



 本文详细介绍如何在Windows环境下搭建Solr 7.1.0,包括配置Tomcat、环境变量、日志路径、solr-home目录、IK分词器及Solr与Spring的整合步骤。
本文详细介绍如何在Windows环境下搭建Solr 7.1.0,包括配置Tomcat、环境变量、日志路径、solr-home目录、IK分词器及Solr与Spring的整合步骤。
solr7.1.0搭建整合(windows)
-版本solr-7.1.0
-环境 Windows
-jdk1.8
-启动方式:部署在apache-tomcat-8.5.23,以下简称Tomcat
-
将solr-7.1.0\server\solr-webapp下的webapp复制到Tomcat\webapps下,并改名solr;
-
将solr-7.1.0\server\lib下的ext下的所有jar包复制到Tomcat\webapps\solr\WEB-INF\lib下,以及
solr-7.1.0\server\lib下以metrics开头的jar、gmetric4j-1.0.7.jar复制到Tomcat\webapps\solr\WEB-INF\lib下;
-
在Tomcat\webapps\solr\WEB-INF下创建classes文件夹,并把solr-7.1.0\server\resources下的log4.perportiy复制到 classes文件下;
-
修改修改Tomcat\bin下的catalina.bat,增加solr.log.dir系统变量,指定solr日志记录存放地址。
if not "%JSSE_OPTS%" == "" goto gotJsseOpts
set JSSE_OPTS="-Djdk.tls.ephemeralDHKeySize=2048"
:gotJsseOpts
set "JAVA_OPTS=%JAVA_OPTS% %JSSE_OPTS%" --增加下一行
set "JAVA_OPTS=%JAVA_OPTS% -Dsolr.log.dir=D:\Solr-7\solr_home\logs"
- 在任意地方创建文件夹solr_home,把solr-7.1.0\server下solr下的所有文件复制到这个solr_home下,在这里,我创建在Solr-7.1.0的同级目录下了,并且修改配置文件Tomcat\webapps\solr\WEB-INF\web.xml,将下面配置的注释放开,黑体部分更改为你的solr-home地址。
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>D:\Solr-7\solr_home</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>
并注释下面部分:
<!-- Get rid of error message
<security-constraint>
<web-resource-collection>
<web-resource-name>Disable TRACE</web-resource-name>
<url-pattern>/</url-pattern>
<http-method>TRACE</http-method>
</web-resource-collection>
<auth-constraint/>
</security-constraint>
<security-constraint>
<web-resource-collection>
<web-resource-name>Enable everything but TRACE</web-resource-name>
<url-pattern>/</url-pattern>
<http-method-omission>TRACE</http-method-omission>
</web-resource-collection>
</security-constraint>
-->
- 配合solr日志记录存放地址,在solr-home下新建logs文件夹,此处与配置4位置配置路径一致;
- 拷贝solr-7.1.0下contrib和dist文件夹至solr-home目录下。
- 在solr-home目录下新建new_core文件夹;并拷贝solr-7.1.0\server\solr\configsets_default\目录下conf文件夹至solr-home\new_core下。
- 修改solr-home\new_core\conf\solrconfig.xml文件,如下
<!--
<lib dir="${solr.install.dir:../../../..}/contrib/extraction/lib" regex=".*\.jar" />
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-cell-\d.*\.jar" />
<lib dir="${solr.install.dir:../../../..}/contrib/clustering/lib/" regex=".*\.jar" />
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-clustering-\d.*\.jar" />
<lib dir="${solr.install.dir:../../../..}/contrib/langid/lib/" regex=".*\.jar" />
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-langid-\d.*\.jar" />
<lib dir="${solr.install.dir:../../../..}/contrib/velocity/lib" regex=".*\.jar" />
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-velocity-\d.*\.jar" />
-->
<lib dir="${solr.install.dir:../}/contrib/extraction/lib" regex=".*\.jar" />
<lib dir="${solr.install.dir:../}/dist/" regex="solr-cell-\d.*\.jar" />
<lib dir="${solr.install.dir:../}/contrib/clustering/lib/" regex=".*\.jar" />
<lib dir="${solr.install.dir:../}/dist/" regex="solr-clustering-\d.*\.jar" />
<lib dir="${solr.install.dir:../}/contrib/langid/lib/" regex=".*\.jar" />
<lib dir="${solr.install.dir:../}/dist/" regex="solr-langid-\d.*\.jar" />
<lib dir="${solr.install.dir:../}/contrib/velocity/lib" regex=".*\.jar" />
<lib dir="${solr.install.dir:../}/dist/" regex="solr-velocity-\d.*\.jar" />
<lib dir="${solr.install.dir:../}/dist/" regex="ojdbc\d.*\.jar" />
<lib dir="${solr.install.dir:../}/dist/" regex="solr-dataimporthandler\d.*\.jar" />
注:solr.install.dir表示solrCore的目录位置
10. 启动Tomcat,访问http://localhost:8080/solr/index.html
- 配置Ik分词器,首先导入ik的jar ik-analyzer-solr5-5.x 和 solr-analyzer-ik-5.1.0 两个jar包
