



今天将和大家一起学习具有很高知名度的SNGAN。之前提出的WGAN虽然性能优越,但是留下一个难以解决的1-Lipschitz问题,SNGAN便是解决该问题的一个优秀方案。我们将先花大量精力介绍矩阵的最大特征值、奇异值,然后给出一个简单例子来说明如何施加1-Lipschitz限制,最后一部分讲述SNGAN。
作者&编辑 | 小米粥
在GAN中,Wasserstein距离比f散度拥有更好的数学性质,它处处连续,几乎处处可导且导数不为0,所以我们更多的使用Wasserstein距离。在上一期的结尾,我们得到critic(判别器)的目标函数为:
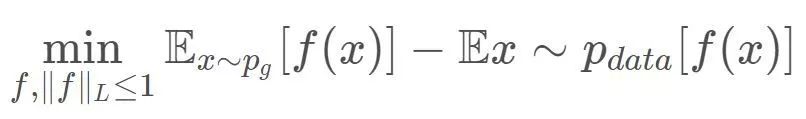
本篇所讲的SNGAN便是一种“严格”地解决了判别器1-Lipshcitz约束的方法。
1 最大特征值(奇异值)
我们从矩阵的特征值、奇异值开始说起。在线性代数中,Ax=b表示对向量x做矩阵A对应的线性变换,可以得到变换后的向量b。如果x为矩阵A对应的特征向量,则有:
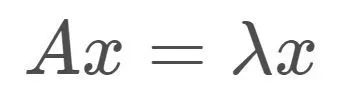
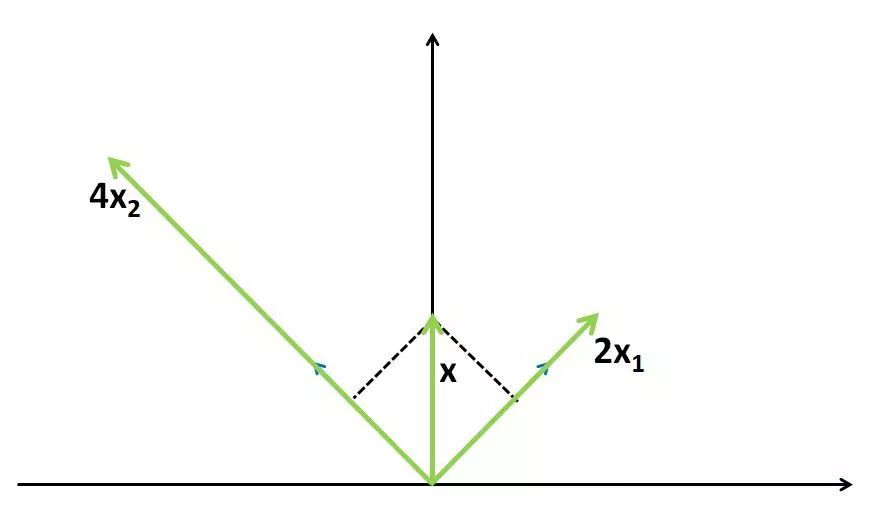
即对特征向量x做矩阵A对应的线性变换的效果是:向量方向不变,仅长度伸缩λ 倍!比如,对
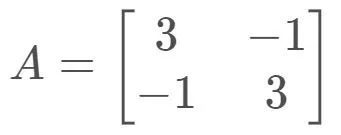
两个特征值、特征向量分别为:
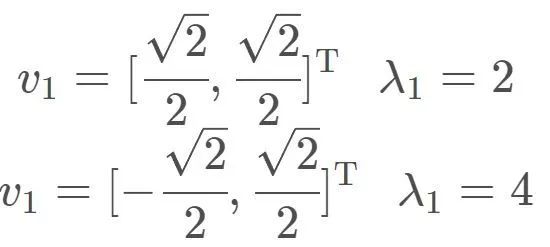
线性变换作用在特征向量的效果如下:
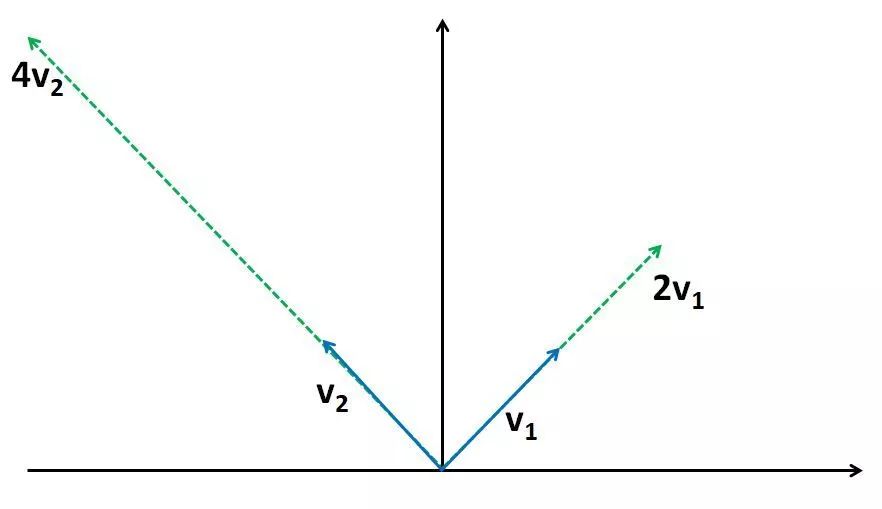
