




 本文档详细介绍了在CentOS7上安装Hadoop 3.2.0伪分布式集群的步骤,包括下载安装包、配置环境变量、修改配置文件、格式化HDFS、启动和验证服务,以及停止集群的整个流程。特别强调了JDK和Linux环境的预安装,主机名的修改,以及重要配置文件如core-site.xml、hdfs-site.xml等的修改细节。
本文档详细介绍了在CentOS7上安装Hadoop 3.2.0伪分布式集群的步骤,包括下载安装包、配置环境变量、修改配置文件、格式化HDFS、启动和验证服务,以及停止集群的整个流程。特别强调了JDK和Linux环境的预安装,主机名的修改,以及重要配置文件如core-site.xml、hdfs-site.xml等的修改细节。
部署
- 下载安装包
- 上传并解压安装包
- 配置环境变量
- 修改配置文件
- 格式化 HDFS
- 修改脚本文件
- 启动并验证
- 停止集群
注意:
1、默认已安装并配置完成JDK环境
2、默认已安装并配置完成 CentOS7 Linux 环境
3、将当前主机名修改为 bigdata01
4、伪分布式集群一般在学习阶段使用
下载安装包
-
下载地址
https://hadoop.apache.org/ -
点击 “download” 按钮
 - 显示最新的版本,如果要下载早期版本点击如下连接
- 显示最新的版本,如果要下载早期版本点击如下连接
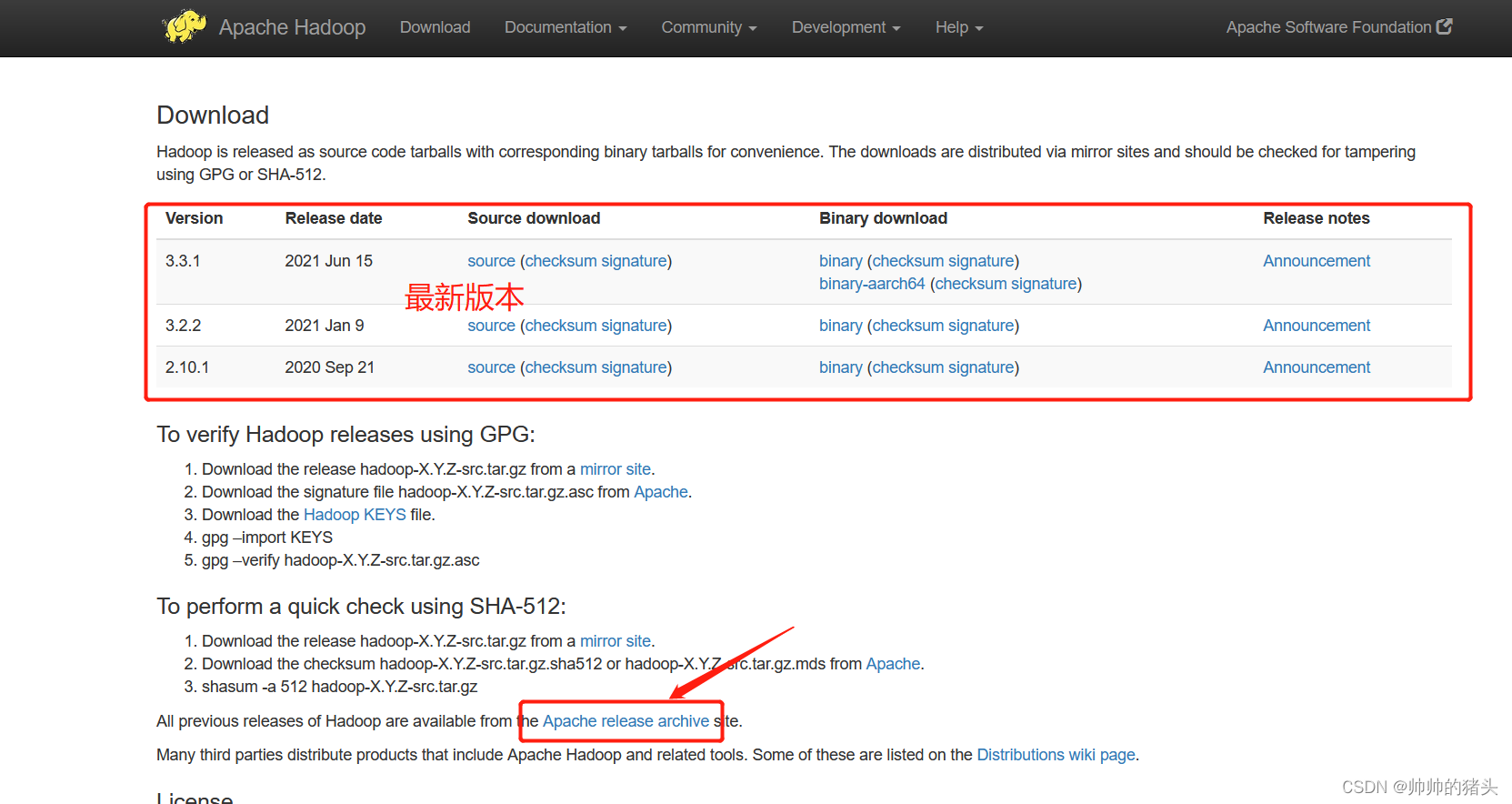 - 本教程已3.2.0版本为例
- 本教程已3.2.0版本为例
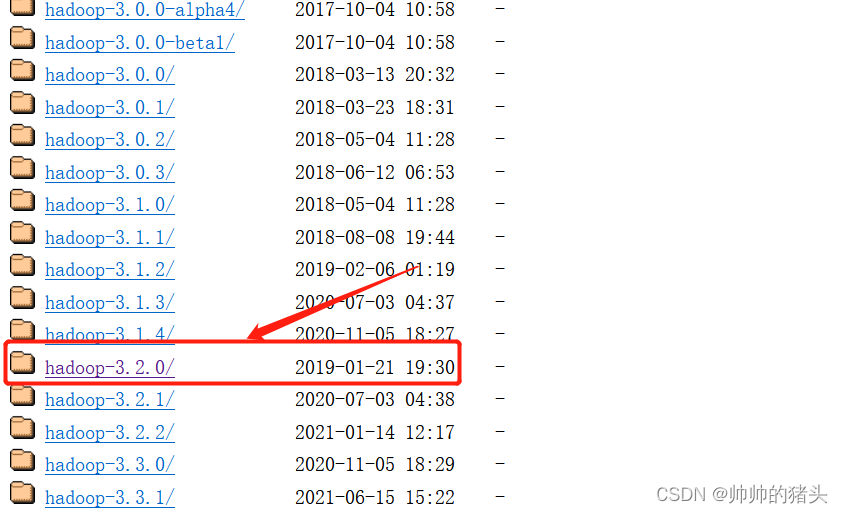 - 点击下载安装包
- 点击下载安装包
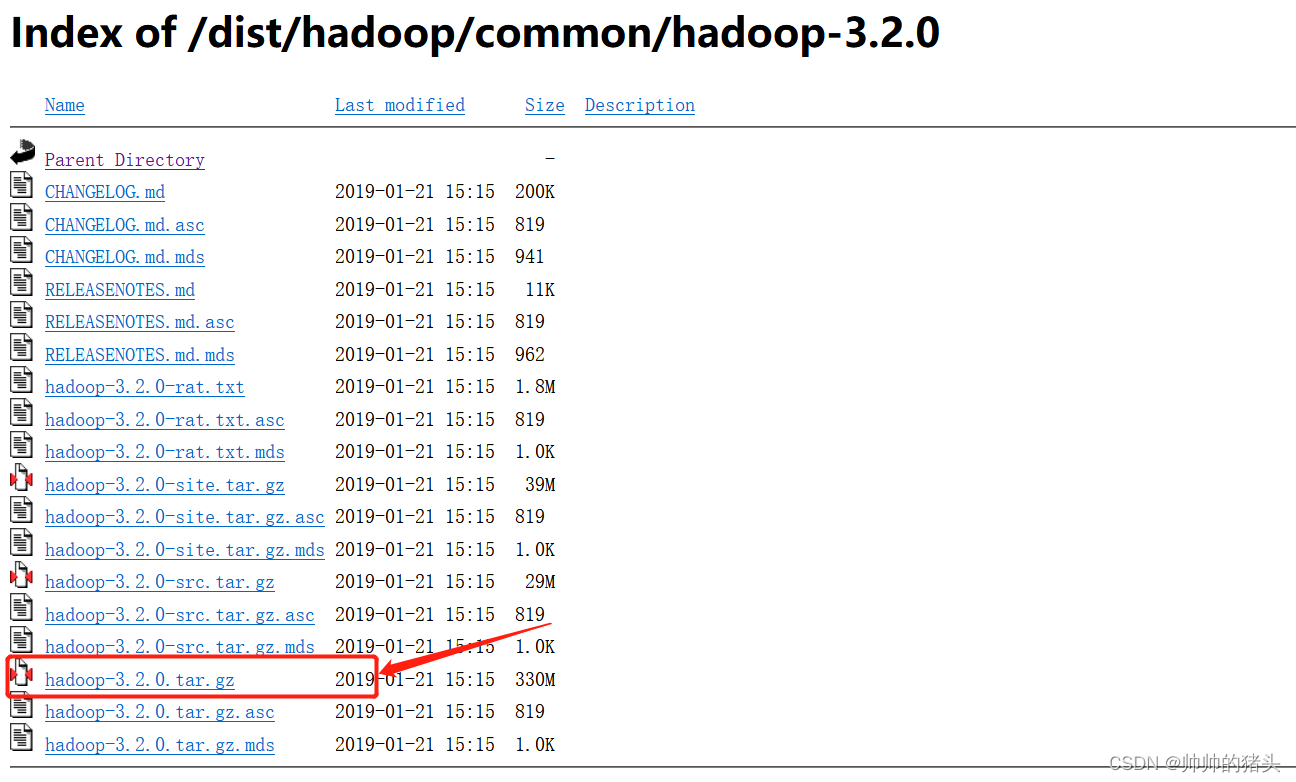
上传并解压安装包
- xshell 通过 ssh 连接到 CentOS7 服务器,创建 soft 目录
# 创建目录
mkdir soft
- 上传安装包
# 上传文件
rz -y
- 解压安装包至指定目录下
# -C 指定解压位置
tar -zxvf hadoop-3.2.0.tar.gz -C /usr/local
- 进入 hadoop3.2 目录并查看目录下内容
# 进入 hadoop目录
cd /usr/local/hadoop-3.2.0
# 查看目录下内容
ll
- 重要目录介绍
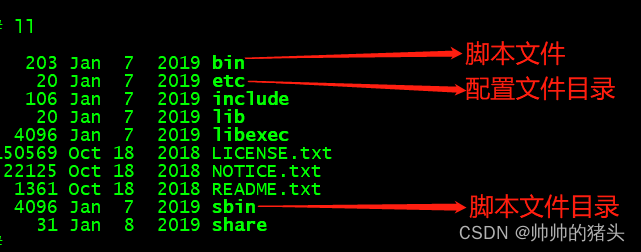
配置环境变量
- 打开配置文件
# 全局配置文件
vi /etc/profile
- 在配置文件最后增加如下内容
export HADOOP_HOME=/usr/local/hadoop-3.2.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- 生效配置文件
source /etc/profile
修改配置文件
- 进入配置文件目录
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 6604
6604

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