导入Tomcat\webapps\solr\WEB-INF\lib下
然后配置solr_home\new_core\conf下的managed-schema文件加入
<fieldType name="text_ik" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index"> --此处为创建索引分词
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query"> -- 此处为查询分词索引
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<field name="查询字段" type="text_ik" indexed="true" stored="true"/>
<field name="productName" type="text_ik" indexed="true" stored="true"/>
到此IK分词设置完成。
12. Solr与Spring整合
创建spring-context-solr.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context" xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.1.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.1.xsd"
default-lazy-init="true">
<!--定义solr的server-->
<bean id="httpSolrClient" class="org.apache.solr.client.solrj.impl.HttpSolrClient">
<constructor-arg value="http://location/solr/new_core"/>
</bean>
</beans>
- 创建测试类SorlJTest
@ContextConfiguration(locations = { "classpath*:/spring-context*.xml" })
public class SolrJTest extends AbstractTransactionalJUnit4SpringContextTests {
private static final Log log = LogFactory.getLog(SolrJTest.class);
@Autowired
private HttpSolrClient client;
@Test
public void test() throws IOException, SolrServerException {
SolrQuery solr = new SolrQuery();
solr.setQuery("productName:苹果");
QueryResponse queryResponse =client.query(solr);
//拿到数据集合,返回查询结果
List<SolrDocument> list =queryResponse.getResults();
System.out.println(list);
}
}
14.有关IK分词,粗细力度查询
上面11中
useSmart="false" 为智能分词 false 关闭状态 默认最细力度分词
useSmart="true" 为智能分词 true 开启状态 默认最粗力度分词
智能分词的开关,根据自身业务的需求来进行设置,此处设置粗粒度查询 匹配度最高在第一位
- 配置文件-自动导入数据库数据
在solr_home\new_core\conf下新建data-config.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<dataConfig>
<dataSource
type="JdbcDataSource"
driver="oracle.jdbc.driver.OracleDriver"
url="jdbc:oracle:thin:@192.168.00.000:1521:XXXX"
user="XXXXXX"
password="XXXXXXX"/>
<document>
<entity name="XXXXXX" pk="USERID"
query="select
NMSKY,
NMSKY,
USER_ID,
USERNAM,
USERRAT
from XXXXXX"
deltaQuery="select USER_ID as USERID from XXXXXX where to_char(TIME,'YYYY-MM-DD HH24:MI:SS') > '${dih.last_index_time}'"
deltaImportQuery="select NMSKY,NMSKY,USER_ID,USERNAM,USERRAT from XXXXXX where USER_ID='${dih.delta.USERID}'">
</entity>
</document>
</dataConfig>
IK分词器的配置和使用
1.以前老的IK 不支持Solr 5.3的版本 ,请注意下载使用5.X以上版本。
solr-analyzer-ik-5.1.0.jar ik-analyzer-solr5-5.x.jar分词jar包,
ext.dic为扩展字典,
stopword.dic为停止词字典
IKAnalyzer.cfg.xml为配置文件。
2. 将ik的相关文件 拷贝到 solr\WEB-INF\lib 目录下
将词典配置文件拷贝到\solr\WEB-INF\classes
4. 在 solr_home\mycore1\conf\schema.xml (或者managed-schema)增加如下配置
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
同时,把需要分词的字段,设置为text_ik,
<field name="id" type="int" indexed="true" stored="true" required="true" multiValued="false" />
<field name="name" type="text_ik" indexed="true" stored="true" required="true" multiValued="false" />
<field name="title" type="text_ik" indexed="true" stored="true" required="true" multiValued="false" />
- 配置IKAnalyzer分词器的扩展词典,停止词词典
- 将 文件夹下的IKAnalyzer.cfg.xml , ext.dic和stopword.dic 三个文件 复制到/webapps/solr/WEB-INF/classes 目录下,并修改IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;</entry>
</properties>
- 在ext.dic 里增加自己的扩展词典
注意: 记得将stopword.dic,ext.dic的编码方式为UTF-8 无BOM的编码方式。
SolrCore配置
SolrHome是Solr运行的主目录,该目录中包括了多个SolrCore目录。SolrCore目录中包含了运行Solr实例所有的配置文件和数据文件,Solr实例就是SolrCore。
一个SolrHome可以包括多个SolrCore(Solr实例),每个SolrCore提供单独的搜索和索引服务。
创建solrhome
拷贝solr目录到想要作为solrhome的目录下即可
配置solrcor,
在solrcore目录下的collection1/conf目录下有solrconfig.xml,配置SolrCore实例的相关信息
主要关注的标签:
lib标签、datadir标签、requestHandler标签
在solrconfig.xml中可以加载一些扩展的jar,solr.install.dir表示solrCore的目录位置,需要如下修改:
<lib dir="${solr.install.dir:../..}/contrib/extraction/lib" regex=".*\.jar" />
<lib dir="${solr.install.dir:../..}/dist/" regex="solr-cell-\d.*\.jar" />
<lib dir="${solr.install.dir:../..}/contrib/clustering/lib/" regex=".*\.jar" />
<lib dir="${solr.install.dir:../..}/dist/" regex="solr-clustering-\d.*\.jar" />
<lib dir="${solr.install.dir:../..}/contrib/langid/lib/" regex=".*\.jar" />
<lib dir="${solr.install.dir:../..}/dist/" regex="solr-langid-\d.*\.jar" />
<lib dir="${solr.install.dir:../..}/contrib/velocity/lib" regex=".*\.jar" />
<lib dir="${solr.install.dir:../..}/dist/" regex="solr-velocity-\d.*\.jar" />
<lib dir="${solr.install.dir:../..}/contrib/dataimporthandler/lib/" regex=".*\.jar" />
<lib dir="${solr.install.dir:../..}/contrib/db/lib/" regex=".*\.jar" />
每个SolrCore都有自己的索引文件目录 ,默认在SolrCore目录下的data中。
${solr.data.dir:}
requestHandler请求处理器,定义了索引和搜索的访问方式。
通过/update维护索引,可以完成索引的添加、修改、删除操作。
<requestHandler name="/update" class="solr.UpdateRequestHandler">
<!-- See below for information on defining
updateRequestProcessorChains that can be used by name
on each Update Request
-->
<!--
<lst name="defaults">
<str name="update.chain">dedupe</str>
</lst>
-->
</requestHandler>
通过/select搜索索引
<requestHandler name="/select" class="solr.SearchHandler">
<!-- default values for query parameters can be specified, these
will be overridden by parameters in the request
-->
<lst name="defaults">
<str name="echoParams">explicit</str>
<int name="rows">10</int>
<str name="df">text</str>
</lst>
</requestHandler>
mysql数据源配置
1、包依赖 (问题 不知道放什么包或 找不到对应版本的包)
拷贝mysql-connector-java-5.1.25-bin.jar到webapp\WEB-INF\lib目录下
配置E:\solr-4.8.0\example\solr\collection1\conf\solrconfig.xml
<requestHandler name="/dataimport"
class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>
这里只是声明了会有一个dataimport 操作,数据详情配置在 同目录的data-config.xml中配置
导入依赖库文件:
把<lib dir="../../../dist/" regex="solr-dataimporthandler-\d.*\.jar"/>加在
<lib dir="../../../dist/" regex="solr-cell-\d.*\.jar" />
前面。
2、配置solrconf.xml (如果你用的是cloud模式 找不到这个文件 只能在网页上配置,存储在zookpeer中 后面会讲)
data-confi.xml 内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<dataConfig>
<dataSource type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://127.0.0.1/dbname" user="test"
password="test" batchSize="-1"/>
<document name="video">
<entity name="video" pk="id" query="select id,name,level from video "
deltaImportQuery="select id,title,content from blog_blog where ID='${dataimporter.delta.id}'"
deltaQuery="select id from blog_blog where add_time > '${dataimporter.last_index_time}'"
deletedPkQuery="select id from blog_blog where id=0"
<field column="id" name="id" />
<field column="name" name="name" />
<field column="level" name="level" />
</entity>
</document>
</dataConfig>
query 用于初次导入到索引的sql语句。
考虑到数据表中的数据量非常大,比如千万级,不可能一次索引完,
因此需要分批次完成,那么查询语句query要设置两个参数:
${dataimporter.request.length}
${dataimporter.request.offset}
query=”select id,title,content from blog_blog limit ${dataimporter.request.length}
offset ${dataimporter.request.offset}”
请求:http://localhost:8983/solr/collection2/dataimport?
command=full-import&commit=true&clean=false&offset=0&length=10000
deltaImportQuery 根据ID取得需要进入的索引的单条数据。
deltaQuery 用于增量索引的sql语句,用于取得需要增量索引的ID。
deletedPkQuery 用于取出需要从索引中删除文档的的ID
solr中有一个很重要的概念 --文档:这个对于本例来说一行记录就是一个文档。
上面的配置中
video是指实体名称 可以和表名一致
column 为映射到solr中的名称(在manage-schema中会用到),name为mysql表中的字段的名称
3、配置manage-schema (solr6.6已经没有schema.xml,可以直接修改这个文件,也可以在网页上配置)
设置一个唯一key id
并且把这个key的树形设置成 multiValued=“false” indexed=“true” required=“true” stored=“true” 这很重要, uniquekey 会保证你重复建索引时 数据不会重复.