对于一般向量x,对其线性变换的中间运算过程可以分解为三步。例如对于计算Ax,其中x=[0,1],先将x分解到两个特征向量上:
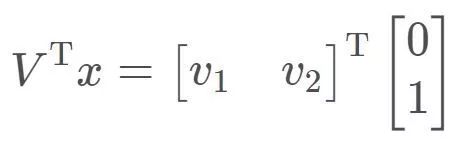
然后在两个特征向量方向上分别进行伸缩变换,有:
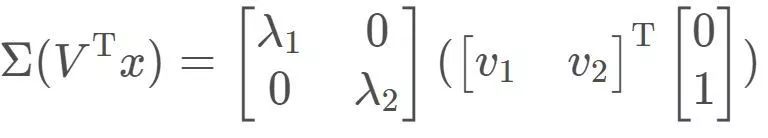
最后再进行简单的向量合成,可有:
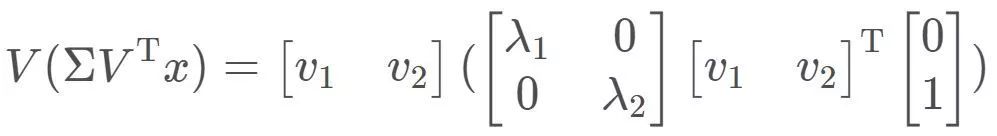
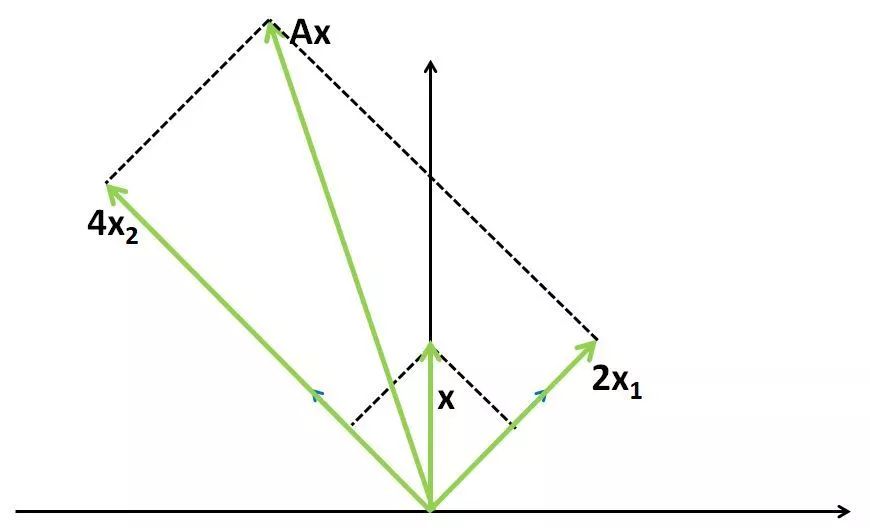
一般的,对于非奇异n阶方阵,有n个特征向量和与之对应的特征值,故n阶方阵A对应的线性变换操作其实可以分解成三步:将向量x先分解到n个特征向量对应的方向上(本质是求解x在以特征向量组成的基上的表示),分别进行伸缩变换(在特征向量组成的基上进行伸缩变换),最后进行向量合成(本质是求解得到的新向量在标准基上的表示)。这其实就是在描述熟悉的矩阵特征值分解:
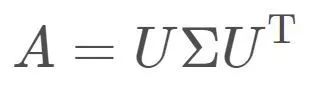
特征值是对应于方阵的情况,将其推广至一般矩阵,便可引出奇异值。奇异值分解形式为:

简单说,特征值分解其实是对线性变换中旋转、缩放两种效应的归并,奇异值分解正是对线性变换的旋转、缩放和投影三种效应的一个析构(当V的维度大于U的维度时存在投影效应)。
说了这么多,其实是为了直观地解释一个问题,对于任意单位向量x,Ax的最大值(这里使用向量的2范数度量值的大小)是多少?显然,x为特征向量v2时其值最大,因为这时的x全部“投影”到伸缩系数最大的特征向量上,而其他单位向量多多少少会在v1方向上分解出一部分,在v1方向上只有2倍的伸缩,不如在v2方向上4倍伸缩的值来的更大。这样,我们可以得到一个非常重要的式子:
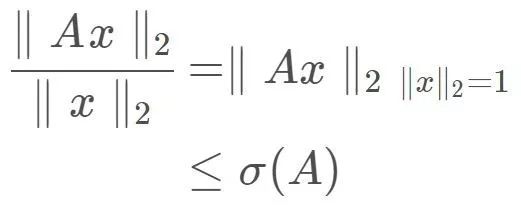
其中σ (A)表示A的最大特征值(奇异值),也称为A的谱范数。
2 Lipshcitz限制
所谓Lipshcitz限制,在最简单的一元函数中的形式即:
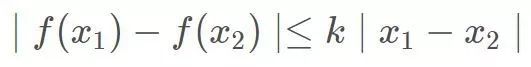
或者也可以写成:
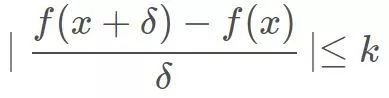
直观上看,它要求f(x)任意两点之间连线的“斜率”绝对值小于Lipshcitz常数k。在WGAN中要求k=1,1-Lipshcitz限制要求保证了输入的微小变化不会导致输出产生较大变化。我们常见的函数,比如分段线性函数|x|,连续函数sin(x)都显而易见的满足该限制:
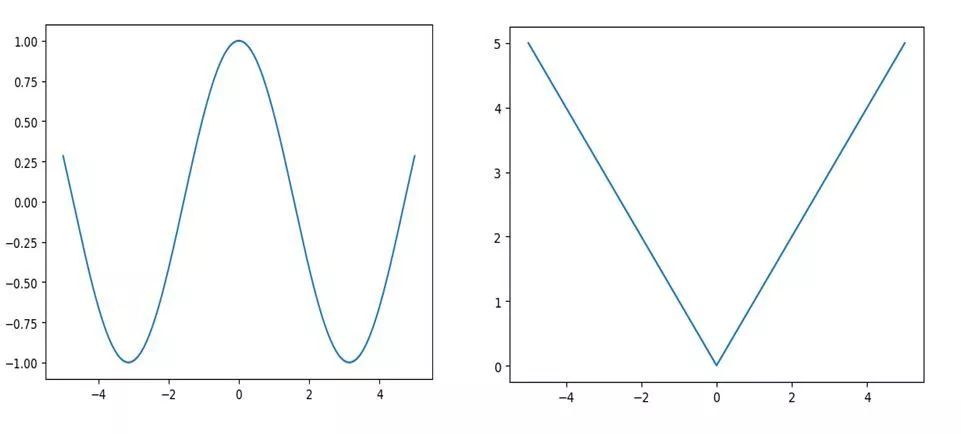
我们以一个最简单的例子来展示一下,如何使用谱范数施加1-Lipshcitz限制。考虑f(x)=Wx,其中
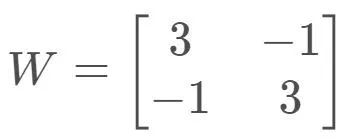
显然,f(x)=Wx不满足1-Lipshcitz限制,利用第一部分的结论,考虑到
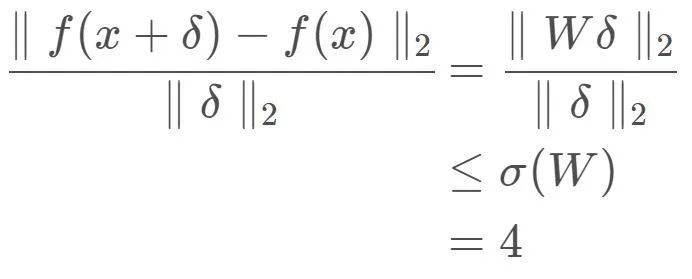
那么若将W整体缩小4倍,
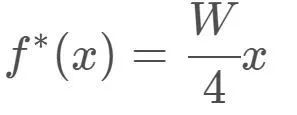
即可以得到:
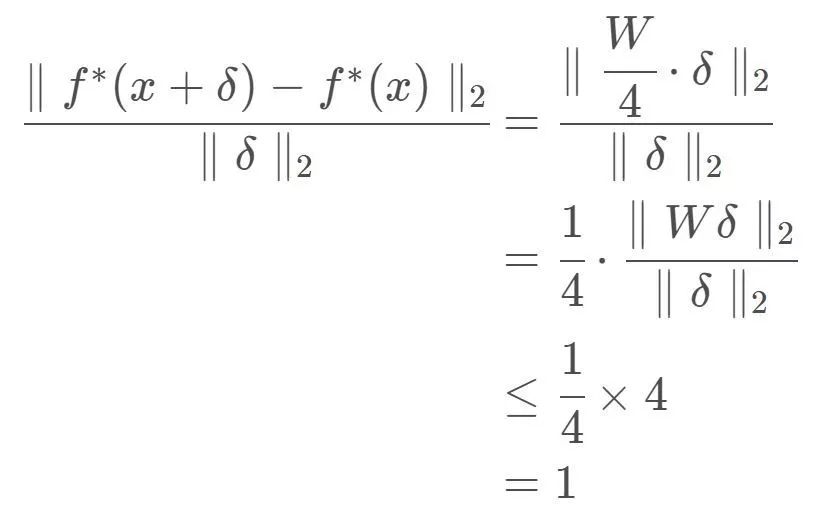
可以看出,虽然线性函数f(x)=Wx不满足1-Lipshcitz限制,但是可使用谱范数将W的”缩放大小“限定为小于等于1,(有点类似于向量的归一化操作)这样处理后的f*(x)可以满足1-Lipshcitz限制。接下来,我们将对这条思路进行补充、推广,最后得到SNGAN将是显而易见的事情了。
3 SNGAN
通常在神经网络中的每一层,先进行输入乘权重的线性运算,再将其送入激活函数,由于通常选用ReLU作为激活函数,ReLu激活函数可以用对角方阵D表示,如果Wx的第i维大于0,则D的第i个对角元素为1,否则为0,需要注意D的具体形式与W,x均有关系,但是D的最大奇异值必然是1。
因此,一般而言,即使神经网络的输出是非线性的,但是在x的一个足够小的邻域内,它一个表现为线性函数Wx,W的具体形式与x有关。真实的判别器f(x)的函数图像在比较小的尺度上来看应该是类似这种形式的分段函数:
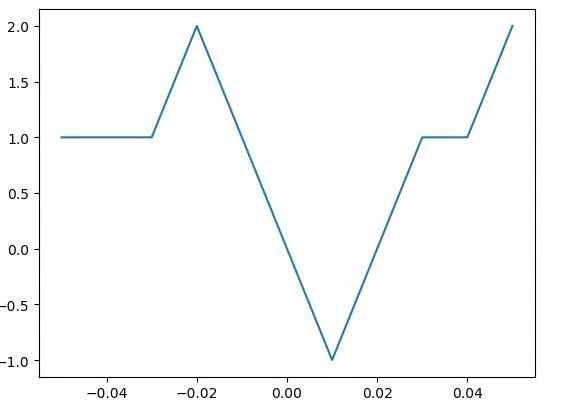
考虑到对于任意给定的x,均有:
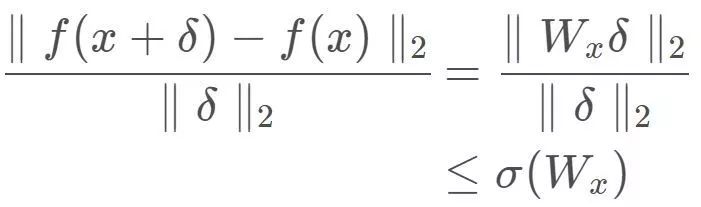
整体标记判别器各层的权值、偏置项:
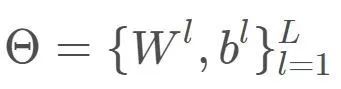
那么可以得到:
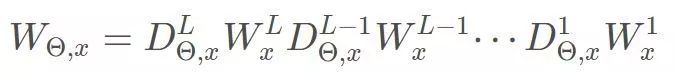
根据:
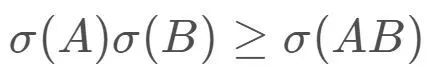
可得到:
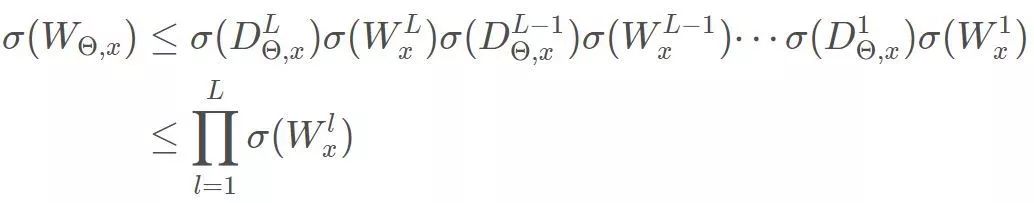
