




 本文介绍了如何使用Python的pandas库中的drop_duplicates函数对Excel数据进行去重操作。通过设置subset参数指定按特定列去重,同时讲解了inplace和keep参数的用法,演示了保留首次出现值的过程。
本文介绍了如何使用Python的pandas库中的drop_duplicates函数对Excel数据进行去重操作。通过设置subset参数指定按特定列去重,同时讲解了inplace和keep参数的用法,演示了保留首次出现值的过程。
写在前面的Tips:
- 使用函数drop_duplicates
- 其中参数subset可以指定按照某字段进行去重。效果如下图
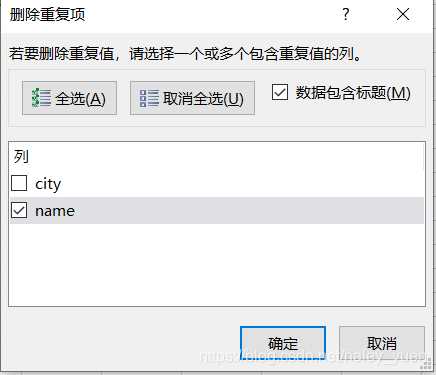
- 参数inpalce默认为False,若为True则直接在原数据上做修改(不推荐,风险较大)
- 参数keep, 若='first’则保留第一次出现的值,若='last’保留最后一次出现的值,若='false’表示一条都不保留
下面是代码演示
import pandas as pd
import openpyxl
datadir = r"C:\Users\Haley\Desktop\test_duplicates_data.xlsx"
data = pd.read_excel(datadir, sheet_name='OriginalData')
da 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1251
1251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