注意:无论数据库中的主键是什么类型,这里的主键只能是string类型,否则会出现问题。文档找不到。
<?xml version="1.0" encoding="UTF-8" ?>
略...
<!--
这是Solr的schema文件,应该命名为schema.xml,并且在solr home的conf目录下
(如,默认在./solr/conf/schema.xml).
有关如何根据需要定制化该文件,请参照:
http://wiki.apache.org/solr/SchemaXml 性能须知: 这里包含了很多实际应用不需要的可选项。 为改善性能,你可以:
- 尽量将所有仅用于搜索,而不用于实际返回的字段设置stored="false";
- 尽量将所有仅用于返回,而不用于搜索的字段设置indexed="false";
- 去掉所有不需要的copyField 语句;
- 为了达到最佳的索引大小和搜索性能,对所有的文本字段设置indexed="false",
使用copyField将他们拷贝到“整合字段”name="text"的字段中,使用整合字段进行搜索;
- 使用server模式来运行JVM,同时将log级别调高, 避免输出所有请求的日志。
-->
<schema name="example" version="1.5">
略...
<fields>
<!-- fields各个属性说明:
name: 必须属性 - 字段名
type: 必须属性 - <types>中定义的字段类型
indexed: 如果字段需要被索引(用于搜索或排序),属性值设置为true
stored: 如果字段内容需要被返回,值设置为true
docValues: 如果这个字段应该有文档值(doc values),设置为true。文档值在门
面搜索,分组,排序和函数查询中会非常有用。虽然不是必须的,而且会导致生成
索引变大变慢,但这样设置会使索引加载更快,更加NRT友好,更高的内存使用效率。
然而也有一些使用限制:目前仅支持StrField, UUIDField和所有 Trie*Fields,
并且依赖字段类型, 可能要求字段为单值(single-valued)的,必须的或者有默认值。
multiValued: 如果这个字段在每个文档中可能包含多个值,设置为true
termVectors: [false] 设置为true后,会保存所给字段的相关向量(vector)
当使用MoreLikeThis时, 用于相似度判断的字段需要设置为stored来达到最佳性能.
termPositions: 保存和向量相关的位置信息,会增加存储开销
termOffsets: 保存 offset 和向量相关的信息,会增加存储开销
required: 字段必须有值,否则会抛异常
default: 在增加文档时,可以根据需要为字段设置一个默认值,防止为空
-->
<!-- 字段名由字母数字下划线组成,且不能以数字开头。两端为下划线的字段为保留字段,
如(_version_)。
-->
<field name="id" type="string" indexed="true" stored="true"
required="true" multiValued="false" />
<field name="title" type="text_general" indexed="true"
stored="true" multiValued="true"/>
<field name="description" type="text_general" indexed="true" stored="true"/>
<field name="author" type="text_general" indexed="true" stored="true"/>
<field name="keywords" type="text_general" indexed="true" stored="true"/>
<field name="category" type="text_general" indexed="true" stored="true"/>
<field name="url" type="text_general" indexed="true" stored="true"/>
<field name="last_modified" type="date" indexed="true" stored="true"/>
<!-- 注意: 为了节省空间,这个字段默认不被索引, 因使用copyField被拷贝到了名为text的字段中
。用于内容返回和高亮。搜索时使用text字段
-->
<field name="content" type="text_general" indexed="false"
stored="true" multiValued="true"/>
<!-- 整合字段(catchall field), 包含其他可搜索的字段 (通过copyField实现) -->
<field name="text" type="text_general" indexed="true"
stored="false" multiValued="true"/>
<!-- 保留字段,不能删除,否则报错 -->
<field name="_version_" type="long" indexed="true" stored="true"/>
</fields>
<!-- 文档的唯一标识,可理解为主键,除非标识为required="false", 否则值不能为空-->
<uniqueKey>id</uniqueKey>
<!-- 拷贝需要索引的字段到整合字段中 -->
<copyField source="title" dest="text"/>
<copyField source="author" dest="text"/>
<copyField source="description" dest="text"/>
<copyField source="keywords" dest="text"/>
<copyField source="content" dest="text"/>
<copyField source="url" dest="text"/>
<types>
<!-- 字段类型定义 -->
<fieldType name="string" class="solr.StrField" sortMissingLast="true" />
<fieldType name="boolean" class="solr.BoolField" sortMissingLast="true"/>
<fieldType name="int" class="solr.TrieIntField" precisionStep="0"
positionIncrementGap="0"/>
<fieldType name="float" class="solr.TrieFloatField" precisionStep="0"
positionIncrementGap="0"/>
<fieldType name="long" class="solr.TrieLongField" precisionStep="0"
positionIncrementGap="0"/>
<fieldType name="double" class="solr.TrieDoubleField" precisionStep="0"
positionIncrementGap="0"/>
<fieldType name="date" class="solr.TrieDateField" precisionStep="0"
positionIncrementGap="0"/>
略...