不必像第二部分所描述办法整体求解W的谱范数,充分利用上述不等式,我们只需要计算每层的权值矩阵的最大奇异值,即可完成1-Lipshcitz限制。
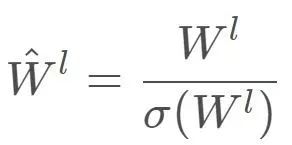
综上,有结论:对于任意x
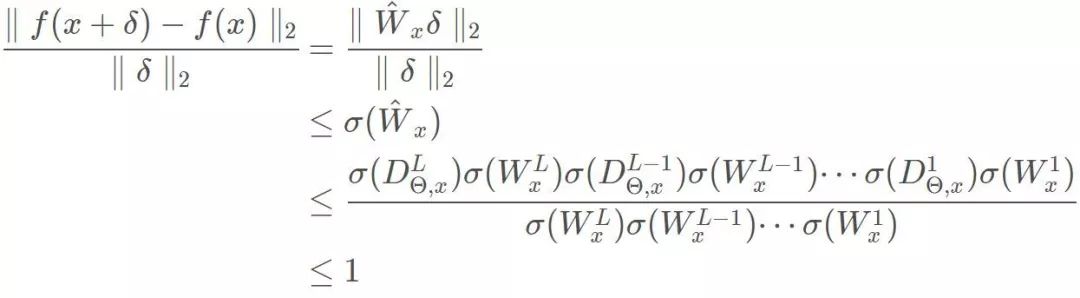
为了严格起见,需要说明,f(x)在x的任意邻域内都满足1-Lipshcitz限制,则f(x)在定义域上满足1-Lipshcitz限制。
其实这里有一个遗留的小问题,如何快速求解超大矩阵A的最大奇异值。在原论文中使用了一种幂方法(power method),随机给两个初始变量,然后令:
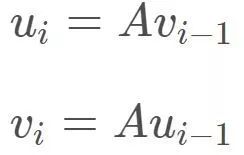
则经过数次迭代,便有
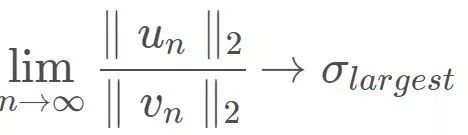
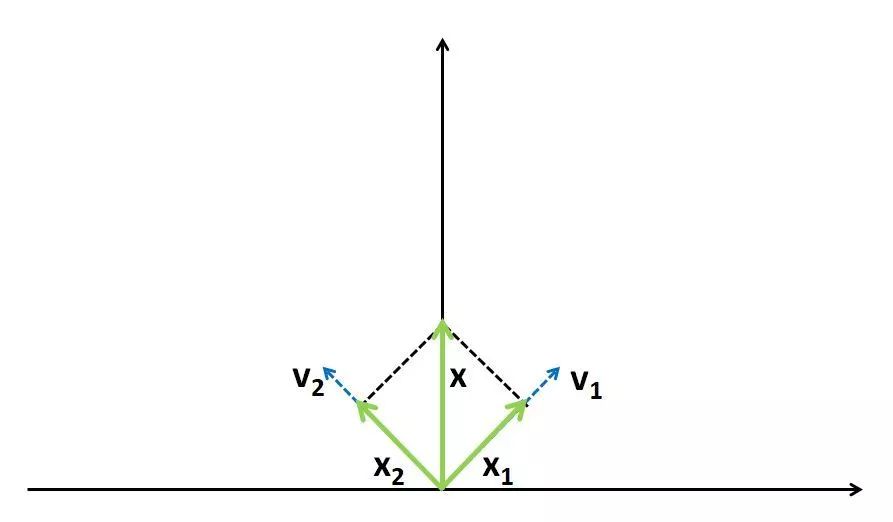
我们用求最大特征值的例子来辅助理解一下,A对向量x的线性变换的实质是对x在不同的特征向量方向进行伸缩,由于在不同的特征向量方向进行伸缩的幅度不同,造成的结果是:不断对x做A对应的线性变换,则x的方向不断靠近伸缩幅度最大的特征向量的方向,如下图
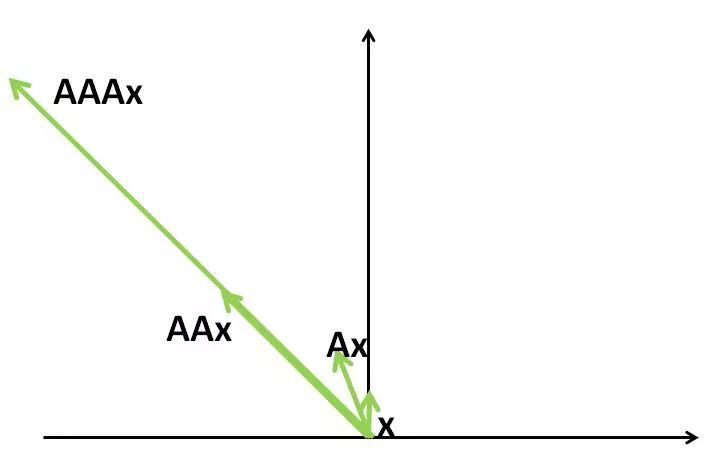
则经过足够次数的迭代,得到的新的向量方向与伸缩幅度最大的特征向量的方向重合,故每次迭代结果只差一个常数,即最大特征值。
[1] Yoshida, Yuichi , and T. Miyato . "Spectral Norm Regularization for Improving the Generalizability of Deep Learning." (2017).
[2] Miyato, Takeru , et al. "Spectral Normalization for Generative Adversarial Networks." (2018).
[3]Wasserstein GAN and the Kantorovich-Rubinstein Duality. https://vincentherrmann.github.io/blog/wasserstein/
总结
这篇文章带领大家一起学习了SNGAN,学习了特征值和奇异值相关问题,学习如何使用谱范数解决1-Lipschitz限制,并推导了SNGAN,最后给出了一个快速求解矩阵最大奇异值的方法。下一期的内容将比较“数学”一点,介绍一个个人非常喜欢的统一理论,它将WGAN和诸多GAN纳入一个框架。
下期预告:IPM与xGAN
GAN群

有三AI建立了一个GAN群,便于有志者相互交流。感兴趣的同学也可以微信搜索xiaozhouguo94,备注"加入有三-GAN群"。
知识星球推荐

有三AI知识星球由言有三维护,内设AI知识汇总,AI书籍,网络结构,看图猜技术,数据集,项目开发,Github推荐,AI1000问八大学习板块。
转载文章请后台联系
侵权必究


往期精选



















 1289
1289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











