



今天讲述的内容仍然是GAN中的模式崩溃问题,首先将说明模式崩溃问题的本质,并介绍两种解决模式崩溃问题的思路,然后将介绍一种简单而有效的解决方案MAD-GAN,最后一部分将给出MAD-GAN的强化版本MAD-GAN-Sim。
作者&编辑 | 小米粥
1. 解决模式崩溃的两条路线
GAN的模式崩溃问题,本质上还是GAN的训练优化问题,理论上说,如果GAN可以收敛到最优的纳什均衡点,那模式崩溃的问题便自然得到解决。举例如下图,红线代表生成数据的概率密度函数,而蓝线代表训练数据集的概率密度函数,本来红线只有一个模式,也就是生成器几乎只会产生一种样本,而在理论上的最优解中,红线与蓝线重合,这时候在生成器中采样自然能几乎得到三种样本,与训练集的数据表现为一致。
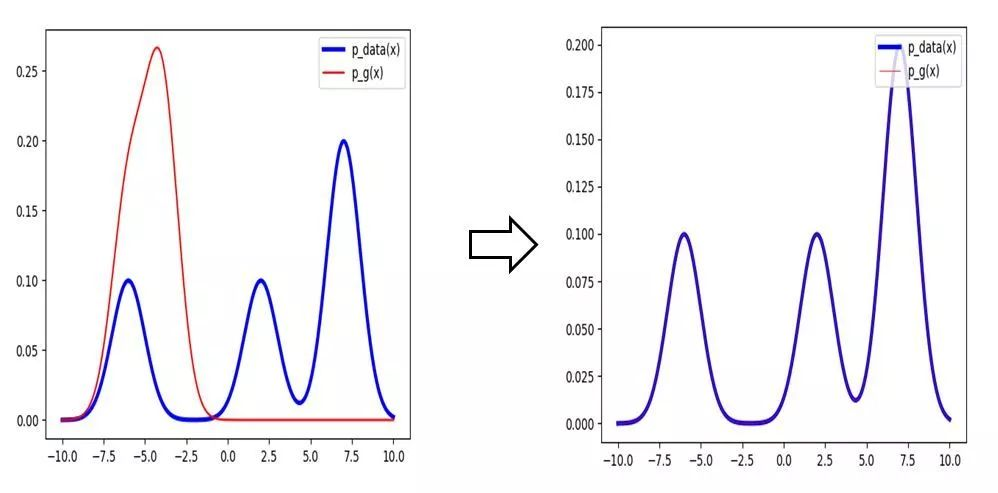
当然,实际中几乎不会达到全局最优解,我们看似收敛的GAN其实只是进入了一个局部最优解。故一般而言,我们有两条思路解决模式崩溃问题:
1.提升GAN的学习能力,进入更好的局部最优解,如下图所示,通过训练红线慢慢向蓝线的形状、大小靠拢,比较好的局部最优自然会有更多的模式,直觉上可以一定程度减轻模式崩溃的问题。
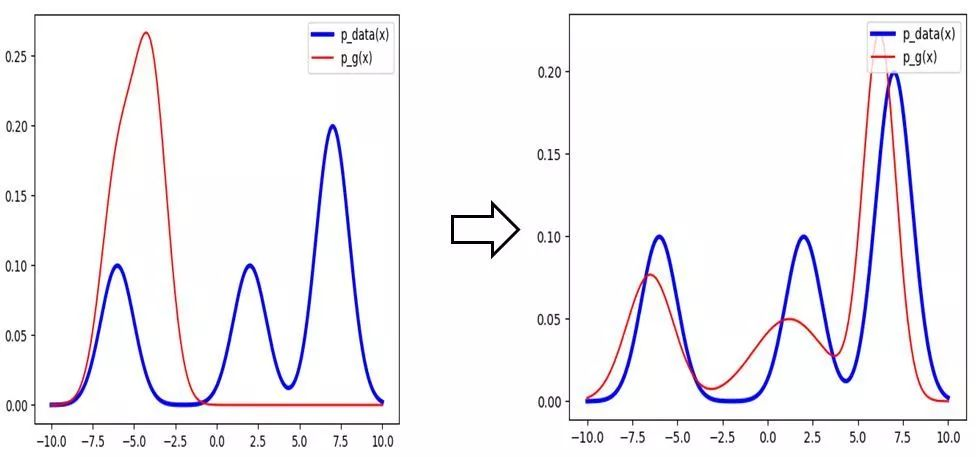
例如上一期unrolled GAN,便是增加了生成器“先知”能力;
2.放弃寻找更优的解,只在GAN的基础上,显式地要求GAN捕捉更多的模式(如下图所示),虽然红线与蓝线的相似度并不高,但是“强制”增添了生成样本的多样性,而这类方法大都直接修改GAN的结构。