<!-- Thai,泰语类型字段 -->
<fieldType name="text_th" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.ThaiWordFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true"
words="lang/stopwords_th.txt" />
</analyzer>
</fieldType>
<!-- Turkish,土耳其语类型字段 -->
<fieldType name="text_tr" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.TurkishLowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="false"
words="lang/stopwords_tr.txt" />
<filter class="solr.SnowballPorterFilterFactory" language="Turkish"/>
</analyzer>
</fieldType>
<!-- Chinese,需要我们自己配置,整合mmseg4j就配置在这里 -->
</types>
<!-- 文档相似度判断依赖于文档相似度得分。 一个自定义的 Similarity 或 SimilarityFactory
可以在这里指定, 但是默认的设置已经适合大多数应用。可以参考:
http://wiki.apache.org/solr/SchemaXml#Similarity
-->
<!--
<similarity class="com.example.solr.CustomSimilarityFactory">
<str name="paramkey">param value</str>
</similarity>
-->
</schema>
##################################使用solr遇到一个问题 start############################
solr 在使用查询的时候,【q=city:new york】 的时候会命中包含new york的所有数据文档并返回。
但是使用中文【q=city:成都】 的时候会命中包含成和都的合集,实际上我们需要的是精确查找,查找资料发现,如果想只查找包含【成都】
这个词语的文档,我们需要这样做【q=city:“成都”】必须要添加上引号
##################################使用solr遇到一个问题 end############################
##################################solr 链接数据库异常 start############################
异常输出: mysql启动读取数据库配置文件爆:对实体 “characterEncoding” 的引用必须以 ‘;’ 分隔符结尾
“&”定义与解析的原因, 将
<property name="url" value="jdbc:mysql://192.168.1.222:3306/test?characterEncoding=utf8&allowMultiQueries=true" />
改成
<property name="url" value="jdbc:mysql://192.168.1.222:3306/test?characterEncoding=utf8&allowMultiQueries=true" />
##################################使用solr遇到一个问题 end############################
比较重要的几个配置
分词:
<!-- IK分词 start-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<!--
IKTokenizerFactory:继承 TokenizerFactory
useSmart:是否启用 智能分词
-->
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" />
<!--
StopFilterFactory:停止分词,会根据stopwords.txt中配置的文件停止分词
-->
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" />
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
</analyzer>
</fieldType>
<!-- IK分词 end-->
同义词配置:
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<!-- in this example, we will only use synonyms at query time
<filter class="solr.SynonymFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
-->
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
评分权重配置(支持自定义):
<similarity class=“com.example.solr.CustomSimilarityFactory” />
配置默认查询字段
以query查询为例 默认查询的是field name="text"的字段,其他select或者自己定义的查询组件也是一样的道理
<requestHandler name="/query" class="solr.SearchHandler">
<lst name="defaults">
<str name="echoParams">explicit</str>
<str name="wt">json</str>
<str name="indent">true</str>
<!-- 默认查询字段 -->
<str name="df">text</str>
</lst>
</requestHandler>
至此 重启solr 在页面中找到对应的core点击dataimport 并执行 execute 查看logging,如果没有wanning 就ok了
注:配置文件的位置在 core下面而不是在安装目录下
solr配置-Schema.xml
配置项:
1,uniqueKey:文档的唯一标识、唯一键,这里配置的是下面出现的field 一般都叫id,在更新、删除的时都会用到
<uniqueKey>id</uniqueKey>
2,n多name不一样的fieldType:是一些常见的可重用定义,定义了 Solr如何处理 Field。也就是添加到索引中的xml文件属性中的类型,如int、text、date等.
属性说明:
name # 标识,与Field type对应
class #对应solr已定义的type Class
sortMissingLast #设置成true没有该field的数据排在有该field的数据之后,而不管请求时的排序规则, 默认是false。
sortMissingFirst #反之,默认是false
analyzer #字段类型指定的分词器
tokenizer #分词器类
type #当前分词用用于的操作.index代表生成索引时使用的分词器query代码在查询时使用的分词器
filter #分词后使用的过滤器,调用顺序和配置相同
3,各种field :field,dynamicField,copyField
Fields 就是定义那些你要在搜索结果中展示的字段,即在doucument中使用,用于搜索或者只是展示
field: 普通的字段设置
<field name=“sn” type=“string” indexed=“true” stored=“true” />
dynamicField: 动态的字段设置,用于后期自定义字段,号通配符.例如: test_i就是int类型的动态字段.
