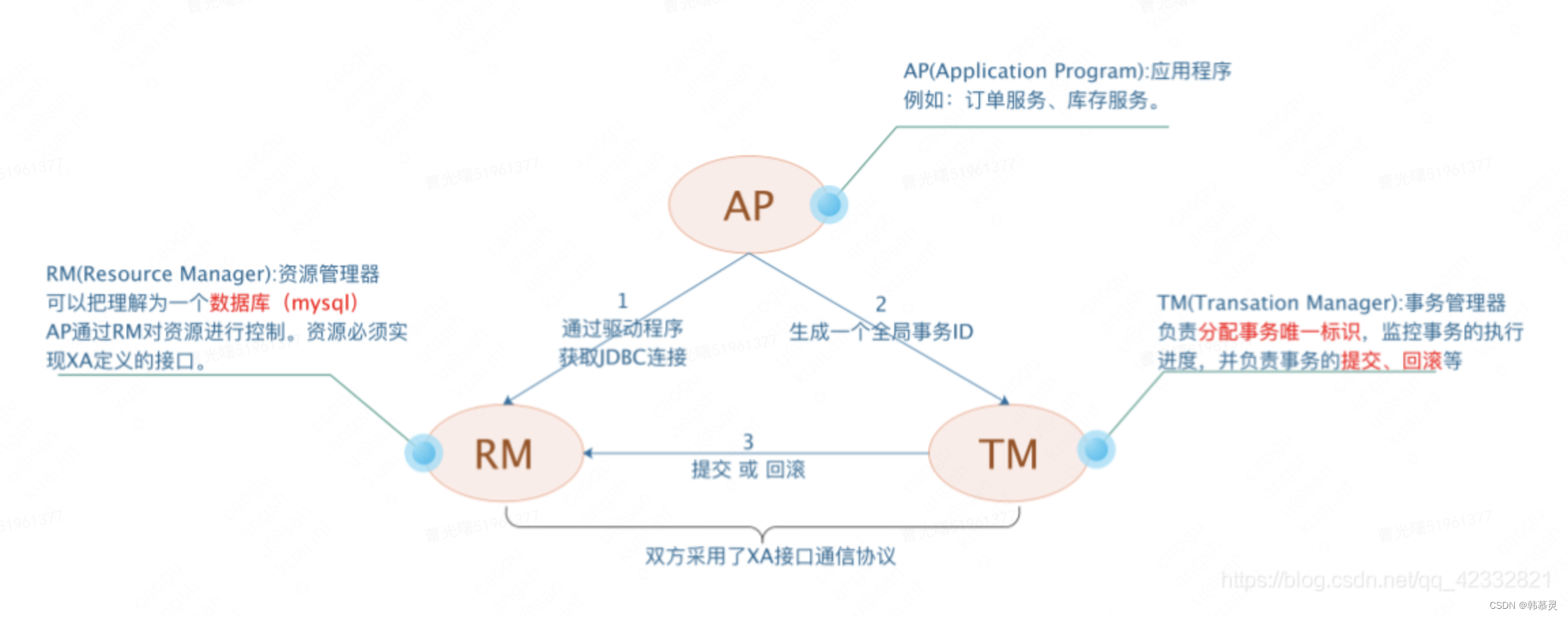
a.DTP模型
定义了以下的核心组件:
1)AP:应用程序(Application Program) 可以理解为参与DTP分布式事务模型的应用程序
2)RM: 资源管理器(Resource Manager) 可以理解为数据库管理系统或者消息服务管理器。应用程序可以通过资源管理器对相应的资源 进行有效的控制,相应的资源需要实现自定义的接口
