



 当使用python-pyhdfs在HDFS上进行读写操作时,由于节点间通信需求,仅提供单个节点IP会导致读取失败。解决办法是在客户端配置所有节点的映射关系,确保跨节点操作的顺利进行。
当使用python-pyhdfs在HDFS上进行读写操作时,由于节点间通信需求,仅提供单个节点IP会导致读取失败。解决办法是在客户端配置所有节点的映射关系,确保跨节点操作的顺利进行。
一、问题描述
raise ConnectionError(e, request=request)
ConnectionError: HTTPConnectionPool(host='a', port=50075): Max retries exceeded with url: /webhdfs/v1/logs/pv?op=OPEN&user.name=root&namenoderpcaddress=hdfscluster&offset=0 (Caused by
NewConnectionError('<urllib3.connection.HTTPConnection object at 0x0000026A
D0C6BC50>: Failed to establish a new connection: [WinError 10060]
由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。',))
二、原因
from pyhdfs import HdfsClient
client = HdfsClient(hosts='192.168.126.128:50070',user_name='root')
response = client.open("/logs/pv")
print(response.readline())
在hdfs上读取或者写入文件时,节点之间需要通信,如果用客户端编写python代码读取数据时,读完a节点的块数据后,还会去读b节点的数据,这时当我们在连接时只写入了a节点的ip,并不知道b节点的ip,所以读取不成功报错。
二、解决办法
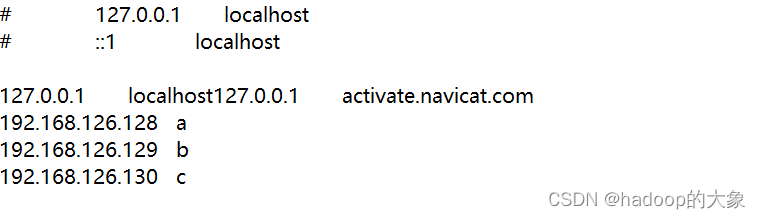
在客户端添加节点间的映射关系


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









