







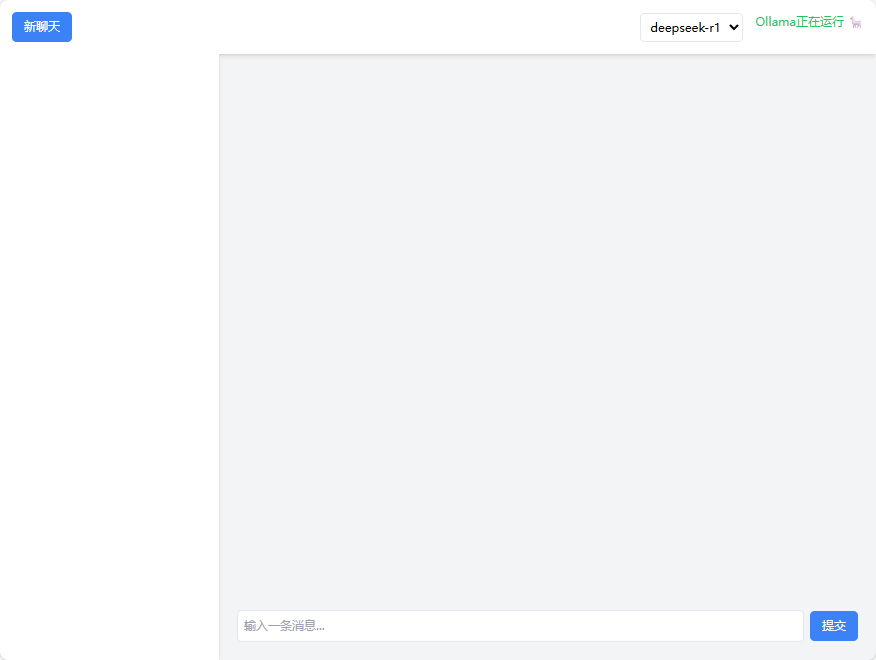
第4节: Ollama 流式应答页面对接
生成前端工具的AI v0 (这个效果更好,但是用多了要付费), deepseek, 智谱清言
对AI进行提问模板
请根据以下信息,编写UI对接服务端接口;
服务端接口 curl 'http://localhost:8090/api/v1/ollama/generate_stream?model=deepseek-r1:1.5b&message=1%2B1'
流式GET请求接口,由 SpringBoot Spring AI 框架实现,如下;
/**
* 流式接口 http://localhost:8090/api/v1/ollama/generate_stream?model=deepseek-r1:1.5b&message=hi
* @param model 模型名称
* @param message 用户输入
* @return 流式回答
*/
@RequestMapping(value = "generate_stream", method = RequestMethod.GET)
public Flux<ChatResponse> generateStream(String model, String message) {
return ollamaChatClient.stream(new Prompt(message, OllamaOptions.create().withModel(model)));
}
流式GET应答数据,数组中的一条对象;
[
{
"result": {
"output": {
"messageType": "ASSISTANT",
"properties": {
"id": "chatcmpl-B3HPw95SsqmhoWeJ8azGLxK1Vf4At",
"role": "ASSISTANT",
"finishReason": "STOP"
},
"content": null,
"media": []
},
"metadata": {
"finishReason": "STOP",
"contentFilterMetadata": null
}
}
}
]
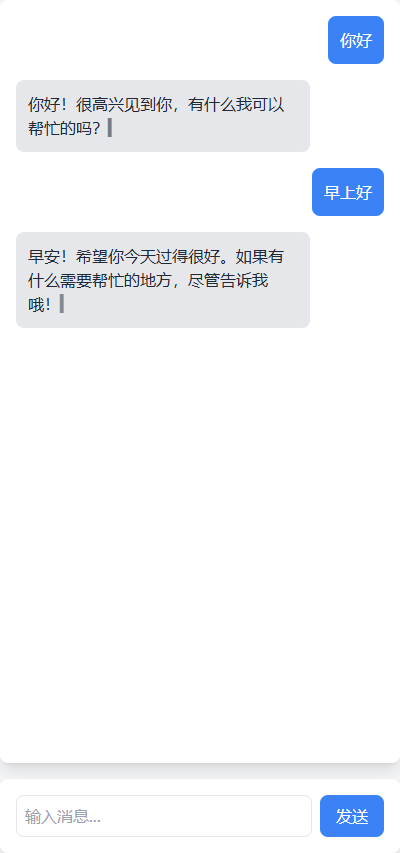
如描述说明,帮我编写一款简单的AI对话页面。
1. 输入内容,点击发送按钮,调用服务端流式请求接口,前端渲染展示。
2. 以html、js代码方式实现,css样式使用 tailwind 编写。
3. 通过 const eventSource = new EventSource(apiUrl); 调用api接口。
4. 从 result.output.content 获取,应答的文本展示。注意 content 可能为空。
5. 从 result.metadata.finishReason = STOP 获取,结束标识。
6. 注意整体样式的简洁美观。将得到的代码放入工程中即可
得到这样的AI助手
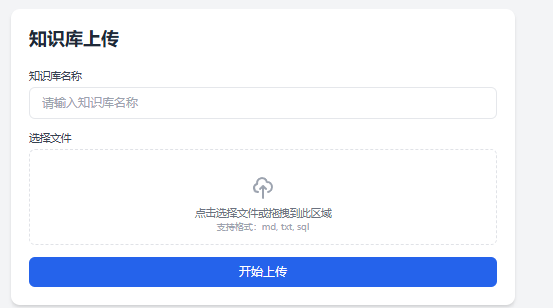
第5节: Ollama RAG知识库上传、解析和验证
- 添加数据库
datasource:
driver-class-name: org.postgresql.Driver
username: postgres
password: postgres
url: jdbc:postgresql://<自己的IP地址>:15432/<数据库名称>
type: com.zaxxer.hikari.HikariDataSource
# hikari连接池配置
hikari:
#连接池名
pool-name: HikariCP
#最小空闲连接数
minimum-idle: 5
# 空闲连接存活最大时间,默认10分钟
idle-timeout: 600000
# 连接池最大连接数,默认是10
maximum-pool-size: 10
# 此属性控制从池返回的连接的默认自动提交行为,默认值:true
auto-commit: true
# 此属性控制池中连接的最长生命周期,值0表示无限生命周期,默认30分钟
max-lifetime: 1800000
# 数据库连接超时时间,默认30秒
connection-timeout: 30000
# 连接测试query
connection-test-query: SELECT 1实例化向量库有两种方式
- 通过java对象配置
//实例化向量库
@Bean
public SimpleVectorStore simpleVectorStore(OllamaApi ollamaApi) {
OllamaEmbeddingClient embeddingClient = new OllamaEmbeddingClient(ollamaApi);