3)TM: 事务管理器(Transaction Manager) 负责协调和管理DTP 模型的事务,为应用程序提供编程接口,同时管理事务管理器
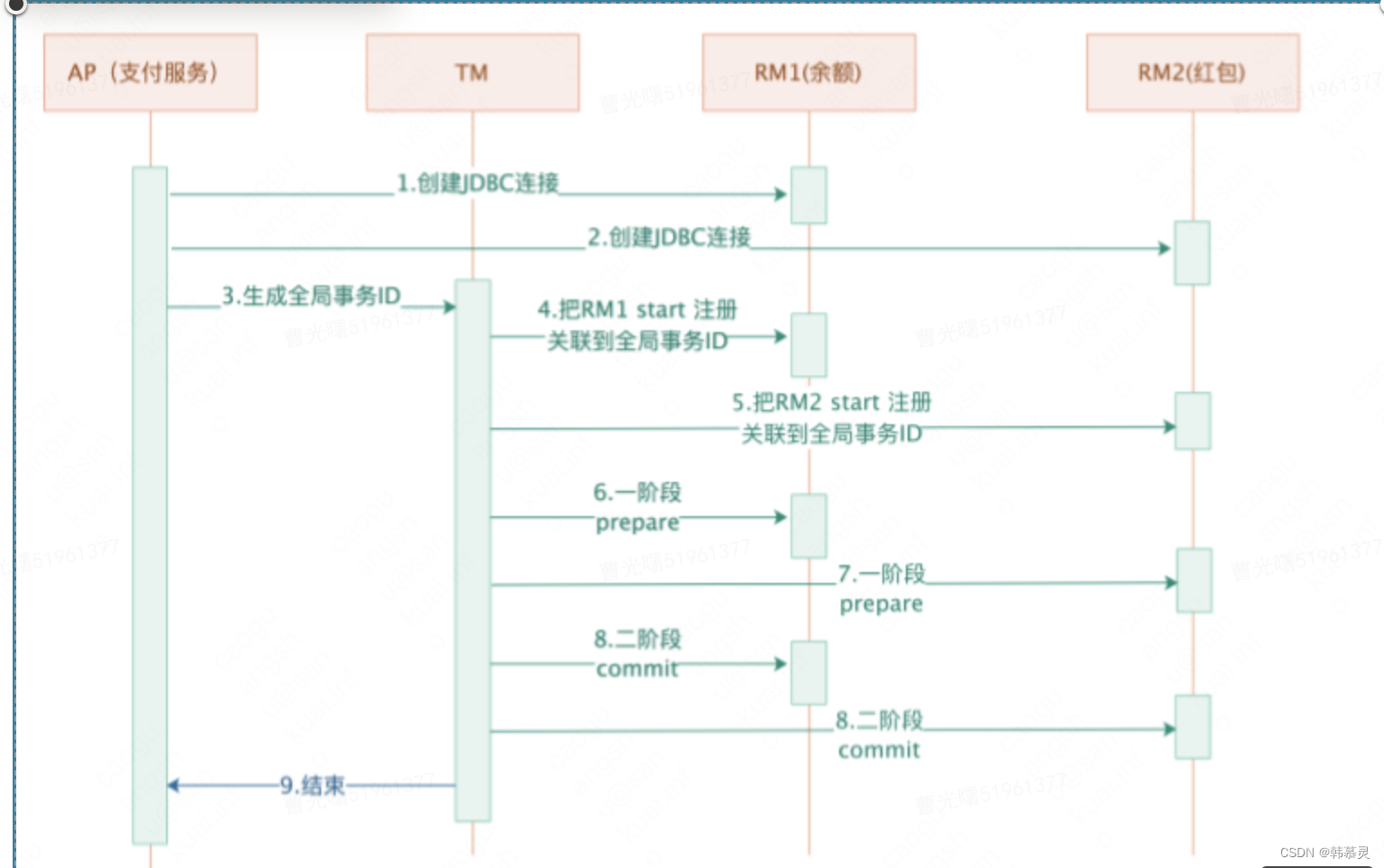
b.2PC提交
2PC 模型执行成功流程
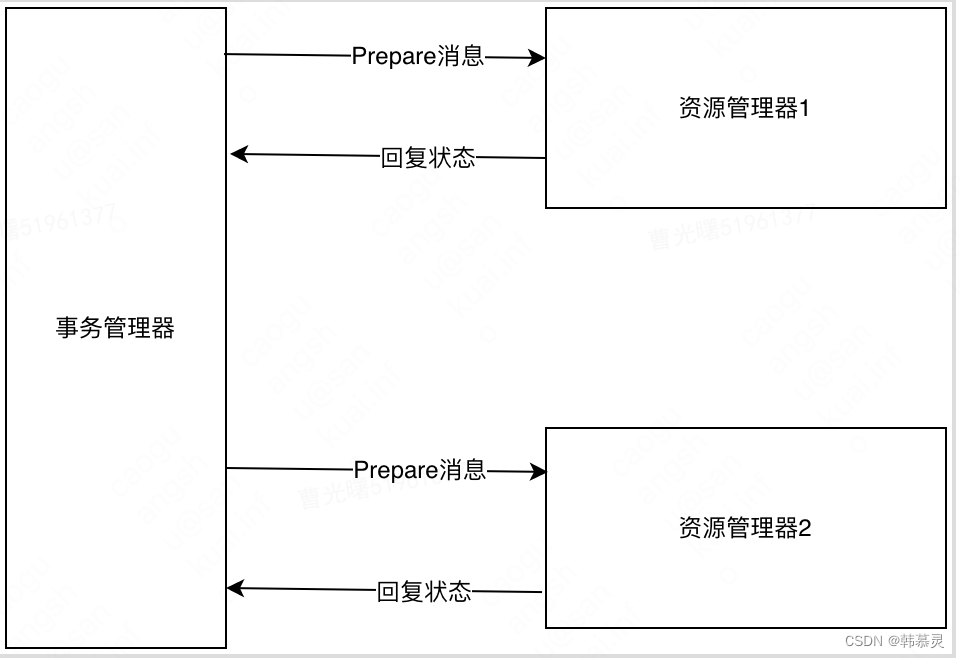
1.Prepare 阶段
