






 本文介绍了Storm的基本原理,包括集群结构中的Nimbus、Supervisor和Zookeeper的角色,以及与Hadoop的区别。详细讲解了Stream、Spout和Bolt的概念,阐述了Topology的构成。此外,还探讨了Storm的数据模型,强调了Tuple在数据处理中的重要性。
本文介绍了Storm的基本原理,包括集群结构中的Nimbus、Supervisor和Zookeeper的角色,以及与Hadoop的区别。详细讲解了Stream、Spout和Bolt的概念,阐述了Topology的构成。此外,还探讨了Storm的数据模型,强调了Tuple在数据处理中的重要性。
介绍Storm基本原理
1 集群结构

Storm集群采用主从架构方式,主节点是Nimbus,从节点是Supervisor,有关调度相关的信息存储到ZooKeeper集群中
* Nimbus
主控节点,用于提交任务、分配集群任务,集群监控等
* zookeeper
集群中协调、共有数据的存放(如心跳信息、集群的状态和配置信息),Nimbus将分配给Supervisro的任务写进Zookeeper。
* Supervisor
负责接受Nimbus分配的任务,管理属于自己的Worker进程。
Nimbus和Supervisor之间的所有协调工作都是通过一个Zookeeper集群来完成。并且,nimbus进程和supervisor都是快 速失败(fail-fast)和无状态的。所有的状态要么在Zookeeper里面, 要么在本地磁盘上。这也就意味着你可以用kill -9来杀死nimbus和supervisor进程, 然后再重启它们,它们可以继续工作, 就好像什么都没有发生过似的。这个设计使得storm不可思议的稳定。
* storm VS hadoop
storm集群和hadoop集群很像,但是hadoop运行MapReduce的Job,而storm运行Topology。
关键区别:一个MapReduce Job最终会结束, 而一个Topology运永远运行(除非你显式的杀掉他)。
在Storm的集群里面有两种节点: 控制节点(master node)和工作节点(worker node)。
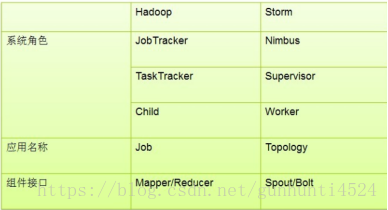
master node:-->后台程序:Nimbus,类似Hadoop中的JobTracker。
worker node:--> 运行Supervisor的节点(类似 TaskTracker)。每一个工作进程执行一个Topology(类似 Job)的一个子集;一个运行的Topology由运行在很多机器上的很多工作进程 Worker(类似 Child)组成。
* storm topology结构
2 stream
在Storm中有对于流stream的抽象,流是一个不间断的无界的连续tuple,注意Storm在建模事件流时,把流中的事件抽象为tuple即元组。
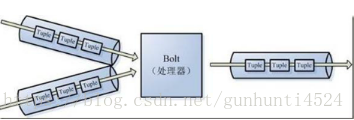
Storm认为每个stream都有一个源,也就是原始元组的源头,叫做Spout(管口)
处理stream内的tuple,抽象为Bolt,bolt可以消费任意数量的输入流,只要将流方向导向该bolt,同时它也可以发送新的流给其他bolt使用,这样一来,只要打开特定的spout再将spout中流出的tuple导向特定的bolt,又bolt对导入的流做处理后再导向其他bolt或者目的地。
可以认为spout就是水龙头,并且每个水龙头里流出的水是不同的,我们想拿到哪种水就拧开哪个水龙头,然后使用管道将水龙头的水导向到一个水处理器(bolt),水处理器处理后再使用管道导向另一个处理器或者存入容器中。

为了增大水处理效率,我们很自然就想到在同个水源处接上多个水龙头并使用多个水处理器,这样就可以提高效率。
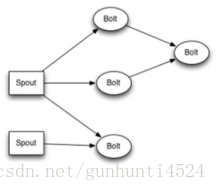
有向无环图 -->抽象为-->Topology(拓扑) -->storm的Job的抽象概念
图中每个节点是一个spout或者bolt,每个spout或者bolt发送元组到下一级组件,广播方式。
3 Topology
storm:
流中的元素抽象为tuple,一个tuple --> 一个值列表value list
每个value有一个name,每个value可序列化
拓扑的每个节点都要说明它所发射出的元组的字段的name,其他节点只需要订阅该name就可以接收处理。
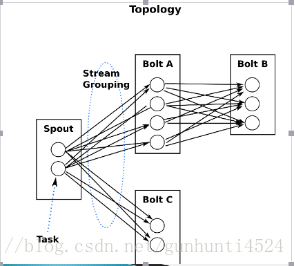
一个Storm在集群上运行一个Topology时,主要通过以下3个实体来完成Topology的执行工作:
(1). Worker(进程)
(2). Executor(线程)
(3). Task
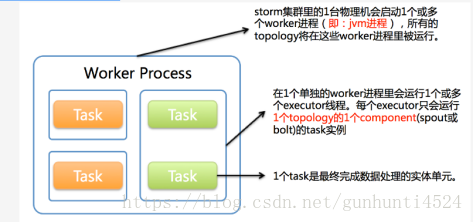
4 角色概念
Streams:消息流
消息流是一个没有边界的tuple序列。
这些tuples会被以一种分布式的方式并行创建和处理。 每个tuple可以包含多列,字段类型可以是: integer, long, short, byte, string, double, float, boolean和byte array。 你还可以自定义类型 — 只要你实现对应的序列化器。
* Spouts:消息源
Spouts是topology消息生产者。
Spout从一个外部源(消息队列)读取数据向topology发出tuple。 消息源Spouts可以是可靠的也可以是不可靠的。一个可靠的消息源可以重新发射一个处理失败的tuple, 一个不可靠的消息源Spouts不会。

* Bolts:消息处理者
消息处理逻辑被封装在bolts里面,Bolts可以做很多事情: 过滤, 聚合, 查询数据库等。
流程是: Bolts处理一个输入tuple, 然后调用ack通知storm自己已经处理过这个tuple了。storm提供了一个IBasicBolt会自动调用ack。
Bolts使用OutputCollector来发射tuple到下一级Blot。
5 数据模型
storm使用tuple来作为它的数据模型。每个tuple是一堆值,每个值有一个名字,并且每个值可以是任何类型,总体来看,storm支持所有的基本类型、字符串以及字节数组作为tuple的值类型。也可以自定义类型, 只要实现序列化器(serializer)。
一个Tuple代表数据流中的一个基本的处理单元,例如一条cookie日志,它可以包含多个Field,每个Field表示一个属性。
![]()
Tuple本来应该是一个Key-Value的Map,由于各个组件间传递的tuple的字段名称已经事先定义好了,所以Tuple只需要按序填入各个Value,所以就是一个Value List。
一个没有边界的、源源不断的、连续的Tuple序列就组成了Stream。

















 823
823

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









