



 本文详细解析了pandas库中rank函数的工作原理,包括如何处理平级关系、不同排名方法(如'min'、'max'、'first'等)及升序与降序排列。适用于希望深入了解数据排名处理的Python数据分析师。
本文详细解析了pandas库中rank函数的工作原理,包括如何处理平级关系、不同排名方法(如'min'、'max'、'first'等)及升序与降序排列。适用于希望深入了解数据排名处理的Python数据分析师。
rank函数:通过为各组分配一个平均排名的方式来破坏平级关系
对Series来说:
1、返回的是排名,把原数据升序(默认)后每个值所在的排名位置返回到原来所在的位置的索引所在的行。有相同的数时,取其排名平均(默认)作为值。
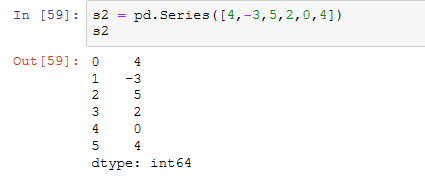
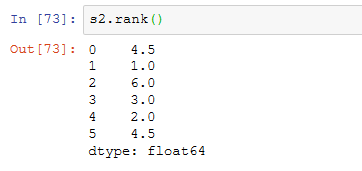
下面是我理解的过程:
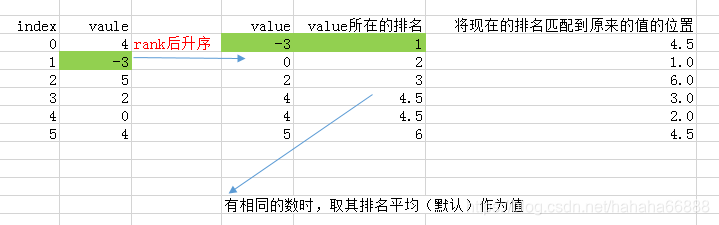
2、rank参数为 method='first' 时,对于相同的数,先出现的数值排名靠前,不再取其平均位置,按顺序排名
3、参数为 ascending=False 降序排列

4、method='max' 使用整个分组的最大排名
5、method='min' 使用整个分组的最小排名
对DataFrame同理:
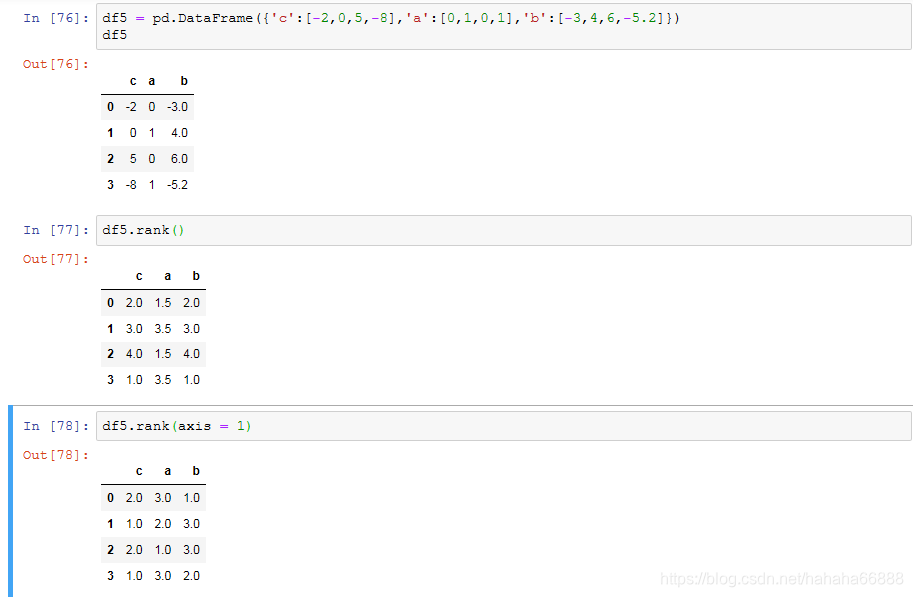

















 444
444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