embeddingClient.withDefaultOptions(OllamaOptions.create().withModel("nomic-enbed-text"));
return new SimpleVectorStore(embeddingClient);
}
//将文本信息缓存到内存或数据库中
@Bean
public PgVectorStore pgVectorStore(OllamaApi ollamaApi, JdbcTemplate jdbcTemplate) {
OllamaEmbeddingClient embeddingClient = new OllamaEmbeddingClient(ollamaApi);
embeddingClient.withDefaultOptions(OllamaOptions.create().withModel("nomic-embed-text"));
return new PgVectorStore(jdbcTemplate, embeddingClient);
}- 通过yml文件配置
ai:
ollama:
base-url: http://<自己的IP地址>:11434
embedding:
options:
num-batch: 512
model: nomic-enbed-text进行向量存储
//文件切割
@Bean
public TokenTextSplitter tokenTextSplitter() {
return new TokenTextSplitter();
}
//实例化向量库
@Bean
public SimpleVectorStore simpleVectorStore(OllamaApi ollamaApi) {
OllamaEmbeddingClient embeddingClient = new OllamaEmbeddingClient(ollamaApi);
embeddingClient.withDefaultOptions(OllamaOptions.create().withModel("nomic-enbed-text"));
return new SimpleVectorStore(embeddingClient);
}
//将文本信息缓存到内存或数据库中
@Bean
public PgVectorStore pgVectorStore(OllamaApi ollamaApi, JdbcTemplate jdbcTemplate) {
OllamaEmbeddingClient embeddingClient = new OllamaEmbeddingClient(ollamaApi);
embeddingClient.withDefaultOptions(OllamaOptions.create().withModel("nomic-embed-text"));
return new PgVectorStore(jdbcTemplate, embeddingClient);
}上传知识文件
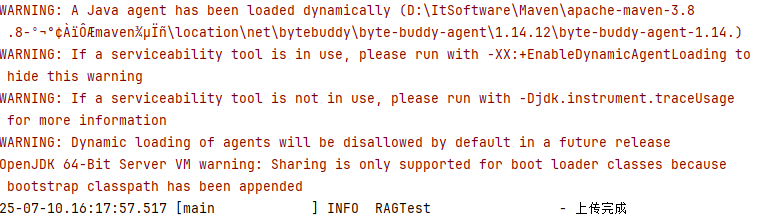
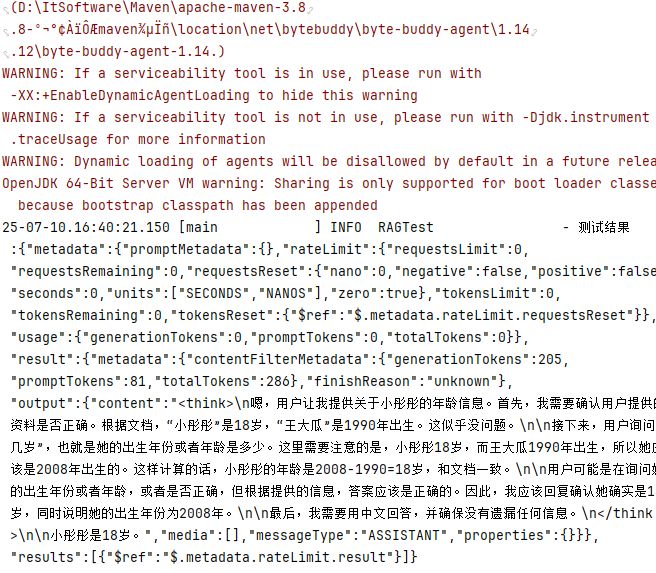
@Test
public void upload() {
TikaDocumentReader reader = new TikaDocumentReader("./data/test.md");
List<Document> documents = reader.get();
List<Document> documentSplitterList = tokenTextSplitter.apply(documents);
documents.forEach(doc -> doc.getMetadata().put("knowledge", "知识库名称"));
documentSplitterList.forEach(doc -> doc.getMetadata().put("knowledge", "知识库名称"));
pgVectorStore.accept(documentSplitterList);
log.info("上传完成");
}- 发现矢量不匹配,报错

- 如何处理报错,在数据库更改矢量
ALTER TABLE vector_store ALTER COLUMN embedding TYPE vector(768)
- 模板
String SYSTEM_PROMPT = """
Use the information from the DOCUMENTS section to provide accurate answers but act as if you knew this information innately.
