



1、dbeaver简介
DBeaver 是一款开源、跨平台的通用数据库管理工具和 SQL 客户端,专为开发者、数据库管理员及数据分析师设计。以下是对其核心特性的综合介绍:
1. 多数据库支持
DBeaver 支持几乎所有主流数据库系统,包括关系型数据库(如 MySQL、PostgreSQL、Oracle、SQL Server、DB2)和 NoSQL 数据库(如 MongoDB、Redis、Cassandra)。其通过 JDBC 驱动实现广泛兼容,甚至可扩展至非 JDBC 数据源(如商业版支持的 DynamoDB 等)。
2. 核心功能
- SQL 编辑器:支持语法高亮、代码补全、执行计划分析、多标签页查询,以及快捷键操作(如单行执行
Ctrl+Enter、格式化Ctrl+Alt+F)。 - 数据管理:提供数据导入/导出(CSV、Excel、JSON 等)、批量编辑、BLOB/CLOB 数据处理功能。
- 元数据与结构管理:可浏览和编辑表、索引、键等数据库对象,生成 ER 图(实体关系图)以可视化数据库结构。
- 高级工具:包括数据比较与同步、日志分析、版本控制集成(Git/SVN),以及数据分析图表生成。
3. 跨平台与用户友好性
- 支持 Windows、macOS、Linux 及企业级系统(如 Solaris、HP-UX)。
- 界面简洁直观,支持主题定制和插件扩展(如 Eclipse 插件架构),满足个性化需求。
4. 开源与社区生态
- 遵循 Eclipse Public License,社区版免费且功能全面。