2. MAD-GAN
今天要介绍的MAD-GAN及其变体便是第二类方法的代表之一。
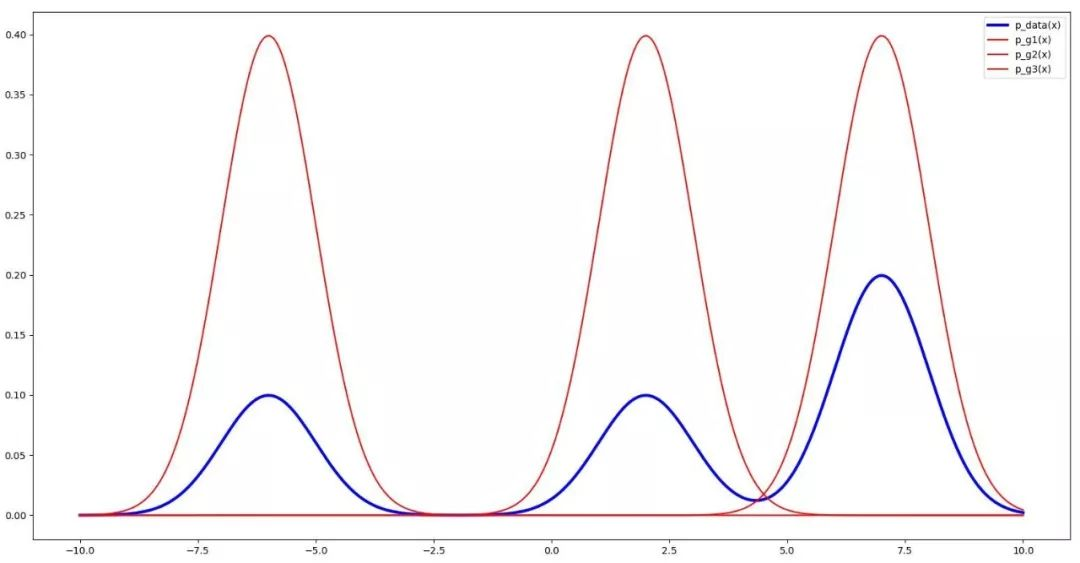
它的核心思想是这样的:即使单个生成器会产生模式崩溃的问题,但是如果同时构造多个生成器,且让每个生成器产生不同的模式,则这样的多生成器结合起来也可以保证产生的样本具有多样性,如下图的3个生成器:
需要说明一下,简单得添加几个彼此孤立的生成器并无太大意义,它们可能会归并成相同的状态,对增添多样性并无益处,例如下图的3个生成器:
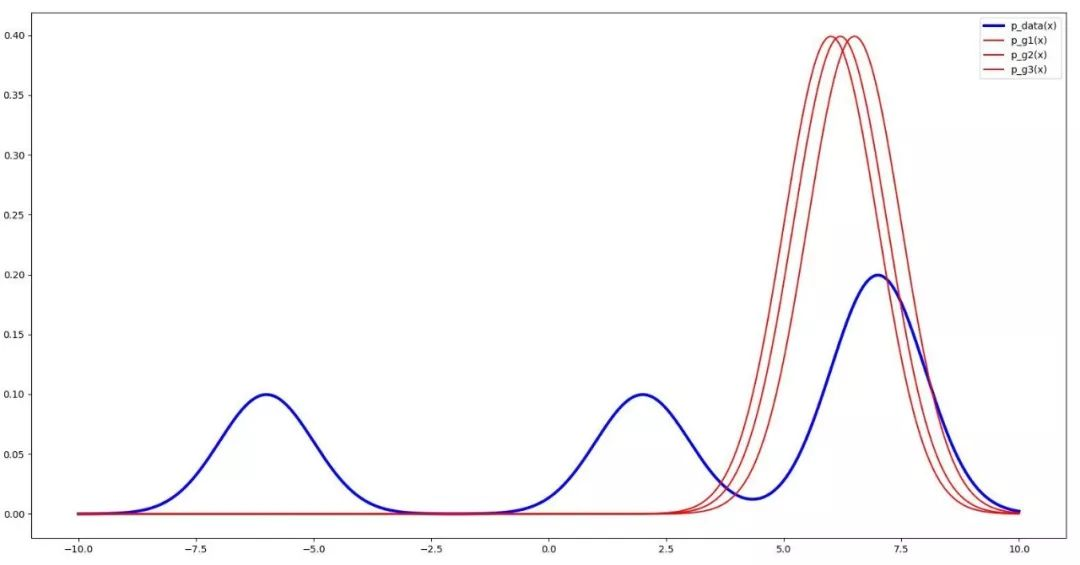
理想的状态是:多个生成器彼此“联系”,不同的生成器尽量产生不相似的样本,而且都能欺骗判别器。
在MAD(Multi-agent diverse)GAN中,共包括k个初始值不同的生成器和1个判别器,与标准GAN的生成器一样,每个生成器的目的仍然是产生虚假样本试图欺骗判别器。对于判别器,它不仅需要分辨样本来自于训练数据集还是其中的某个生成器(这仍然与标准GAN的判别器一样),而且还需要驱使各个生成器尽量产生不相似的样本。
需要将判别器做一些修改:将判别器最后一层改为k+1维的softmax函数,对于任意输入样本x,D(x)为k+1维向量,其中前k维依次表示样本x来自前k个生成器的概率,第k+1维表示样本x来自训练数据集的概率。同时,构造k+1维的delta函数作为标签,如果x来自第i个生成器,则delta函数的第i维为1,其余为0,若x来自训练数据集,则delta函数的第k+1维为1,其余为0。显然,D的目标函数应为最小化D(x)与delta函数的交叉熵:
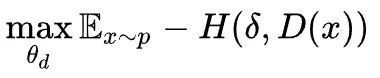
直观上看,这样的损失函数会迫使每个x尽量只产生于其中的某一个生成器,而不从其他的生成器中产生,将其展开则为:
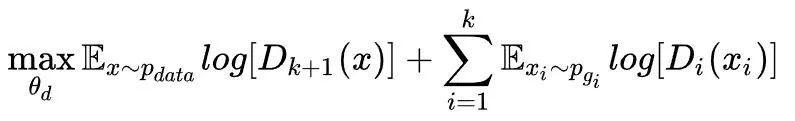
生成器目标函数为:
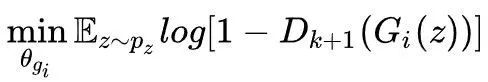
对于固定的生成器,最优判别器为:
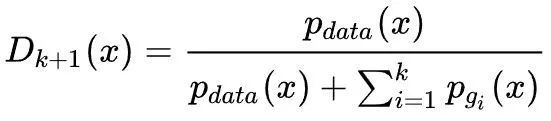
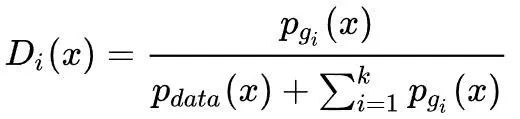
可以看出,其形式几乎同标准形式的GAN相同,只是不同生成器之间彼此“排斥”产生不同的样本。另外,可以证明当
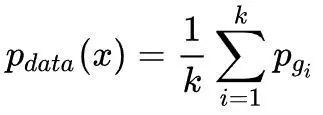
达到最优解,再一次可以看出,MAD-GAN中并不需要每个生成器的生成样本概率密度函数逼近训练集的概率密度函数,每个生成器都分别负责生成不同的样本,只须保证生成器的平均概率密度函数等于训练集的概率密度函数即可。
3. MAD-GAN-Sim
MAD-GAN-Sim是一种“更强力”的版本,它不仅考虑了每个生成器都分别负责生成不同的样本,而且更细致地考虑了样本的相似性问题。其出发点在于:来自于不同模式的样本应该是看起来不同的,故不同的生成器应该生成看起来不相似的样本。
这一想法用数学符号描述即为:
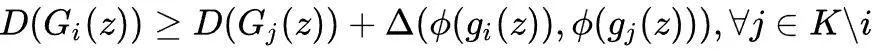
其中φ (x)表示从生成样本的空间到特征空间的某种映射(我们可选择生成器的中间层,其思想类似于特征值匹配),Δ (x,y)表示相似度的度量,多选用余弦相似度函数,用于计算两个样本对应的特征的相似度。
对于给定的噪声输入z,考虑第i个生成器与其他生成器的样本生成情况,若样本相似度比较大,则D(G_i(z))相比较D(G_j(z))应该大很多,由于D(G_j(z))的值比较小,G_j(z)便会进行调整不再生成之前的那个相似的样本,转而去生成其他样本,利用这种“排斥”机制,我们就实现了让不同的生成器应该生成看起来不相似的样本。
