




 本文探讨了SVM算法如何从二分类问题推广至回归问题,介绍了核岭回归和Tube regression两种常见方法。核岭回归利用核技巧进行非线性空间线性回归,而Tube regression通过构造特殊的损失函数实现稀疏性。
本文探讨了SVM算法如何从二分类问题推广至回归问题,介绍了核岭回归和Tube regression两种常见方法。核岭回归利用核技巧进行非线性空间线性回归,而Tube regression通过构造特殊的损失函数实现稀疏性。
如前文SVM算法的正则化损失函数视角中提及的,SVM可以理解为“广义线性损失函数+L2正则化”在损失函数为Hinge Loss下特例。即
min
λ
N
w
2
+
1
N
∑
i
=
1
N
e
r
r
(
y
i
,
g
(
w
x
i
)
)
\min \frac{\lambda}{N} w^2+\frac{1}{N}\sum_{i=1}^Nerr(y_i,g(wx_i))
minNλw2+N1i=1∑Nerr(yi,g(wxi))式中
g
(
w
x
)
g(wx)
g(wx)为线性函数。
本质上,SVM算法是基于二分类的最大软间隔分类算法,那如何将其推广到回归问题中呢?
有如下两种常见思路,其原则都是修改上述损失函数,使其适用于回归问题。
一、核岭回归(kernel ridge regression)
在线性回归(一)基础理论曾介绍过岭回归(即L2正则化的线性回归):
min
λ
N
w
2
+
1
N
∑
i
=
1
N
(
y
i
−
w
x
i
)
2
\min \frac{\lambda}{N} w^2+\frac{1}{N}\sum_{i=1}^N(y_i-wx_i)^2
minNλw2+N1i=1∑N(yi−wxi)2又考虑到对于这种“广义线性损失函数+L2正则化”,线性参数
w
w
w可以写成样本特征向量线性组合的形式,即:
w
∗
=
∑
j
=
1
N
β
j
x
j
w^*=\sum_{j=1}^N\beta_jx_j
w∗=j=1∑Nβjxj将其代入岭回归目标函数,同时引入核技巧,可得
min
β
λ
N
∑
i
=
1
N
∑
j
=
1
N
β
i
β
j
K
(
x
i
,
x
j
)
+
1
N
∑
i
=
1
N
(
y
i
−
∑
j
=
1
N
β
j
K
(
x
i
,
x
j
)
)
2
\min_\beta\frac{\lambda}{N} \sum_{i=1}^N \sum_{j=1}^N\beta_i\beta_jK(x_i,x_j)+\frac{1}{N}\sum^{N}_{i=1}(y_i-\sum_{j=1}^N\beta_jK(x_i,x_j))^2
βminNλi=1∑Nj=1∑NβiβjK(xi,xj)+N1i=1∑N(yi−j=1∑NβjK(xi,xj))2写成向量形式,为:
min
β
λ
N
β
T
K
β
+
1
N
(
β
T
K
T
K
β
−
2
β
T
K
T
y
+
y
T
y
)
\min_{\boldsymbol \beta}\frac{\lambda}{N}\boldsymbol {\beta^TK\beta}+\frac{1}{N}(\boldsymbol{\beta^TK^TK\beta}-2\boldsymbol{\beta^TK^Ty+\boldsymbol{y^Ty}})
βminNλβTKβ+N1(βTKTKβ−2βTKTy+yTy)上式对
β
\boldsymbol \beta
β求导,令其等于0,则可得极值点:
∇
β
=
λ
N
2
K
T
β
+
1
N
(
2
K
T
K
β
−
2
K
T
y
)
=
2
N
K
T
(
(
λ
I
+
K
)
β
−
y
)
=
0
\begin{aligned}\nabla_{\boldsymbol \beta}&=\frac{\lambda}{N}\boldsymbol{2K^T\beta}+\frac{1}{N}(2\boldsymbol{K^TK\beta}-2\boldsymbol{K^Ty})\\&=\frac{2}{N}\boldsymbol{K^T}((\boldsymbol{\lambda I+K})\boldsymbol{\beta}-\boldsymbol{y}\boldsymbol{})\\&=0\end{aligned}
∇β=Nλ2KTβ+N1(2KTKβ−2KTy)=N2KT((λI+K)β−y)=0因为核函数矩阵
K
\boldsymbol{K}
K为半正定阵(因为
K
i
j
=
ϕ
(
x
i
)
∗
ϕ
(
y
i
)
K_{ij}=\phi(x_i)*\phi(y_i)
Kij=ϕ(xi)∗ϕ(yi)),而
λ
<
0
\lambda<0
λ<0,因此
λ
I
+
K
\boldsymbol{\lambda I+K}
λI+K必为正定阵,即可逆。所以
β
\boldsymbol {\beta}
β存在解析的最优解:
β
∗
=
(
λ
I
+
K
)
−
1
y
\boldsymbol {\beta}^*=(\boldsymbol{\lambda I+K})^{-1}\boldsymbol{y}
β∗=(λI+K)−1y本质上,核岭回归就是通过核技巧,将原始特征映射到高维非线性空间,再进行线性回归的过程。
从数学表达上,核岭回归通过将软间隔SVM目标函数的损失函数改写为MSE,因此也叫做最小回归SVM(least-squares SVM, 简称LSSVM).