- 活跃的开发者社区持续更新,提供插件市场和问题反馈渠道。
5. 典型应用场景
- 开发环境:快速编写调试 SQL,设计数据库结构。
- 生产维护:备份恢复、性能监控。
- 数据分析:复杂查询与可视化报告生成。
2、下载
下载网址:Download | DBeaver Community
下载界面:
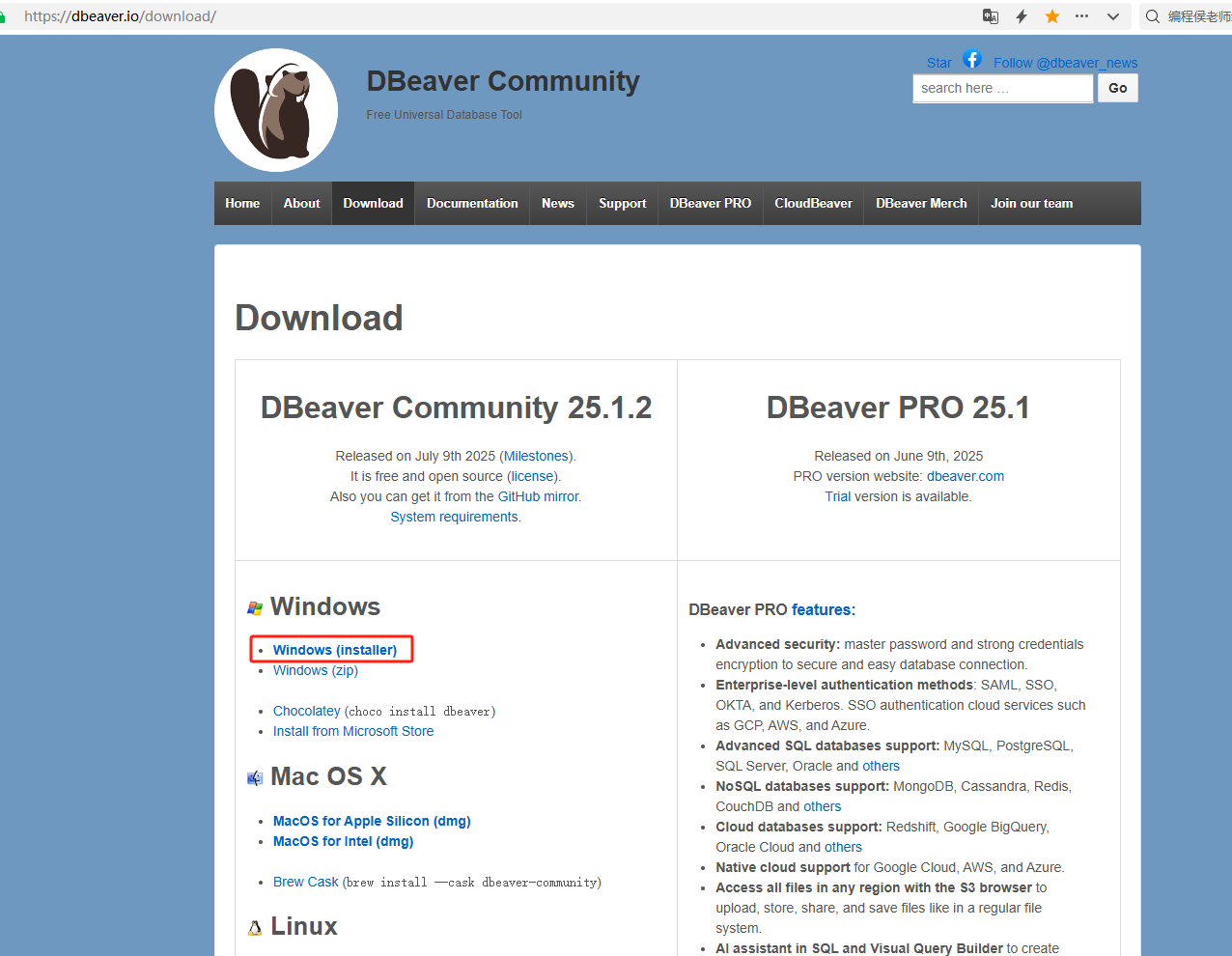
因为我安装到windows系统里,所以下载windows版本的
下载后:

3、安装部署
双击exe程序,自动一步一步安装即可
安装的时候让选择语言,选择中文就行
安装后,在桌面出现一个快捷图标

4、连接iotdb
双击图标