<dynamicField name="_i" type=“integer” indexed=“true” stored=“true”/>
copyField: 一般用于检索时用的字段,这样就只对这一个字段进行索引分词,copyField的dest字段如果有多个source一定要设置multiValued=true,否则会报错的
<copyField source=“body” dest=“teaser” maxChars=“300”/>
fields属性说明:
name #字段类型名
class #java类名
indexed #默认true。 是否被索引,说明这个数据应被搜索和排序,一般与stored反之。
stored #默认true。是否被存储,说明这个字段被包含在搜索结果中,一般与indexed反之。
omitNorms #字段的长度不影响得分和在索引时不做boost时,设置它为true。一般文本字段不设置为true。
termVectors #如果字段被用来做more like this 和highlight的特性时应设置为true。
compressed #字段是压缩的。这可能导致索引和搜索变慢,但会减少存储空间,只有StrField和TextField是可以压缩,这通常适合字段的长度超过200个字符。
multiValued #是否有多个值。
positionIncrementGap #和multiValued一起使用,设置多个值之间空白的数量
4,默认被注释掉的defaultSearchField,solrQueryParser,Similarity
defaultSearchField:默认搜索属性,如q=text就是默认的搜索text字段
<defaultSearchField>text</defaultSearchField>
solrQueryParser:查询转换模式,是并且还是或者(AND/OR必须大写)
<solrQueryParser defaultOperator="OR"/>
Similarity:自定义评分器,class是继承 DefaultSimilarity的子类,或者实现评分器接口的类,
下面的参数str 应该是可配置名称为paramkey,值为param value的参数吧
<similarity class="com.example.solr.CustomSimilarityFactory">
<str name="paramkey">param value</str>
</similarity>
solr查询
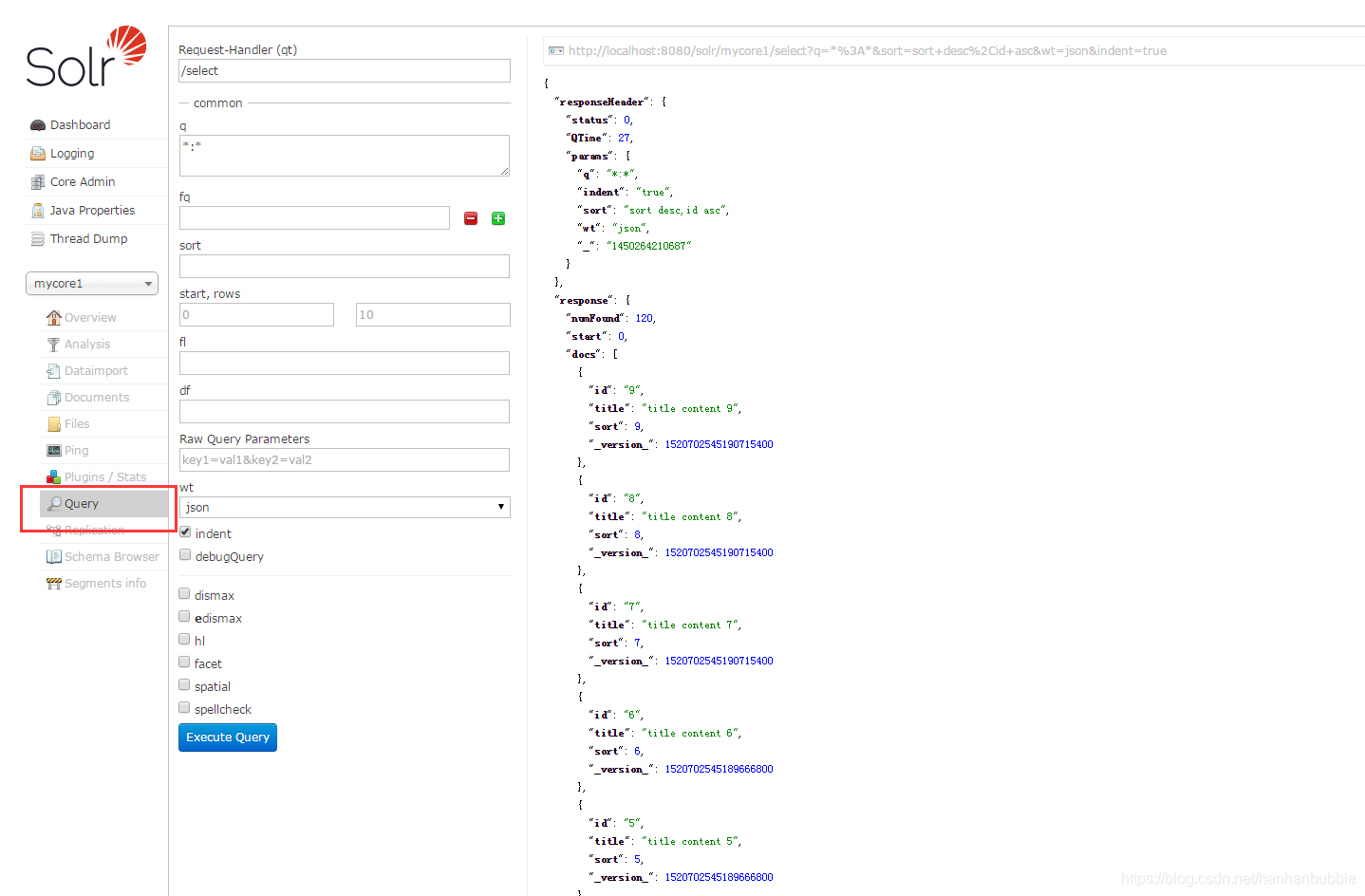
一.基本查询
q 查询的关键字,此参数最为重要,例如,q=id:1,默认为q=:,
fl 指定返回哪些字段,用逗号或空格分隔,注意:字段区分大小写,例如,fl= id,title,sort
start 返回结果的第几条记录开始,一般分页用,默认0开始
rows 指定返回结果最多有多少条记录,默认值为 10,配合start实现分页
sort 排序方式,例如id desc 表示按照 “id” 降序
wt (writer type)指定输出格式,有 xml, json, php等
fq (filter query)过虑查询,提供一个可选的筛选器查询。返回在q查询符合结果中同时符合的fq条件的查询结果,例如:q=id:1&fq=sort:[1 TO 5],找关键字id为1 的,并且sort是1到5之间的。
df 默认的查询字段,一般默认指定。
qt (query type)指定那个类型来处理查询请求,一般不用指定,默认是standard。
indent 返回的结果是否缩进,默认关闭,用 indent=true|on 开启,一般调试json,php,phps,ruby输出才有必要用这个参数。
version 查询语法的版本,建议不使用它,由服务器指定默认值。
二. Solr的检索运算符
“:” 指定字段查指定值,如返回所有值*?