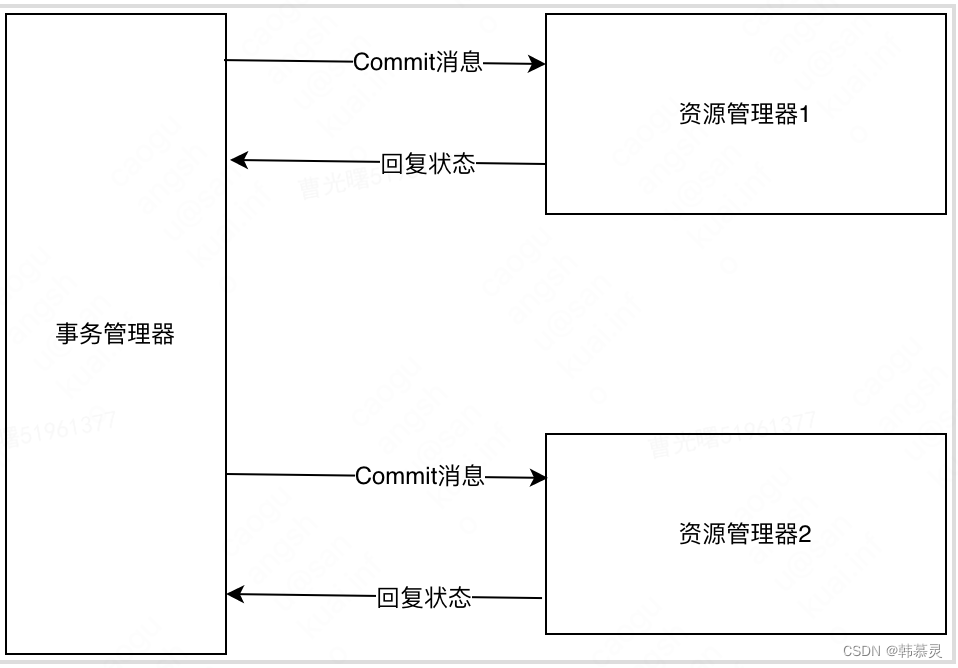
2.Commit 阶段
2PC 模型执行失败流程
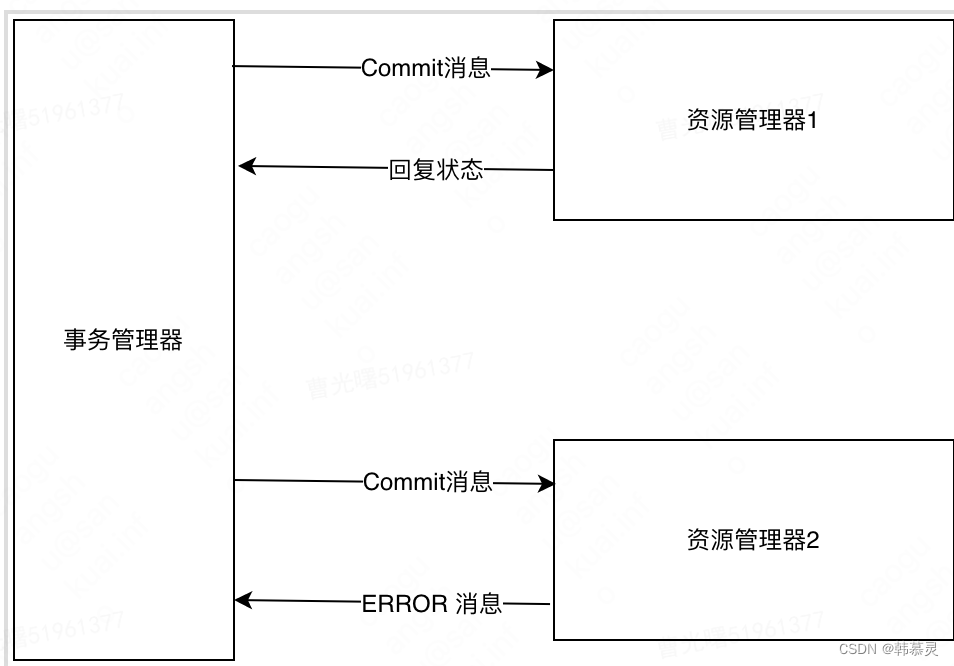
2PC 模型存在如下缺点:
1.同步阻塞问题,事务的执行过程中,所有参与的事务节点都会对其占用公共资源锁。导致其他访问公共资源进程或者线程阻塞。
2.单点故障问题,如果事务管理器发生故障,则资源管理器会一直阻塞。