进入到dbeaver的工作界面
点击【数据库】->【新建数据库连接】
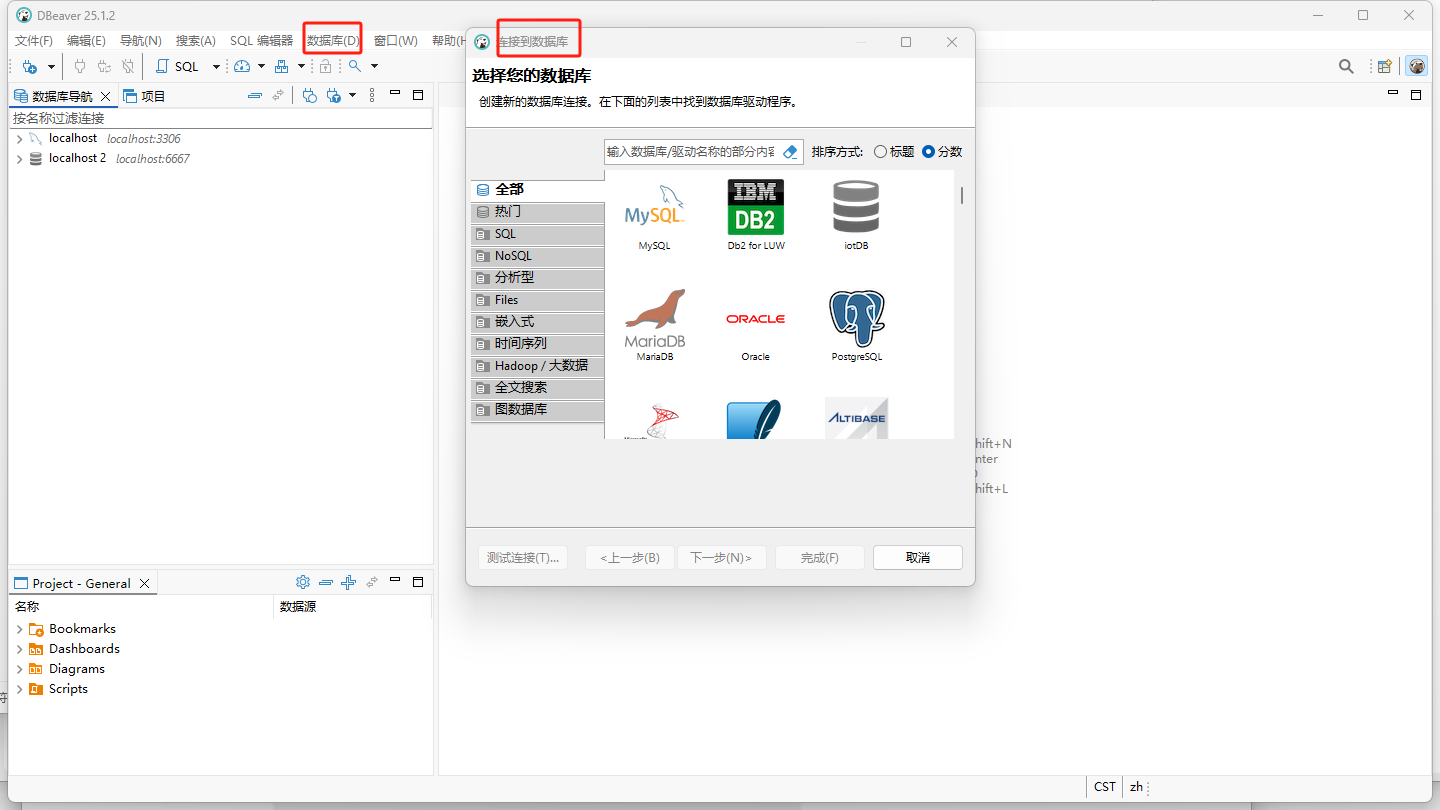
搜索iotdb是没有的,那么说明默认的是没有iotdb的驱动的
那么如何增加iotdb的驱动呢
1)下载iotdb jdbc 驱动
2)在dbeaver 中配置驱动
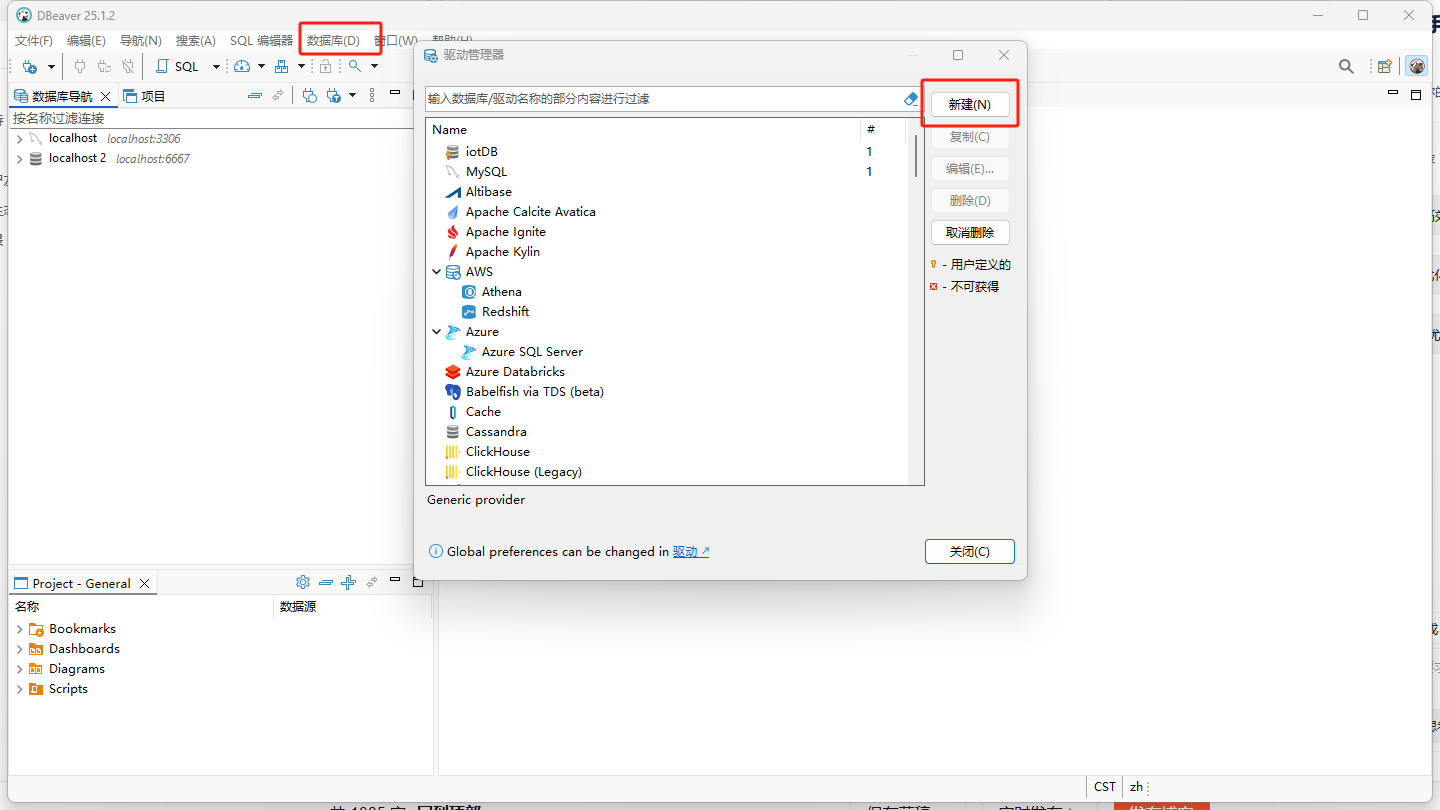
【数据库】-【驱动管理】-【新建】
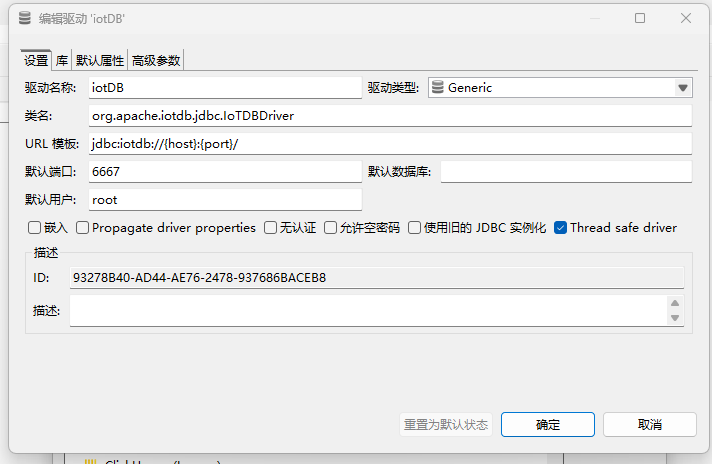
如上配置,
点击【库】页签,
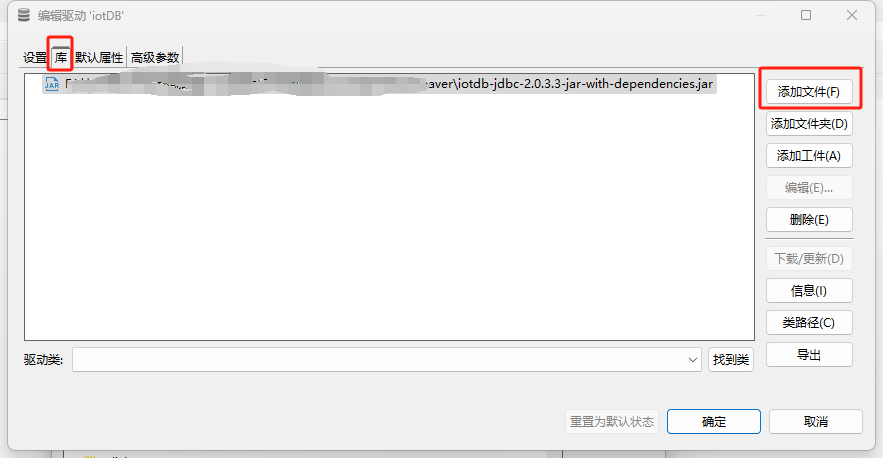
点击【添加文件】将下载的驱动加载进来