将上述限制条件引入到生成器中,我们可以这样训练生成器,对于任意生成器i,对于给定的z,如果上面的条件满足,则像MAD-GAN一样正常计算,其梯度为:
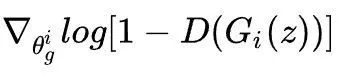
如果条件不满足,将上述条件作为正则项添加到目标函数中,则其梯度为:
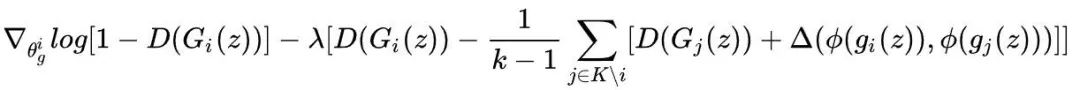
这样尽量使得判别器更新后,条件能够满足。MAD-GAN-Sim的思路非常直接清晰,不过代价就是增加非常多的计算量。
[1]Ghosh A , Kulharia V , Namboodiri V , et al. Multi-Agent Diverse Generative Adversarial Networks[J]. 2017.
总结
今天首先说明了模式崩溃问题的本质,并介绍两种解决模式崩溃问题的思路,然后介绍一种简单而有效的解决方案MAD-GAN及其强化版本MAD-GAN-Sim。
知识星球推荐

有三AI知识星球由言有三维护,内设AI知识汇总,AI书籍,网络结构,看图猜技术,数据集,项目开发,Github推荐,AI1000问八大学习板块。
当前更新的主题就是各种各样的GAN的结构解读和实践,感兴趣的同学可以加入一起学习,添加有三微信Longlongtogo即可优惠。

GAN群

有三AI建立了一个GAN群,便于有志者相互交流。感兴趣的同学也可以微信搜索xiaozhouguo94,备注"加入有三-GAN群"。
转载文章请后台联系
侵权必究

往期精选


















 114
114

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