3.数据不一致问题,如果在Commit 阶段,由于网络或者部分资源管理器发生故障,导致部分资源管理器没有收到事务管理器发送过来的commit消息。会引起数据不一致的问题。
4.无法解决问题:如果在Commit 阶段,事务管理器发送Commit消息后宕机,并且唯一接受到这条Commit 消息的资源管理器也宕机了。则无法确认事务是否已经提交。
c.3PC提交
3PC 事务执行成功流程
3PC 模型把2PC模型 中的Prepare 阶段一分为二,最终形成3个阶段: CanCommit 阶段,PreCommit 阶段和DoCommit阶段或者DoRollBack 阶段,3PC 模型流程同样分为事务执行成功和事务执行失败两种情况。

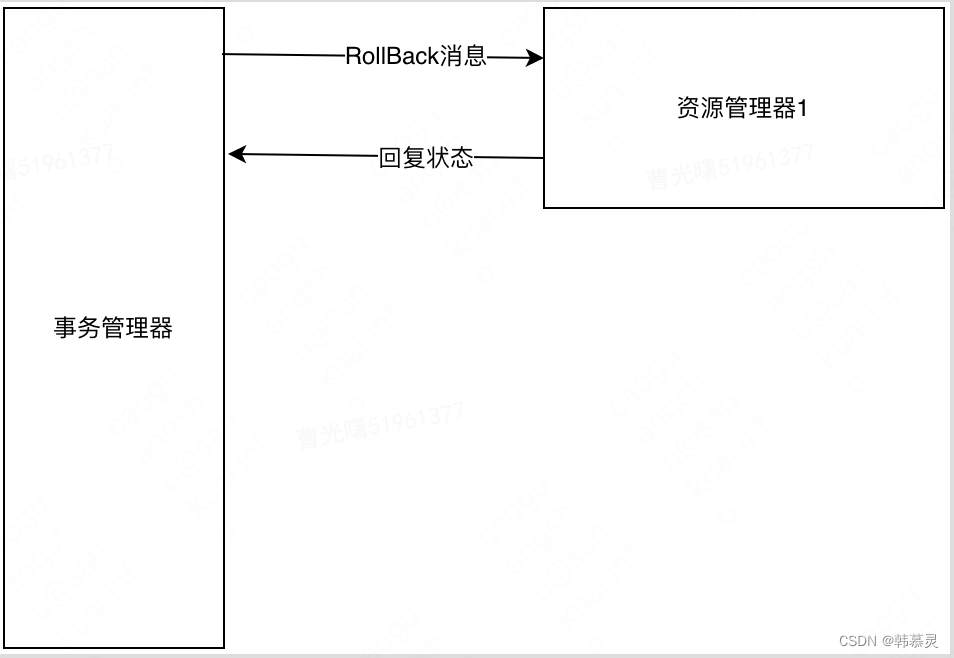
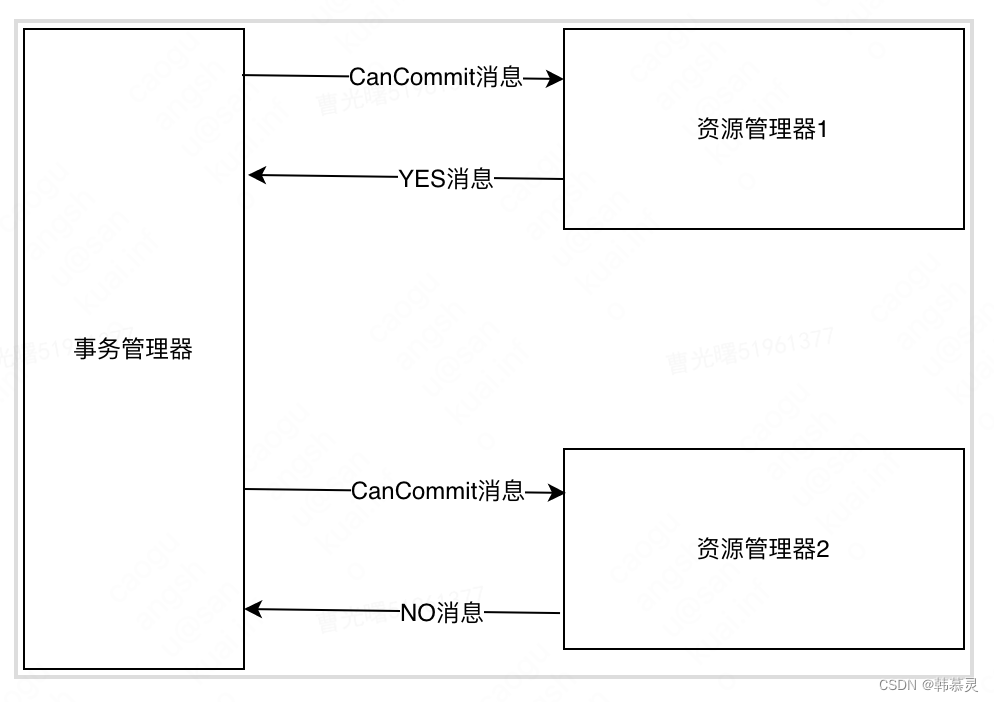