采用LSSVM的一种缺点在于其目标参数
β
\beta
β的密集性。因为MSE对所有的预测值(只要预测值不等于真实值)都进行残差平方级的惩罚。所以,近乎所有的样本点都可视为支持向量,那么拉格朗日乘子
β
\beta
β即非0。所以其计算量很大,而在标准的SVM算法中,参数
α
\alpha
α是具备稀疏性的(即支持向量点占少数)。
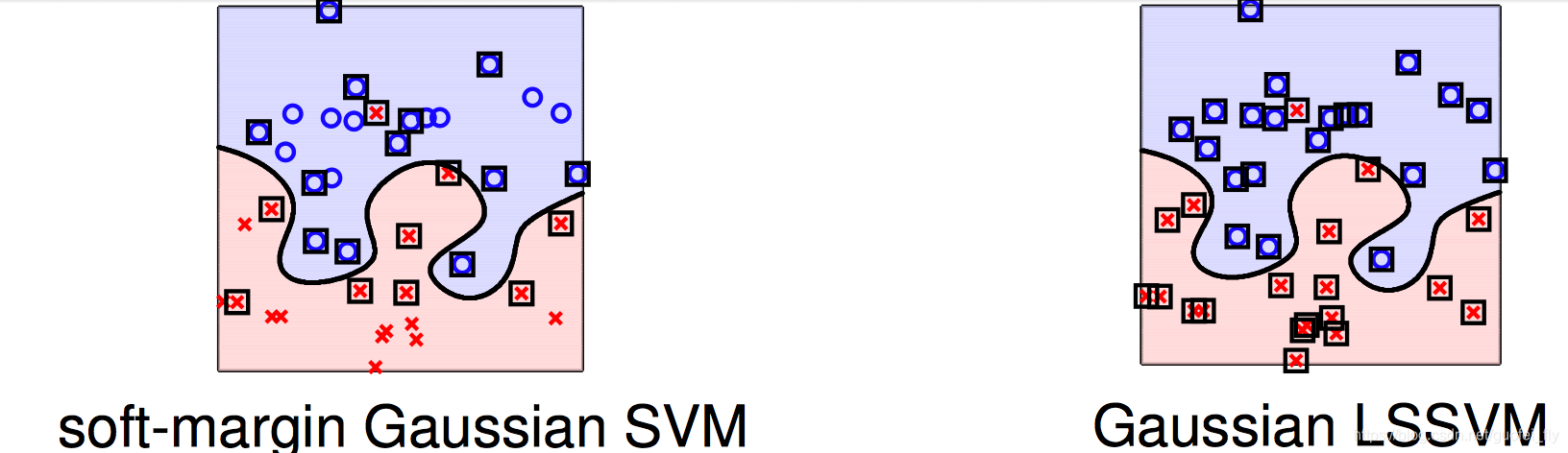
那么,有没有方法能够在进行做到像LSSVM一样解决回归问题,同时参数有具有稀疏性呢?答案同样是修改合适的损失函数。
二、Tube regression
从“广义线性损失函数+L2正则化”的视角来观察标准的SVM目标函数: min λ N w 2 + 1 N ∑ i = 1 N max ( 0 , 1 − y i ( w x i + b ) ) \min \frac{\lambda}{N} w^2+\frac{1}{N}\sum_{i=1}^N\max(0,1-y_i(wx_i+b)) minNλw2+N1i=1∑Nmax(0,1−yi(wxi+b))通过构造Hinge损失函数,通过仅对 y i ( w x i + b ) ≤ 1 y_i(wx_i+b)\le1 yi(wxi+b)≤1的样本点(即既非支持向量点,又非正确分类且间隔足够大的的那些点)进行惩罚。这是参数 α \alpha α具有稀疏性的本质原因。
因此,可以在回归问题中,也构造具备类似性质的损失函数来取得类似的效果。定义tube损失函数:
e
r
r
(
y
,
y
^
)
=
max
(
0
,
∣
y
−
y
^
∣
−
ϵ
)
,
ϵ
>
0
err(y,\hat y)=\max(0,|y-\hat y|-\epsilon), \epsilon>0
err(y,y^)=max(0,∣y−y^∣−ϵ),ϵ>0其中超参数
ϵ
\epsilon
ϵ可理解为对预测值偏差的容忍程度,在
ϵ
\epsilon
ϵ范围内可以不对误差值进行惩罚。当
ϵ
=
0
\epsilon=0
ϵ=0时,tube损失退化为MSE损失。从间隔的角度来看,tube损失相当于设置了一个单边宽度为
ϵ
\epsilon
ϵ的margin,margin外的误差才进行惩罚。
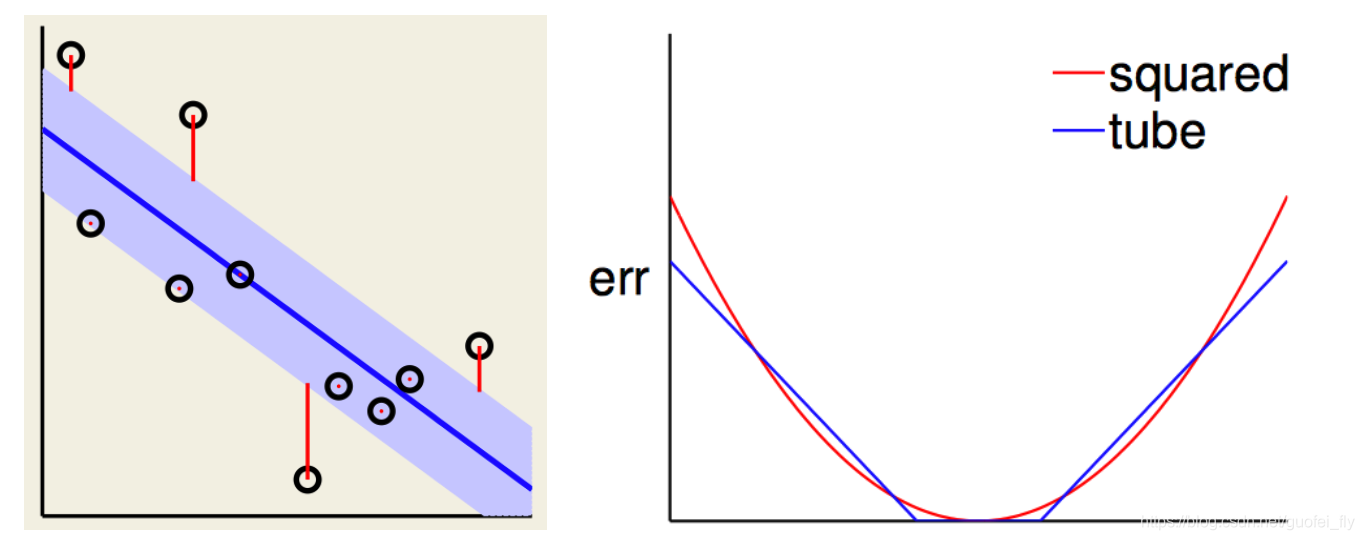
因此,在tube损失下的回归问题目标函数可写为:
min
λ
N
w
2
+
1
N
∑
i
=
1
N
max
(
0
,
∣
y
−
(
w
x
+
b