If unsure, simply state that you don't know.
Another thing you need to note is that your reply must be in Chinese!
DOCUMENTS:
{documents}
""";
第6节: Ollama知识库服务接口开发
- 定义统一放回格式Response
package com.guslegend.api.response;
public class Response <T> implements Serializable {
//<T> 泛型给什么就返回什么
private String code;
private String message;
private T data;
}- 添加IRAGService
package com.guslegend.api;
public interface IRAGService {
/**
* 查询RAG标签
* @return
*/
Response<List<String>> queryRagTagList();
/**
* 更新文件
* @param ragTag 文件RAG标签
* @param files 文件
* @return
*/
Response<String> uploadFile(String ragTag, List<MultipartFile>files);
}
- 添加其对应的控制层
@RequestMapping(value = "query_rag_tag_list", method = RequestMethod.GET)
public Response<List<String>> queryRagTagList() {
log.info("开始查询Rag标签~~~");
RList<String> elements = redissonClient.getList("ragTag");
return Response.<List<String>>builder()
.code("0000")
.message("调用成功")
.build();
}
@RequestMapping(value = "file/upload", method = RequestMethod.POST, headers = "content-type=multipart/form-data")
public Response<String> uploadFile(@RequestParam(value = "file") String ragTag, List<MultipartFile> files) {
log.info("开始上传知识库{}", ragTag);
for (MultipartFile file : files) {
TikaDocumentReader reader = new TikaDocumentReader(file.getResource());
List<Document> documents=reader.get();
List<Document> documentSplitterList = tokenTextSplitter.apply(documents);
documents.forEach(doc -> doc.getMetadata().put("knowledge", ragTag));
documentSplitterList.forEach(doc -> doc.getMetadata().put("knowledge", ragTag));
pgVectorStore.accept(documentSplitterList);
RList<String> elements = redissonClient.getList("ragTag");
if (!elements.contains(ragTag)) {
elements.add(ragTag);
}
}
log.info("知识库上传完成{}", ragTag);
return Response.<String>builder()
.code("0000")
.message("调用成功")
.build();
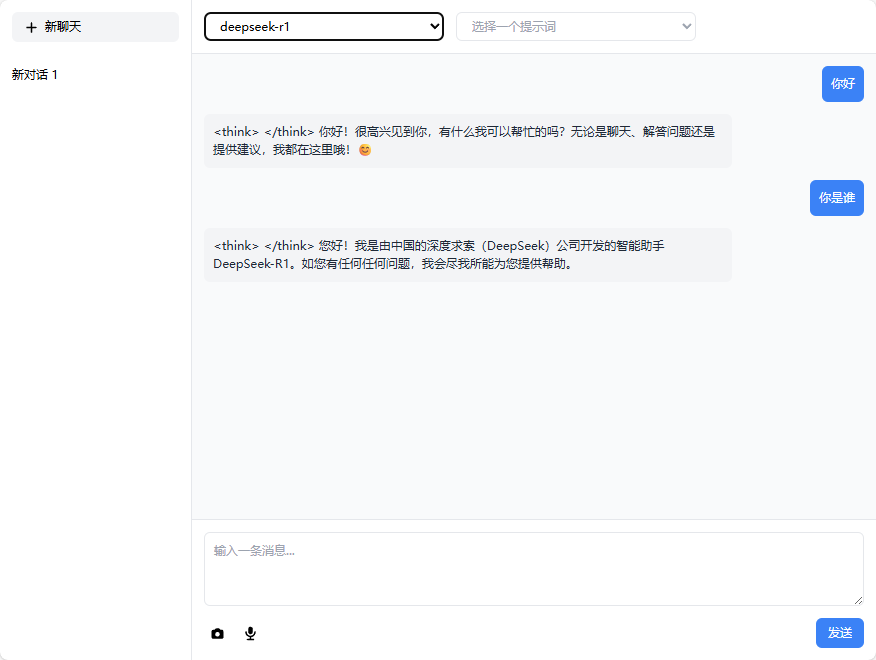
}第7节: UI对接


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