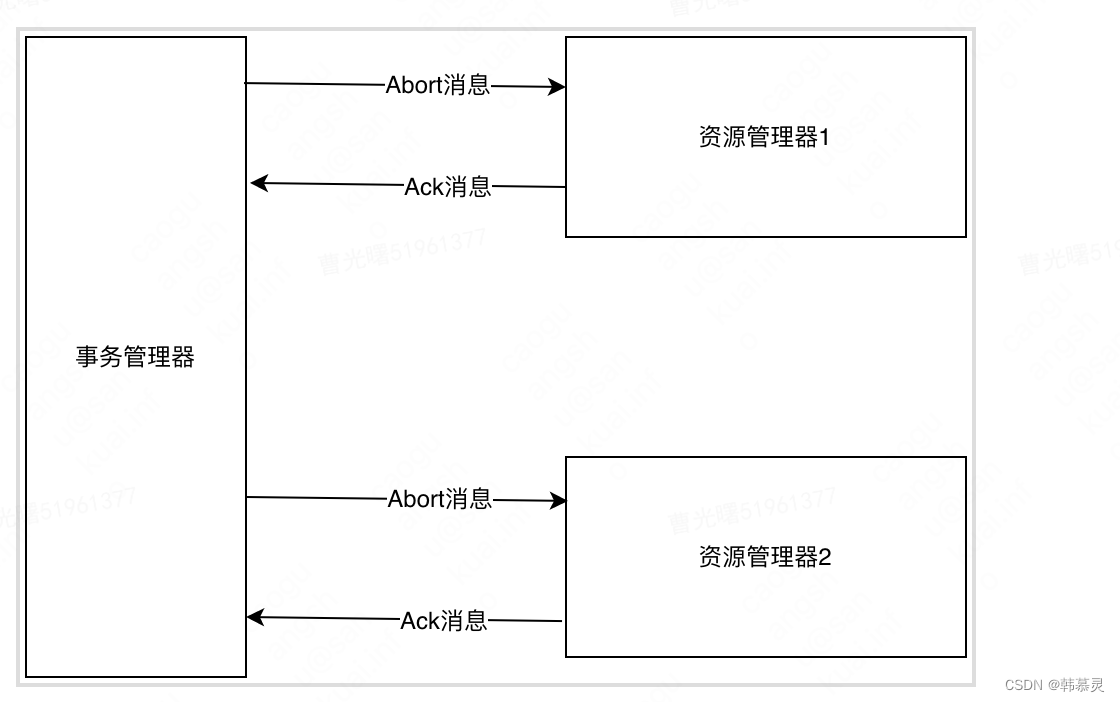
事务失败的流程
CanCommit阶段
PreCommit阶段
DoRollback阶段
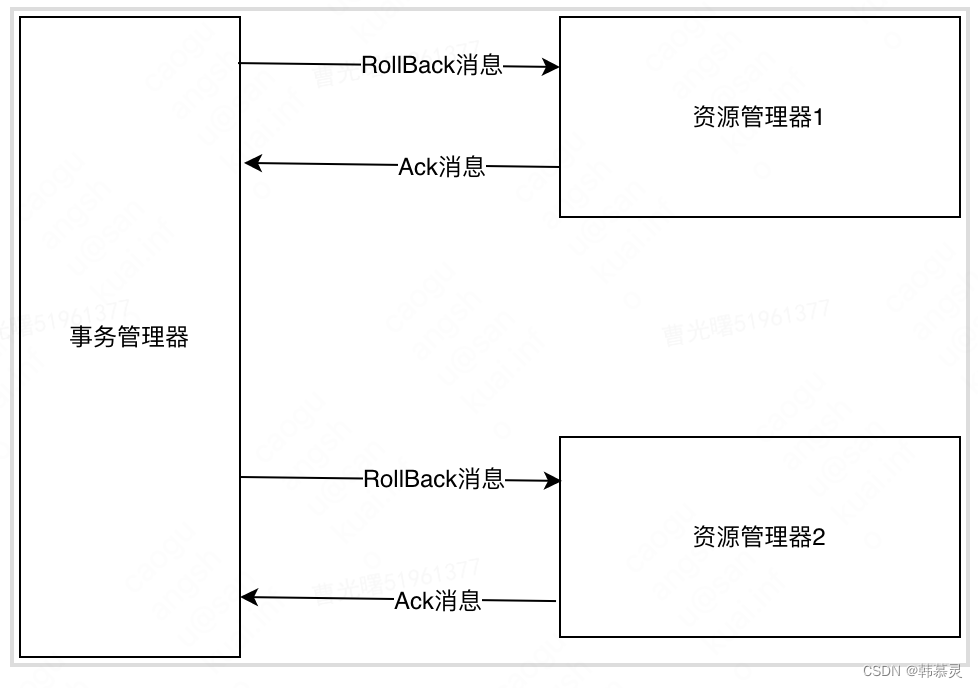
与2PC 模型相比,3PC模型主要是解决了单点的故障问题,并且减少了事务管理器的阻塞现象。但是3PC 模型中,如果资源管理器无法及时的收到来自食物管理器发出的消息,那么资源管理器就会执行提交事