点击【确定】按钮
然后再重新点击【数据库】-【新建数据库连接】
搜索:iotdb
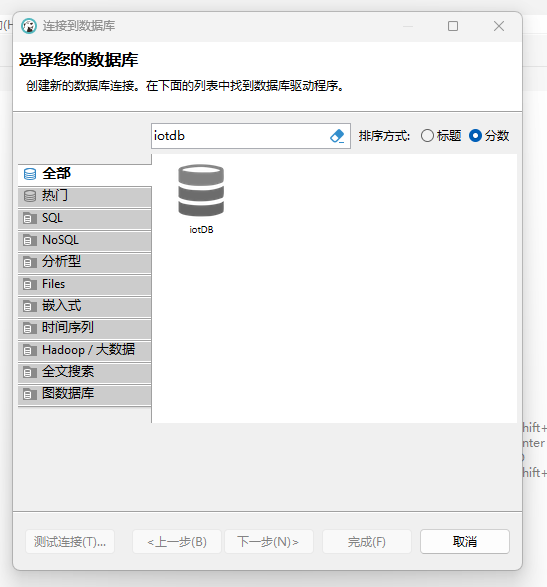
点击iotdb 图标,点击【下一步】
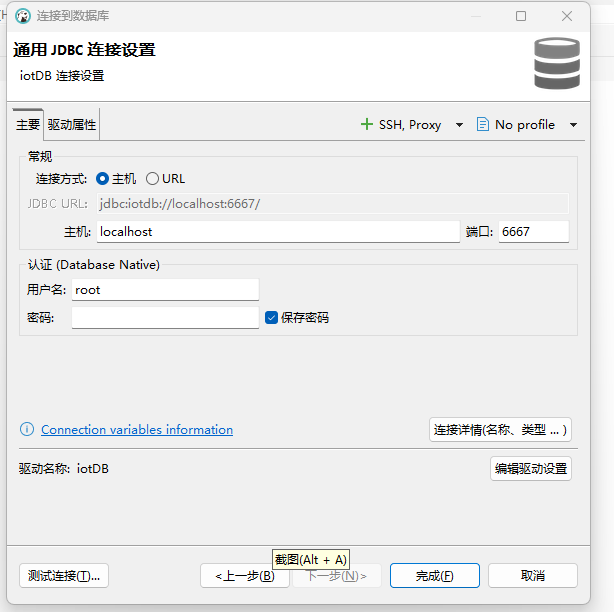
输入用户名,密码
点击【完成】
在左侧的链接区域,会出现新的链接
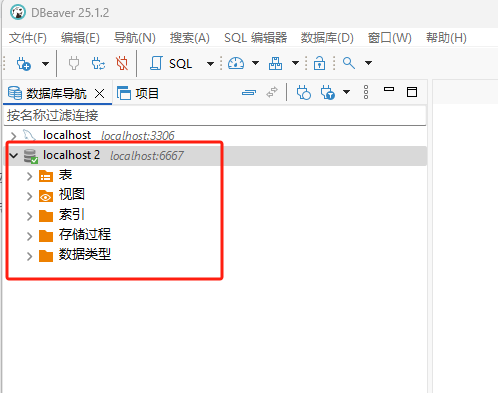
点击【表】
说明已经可以了
连接成功

















 3611
3611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









