






水平分库分表常见策略-range
水平分库分表,根据什么规则进行?怎么划分?
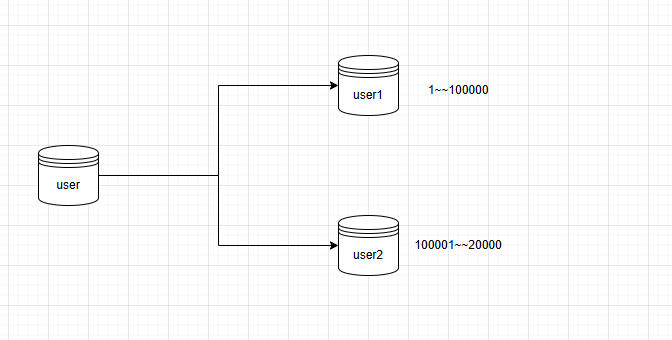
方案一:自增id,根据ID范围进行分表(左闭右开)
优点:id是自增长,可以无限增长;扩容不用迁移数据,容易理解和维护。
缺点:大部分读和写都会访问新的数据,有IO瓶颈,整体资源利用率低;数据倾斜严重,热点数据过于及中国,部分节点有瓶颈。
Range延伸
Range范围分库分表,有热点问题,这个方法也同样存在热点问题,那我们应该如何解决?
其中我们可以考虑按大区进行划分,一二线城市和三四线城市活跃度不一样,如果这个方法可以避免热点问题,即可以选择。但是还是要考虑具体的业务场景。
基于ID自增的扩展:
- 时间维度:我们可以根据年月日来进行生成库表
- 空间维度:我们可以根据地理位置如省份,区域(华东,华南等)来生成库表
Hash取模
方案二:hash取模(Hash分库分表是最普遍的方案)。
我们要将取模字段不是整数型的要先进行hash,统一规则后进行取模。

如:
库ID = userId % 库数量
表ID = userId % 库数量 %表数量
优点:保证数据较均匀的分散落在不同的库表中,可以有效的避免热点数据集中问题。
缺点:扩容不是很方便,需要数据迁移。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