“?” 表示单个任意字符的通配
“” 表示多个任意字符的通配(不能在检索的项开始使用或者?符号)
“~” 表示模糊检索,如检索拼写类似于”roam”的项这样写:roam将找到形如foam和roams的单词;roam0.8,检索返回相似度在0.8以上的记录。
AND、|| 布尔操作符
OR、&& 布尔操作符
NOT、!、-(排除操作符不能单独与项使用构成查询)
“+” 存在操作符,要求符号”+”后的项必须在文档相应的域中存在²
( ) 用于构成子查询
[] 包含范围检索,如检索某时间段记录,包含头尾,date:[201507 TO 201510]
{} 不包含范围检索,如检索某时间段记录,不包含头尾date:{201507 TO 201510}
三. 高亮
h1 是否高亮,hl=true,表示采用高亮
hl.fl 设定高亮显示的字段,用空格或逗号隔开的字段列表。要启用某个字段的highlight功能,就得保证该字段在schema中是stored。如果该参数未被给出,那么就会高亮默认字段 standard handler会用df参数,dismax字段用qf参数。你可以使用星号去方便的高亮所有字段。如果你使用了通配符,那么要考虑启用hl.requiredFieldMatch选项。
hl.requireFieldMatch 如果置为true,除非用hl.fl指定了该字段,查询结果才会被高亮。它的默认值是false。
hl.usePhraseHighlighter 如果一个查询中含有短语(引号框起来的)那么会保证一定要完全匹配短语的才会被高亮。
hl.highlightMultiTerm 如果使用通配符和模糊搜索,那么会确保与通配符匹配的term会高亮。默认为false,同时hl.usePhraseHighlighter要为true。
hl.fragsize 返回的最大字符数。默认是100.如果为0,那么该字段不会被fragmented且整个字段的值会被返回。
四. 分组
官方wiki:http://wiki.apache.org/solr/SimpleFacetParameters#Facet_Fields_and_Facet_Queries,
这是facet的官方wiki,里面有facet各个参数的详细说明。所以这里只说一些常用的。
Facet是Solr的核心搜索功能,主要是导航(Guided Navigation)、参数化查询(Paramatic Search)。Facet的主要好处是在搜索的同时,可以按照Facet条件进行分组统计,给出导航信息,改善搜索体验。
Facet主要分为:Field Facet 和 Date Facet 两大类
1. Field Facet
facet 参数字段必须被索引
facet=on 或 facet=true
facet.field 分组的字段
facet.prefix 表示Facet字段前缀
facet.limit Facet字段返回条数
facet.offict 开始条数,偏移量,它与facet.limit配合使用可以达到分页的效果
facet.mincount Facet字段最小count,默认为0
facet.missing 如果为on或true,那么将统计那些Facet字段值为null的记录
facet.sort 表示 Facet 字段值以哪种顺序返回 .格式为 true(count)|false(index,lex),true(count) 表示按照 count 值从大到小排列,false(index,lex) 表示按照字段值的自然顺序 (字母 , 数字的顺序 ) 排列 . 默认情况下为 true(count)
2. Date Facet
对日期类型的字段进行 Facet. Solr 为日期字段提供了更为方便的查询统计方式 .注意 , Date Facet的字段类型必须是 DateField( 或其子类型 ). 需要注意的是 , 使用 Date Facet 时 , 字段名 , 起始时间 , 结束时间 , 时间间隔这 4 个参数都必须提供 .