)
∣
−
ϵ
)
\min \frac{\lambda}{N} w^2+\frac{1}{N}\sum_{i=1}^N\max(0,|y-(wx+b)|-\epsilon)
minNλw2+N1i=1∑Nmax(0,∣y−(wx+b)∣−ϵ)虽然表达为“广义线性损失函数+L2正则化”的形式,优化目标无约束,但其不可微,并不方便求解。仿照在标准SVM问题中,“广义线性损失函数+L2正则化”与广义拉格朗日对偶问题的相互转化,可以尝试将其变为更易求解的二次规划问题。
注意到与标准SVM中惩罚项
1
−
y
(
w
x
+
b
)
1-y(wx+b)
1−y(wx+b)不一样,这里的损失函数存在绝对值,因此需要同时对
y
−
(
w
x
+
b
)
y-(wx+b)
y−(wx+b)设置上界约束条件和下界约束函数,即写成:
min
w
,
b
,
ϵ
−
,
ϵ
+
1
2
w
2
+
C
∑
i
=
1
N
(
ϵ
i
+
+
ϵ
i
−
)
s
.
t
.
−
ϵ
−
ϵ
+
≤
y
i
−
w
x
i
−
b
≤
ϵ
+
ϵ
+
ϵ
+
≥
0
,
ϵ
−
≥
0
\begin{aligned}\min_{w,b,\epsilon^{-},\epsilon^{+}}&\frac{1}{2}w^2+C\sum_{i=1}^N(\epsilon^{+}_i+\epsilon^{-}_i)\\s.t.\quad &-\epsilon-\epsilon^{+}\le y_i-wx_i-b\le\epsilon+\epsilon^{+}\\ & \epsilon^{+}\ge 0, \epsilon^{-}\ge 0\end{aligned}
w,b,ϵ−,ϵ+mins.t.21w2+Ci=1∑N(ϵi++ϵi−)−ϵ−ϵ+≤yi−wxi−b≤ϵ+ϵ+ϵ+≥0,ϵ−≥0上式中,
ϵ
\epsilon
ϵ为预设的超参数,而
ϵ
+
,
ϵ
−
\epsilon^{+},\epsilon^{-}
ϵ+,ϵ−分别为在
ϵ
\epsilon
ϵ基础上对上界约束和下界约束的进一步松弛。当然也能将两者合并进行统一表达。
类比于标准SVM中,将其表述为拉格朗日函数的极大极小问题,进而转化为对偶问题。通过求解拉格朗日乘子的二次规划问题,以及对偶补充条件,可以求得所有的参数,从而得到回归问题的解。

















 7235
7235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