务的操作,而不是一直持有事务的资源,并且处于阻塞状态,但是这种机制会导致数据不一致的问题。
如果是 网络故障原因,导致资源管理器没有及时的收到实物管理器发出的Abort消息。则资源管理器会在一段时间后提交事务,这就导致其他接受到Abort消息兵执行事务回滚的资源管理器数据不一致。
3.4 最终一致性分布式事务解决方案
a.TCC分布式事务模型

b.可靠消息最终一致性
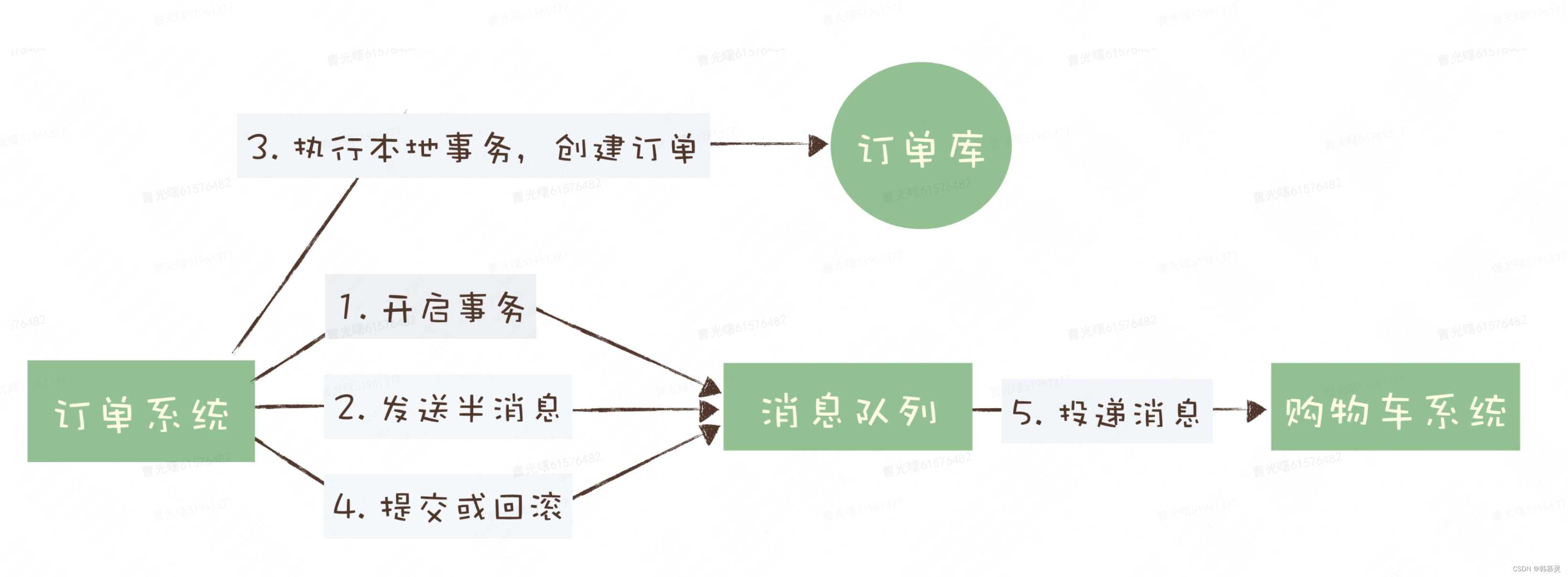
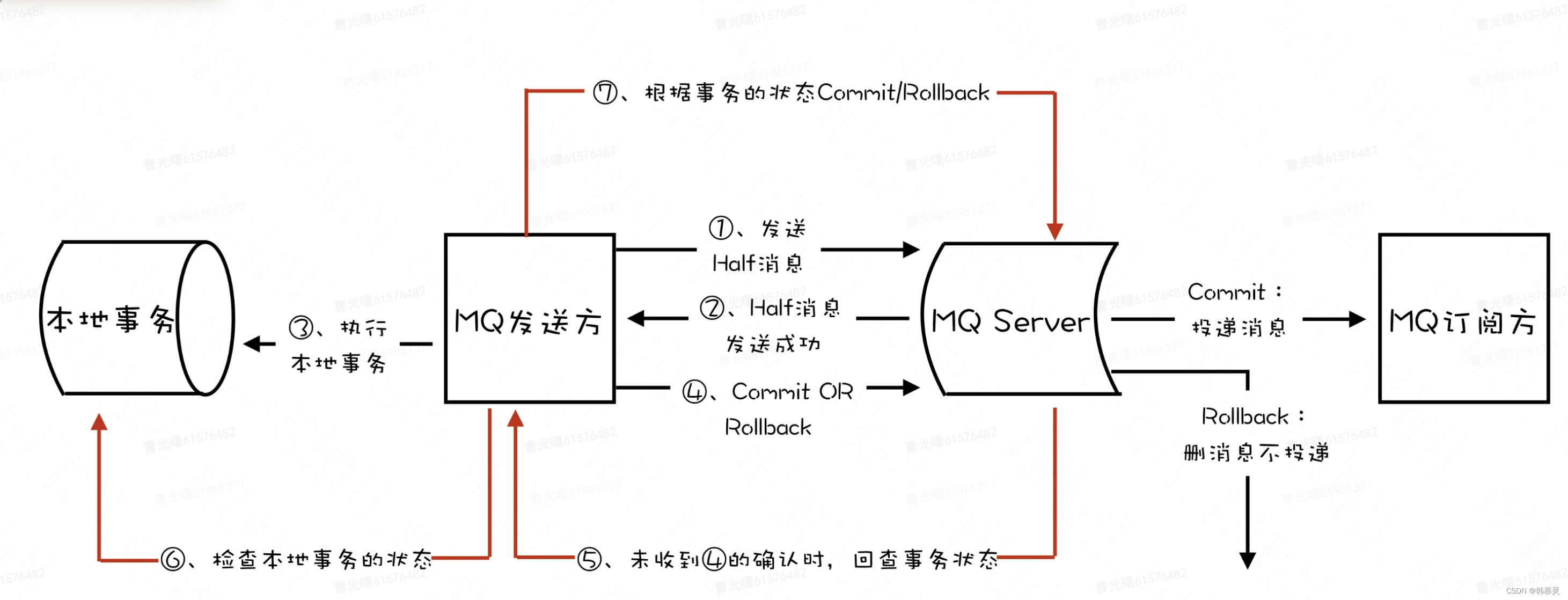
参考资料
1.InnoDB存储引擎对MVCC的实现 | JavaGuide
2.深入理解分布式事务电子书

















 1176
1176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