facet.date 该参数表示需要进行 Date Facet 的字段名 , 与 facet.field 一样 , 该参数可以被设置多次 , 表示对多个字段进行 Date Facet.
facet.date.start 起始时间 , 时间的一般格式为 ” 2015-12-31T23:59:59Z”, 另外可以使用 ”NOW”,”YEAR”,”MONTH” 等等 ,
facet.date.end 结束时间
facet.date.gap 时间间隔,如果 start 为 2015-1-1,end 为 2016-1-1,gap 设置为 ”+1MONTH” 表示间隔1 个月 , 那么将会把这段时间划分为 12 个间隔段 .
facet.date.hardend 表示 gap 迭代到 end 时,还剩余的一部分时间段,是否继续去下一个间隔. 取值可以为 true|false, 默认为 false.
例 start 为 2015-1-1,end 为 2015-12-21,gap 为 ”+1MONTH”, 如果hardend 为 false,则,最后一个时间段为 2015-12-1 至 2016-1-1; 反之,如果 hardend 为 true,则,最后一个时间段为 2015-12-1 至 2015-12-21.
注意:Facet的字段必须被索引,无需分词,无需存储。无需分词是因为该字段的值代表了一个整体概念,无需存储是因为一般而言用户所关心的并不是该字段的具体值,而是作为对查询结果进行分组的一种手段,给出相关的分组信息,从而改善搜索体验。
Solr 新增、更新、删除索引
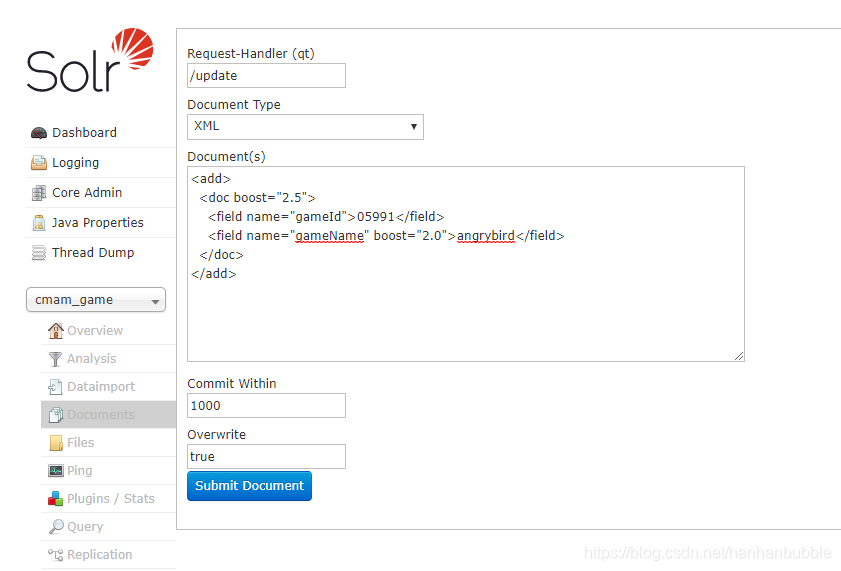
[索引中无则新增,有则更新]
1.在doc标签和field标签中增加权重(boost),增加权重后,可以在搜索的时候做权重过滤。
<add>
<doc boost="2.5">
<field name="gameId">05991</field>
<field name="gameName" boost="2.0">angrybird</field>
</doc>
</add>
2.field标签
update = “add” | “set” | “inc” 在4.0之后的版本可以自动对field做增加和删除了。
增加字段例子
<add>
<doc>
<field name="gameId">05991</field>
<field name="gameName" update="set">angrybird</field>
<field name="skills" update="add">fly</field>
</doc>
</add>
同一个字段多个值的例子
<add>
<doc>
<field name="gameId">05991</field>
<field name="skills" update="set">fly</field>
<field name="skills" update="set">shot</field>
<field name="skills" update="set">dump</field>
</doc>
</add>
把字段清空的例子
<add>
<doc>
<field name="gameId">05991</field>
<field name="skills" update="set" null="true" />
</doc>
</add>
添加json格式的索引和xml的类似,只需要在Document Type中选择json即可。
{"id":"s10001","name":"江小白"}
solr-admin 删除索引
<delete>
<query> id:"100861"</query>
</delete>
<commit/>
OR
<delete><id>100861</id></delete>
<commit/>
删除所有索引
<delete><query>*:*</query></delete>
<commit/>
说明:本文章参考多篇不同平台博主文章,如有侵权请联系撤销;

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









