




 本文深入探讨了浏览器缓存的工作原理,包括通过Expires和Cache-Control响应头控制缓存策略。介绍了如何通过添加时间戳、设置cache-control来避免浏览器缓存问题,强调了正确设置缓存控制的重要性,以及缓存机制在提高网页加载速度中的作用。
本文深入探讨了浏览器缓存的工作原理,包括通过Expires和Cache-Control响应头控制缓存策略。介绍了如何通过添加时间戳、设置cache-control来避免浏览器缓存问题,强调了正确设置缓存控制的重要性,以及缓存机制在提高网页加载速度中的作用。
本文主题:理清浏览器的缓存机制的内部逻辑,并给出避免浏览器缓存的相关解决方案
相信很多新手前端发布页面的时候都会遇到一个问题,就是明明页面已经更新了,但是浏览器浏览页面并没有变化,那么如何解决这个问题呢?
事实上,这个问题各种搜索引擎搜索之后会发现有很多的方案,但不一定有效,一般的解决方案有以下的两种:1:添加时间戳;2:cache-control。
首先第一种,就是在你的所有静态资源文件后面添加随机时间戳,例如你的页面里面用到了test.js,那你修改过test.js在html页面中的引用就要改成像下面这个样子
<script type="text/javascript" src="https://resources.test.com/js/test.js?version=56965"></script>每次修改test.js之后修改version后面的时间戳,这样浏览器就会忽略缓存从服务器请求新的文件,但是,真正这么做了之后,还是会发现,即使所有修改过的文件在应用的时候都添加了时间戳了,但是页面缓存还是没有清除,这又是为什么呢?原因很简单,你只对你修改过的文件添加了时间戳,但是html页面本身在这个时候已经被修改了,html页面是所有静态资源的载体,如果不对它加上时间戳,所有的其他应用都会沿用旧的缓存,所以,这个时候要让缓存失效,只需要在你的访问的网址上面再添加一个时间戳,例如:http://www.test.com/index.html?version=123456。
但很明显,这种做法其实很不优雅,例如网站的访问地址是不能经常变更的,所以这种方法其实使用收到很大程度的限制,接下来是第二种方法,cache-control。
网上很多教程都会写在meta标签上添加cache-control,大概像下面这个样子
<meta name="Cache-Control" content="no-cache">但是,这样做,一点卵用都没有,这样完全没办法避免浏览器的缓存,添加cache-control没错,但是需要在响应头添加,我们都知道,客户端跟服务端的交互用的都是http协议,由服务端回传给客户端的数据我们称之为响应数据,分为响应头(Response Headers)和响应体(Response Body),响应头一般用于指导浏览器以什么样的方式呈现数据,例如编码,解码,压缩,请求能否跨域等操作,Cache-Control是其中的一个,用来指导浏览器如何管理缓存,下面我们详细说一下如何浏览器的缓存机制,然后再说说如何通过响应头来控制浏览器的缓存,我们首先来看一张流程图
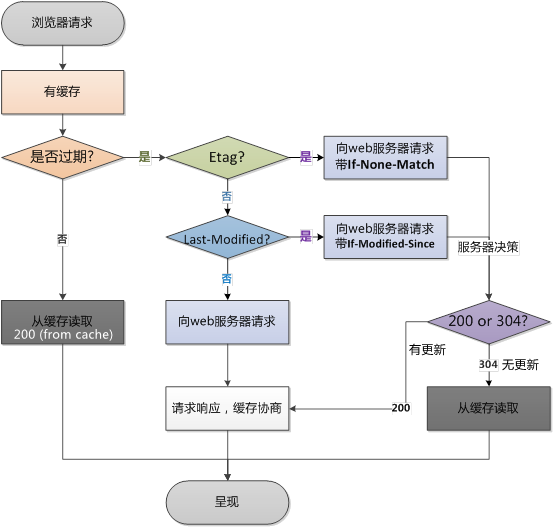
这张图片是浏览器访问一个有缓存的页面的时候的决策流程,大体上的流程是这样子的,当你访问一个以前访问过的页
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1426
1426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









