




 本文介绍了Python中的命令行参数处理、文件路径操作、数据结构应用,以及格式化输出技巧,包括固定宽度、对齐方式、数字格式和进度条的使用。
本文介绍了Python中的命令行参数处理、文件路径操作、数据结构应用,以及格式化输出技巧,包括固定宽度、对齐方式、数字格式和进度条的使用。
文章目录
前言
Python语言简单,也有很多实用小技巧或者经验,以下慢慢总结汇总。
具体代码可以去我的GitHub下载。
1. 命令行参数
import sys
def command_line_parameters():
print("命令行参数个数: ", len(sys.argv))
print("命令行参数列表: ", sys.argv)
for i in range(len(sys.argv)):
print("第 ", i, " 个参数是 : ", sys.argv[i])

2. 命令行参数 2.0
import os
import argparse
import sys
def command_parser():
parser = argparse.ArgumentParser()
parser.add_argument('--input', '-i', type=str, required=True, help='given file for read')
parser.add_argument('--format', '-f', type=float, required=False, help='deal data format')
parser.add_argument('--output', '-o', type=str, required=True, help='output result to file')
return parser.parse_args()
if __name__ == "__main__":
args = command_parser()
print(args.input, args.output)
if args.format is not None :
print(args.format)
-
运行命令 :python3 demo.py -i input.txt -f 2.5 -o out.txt
input.txt out.txt
2.5 -
运行命令 :python3 demo.py -i input.txt -o out.txt
input.txt out.txt
3. 路径以及文件操作
import os
import sys
def path():
# 1) 改变当前工作目录到指定的路径
# os.chdir() # 方法用于改变当前工作目录到指定的路径
# os.chdir("E:/computer/Pycharm/ExperiencesKills")
# os.chdir("../") # 到当前目录的上一级目录
# 2) 获取当前文件的绝对路径
abspath = os.path.abspath(__file__) # 获取当前文件的绝对路径
print(abspath)
# 3) 获取指定的文件夹包含的文件或文件夹的名字的列表
# os.listdir() # 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表
listdirs = os.listdir()
print(listdirs)
# 4) 获取当前文件夹的上一层目录
# os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # 表示获取当前文件夹上一层目录
print(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
# 5) 创建文件夹
fold = "guihun"
folder = os.path.exists(fold) # 判断是否存在文件夹如果不存在则创建为文件夹
if not folder:
os.makedirs("fold")
# 6) 判断路径 path 是否存在
# os.path.exists(path) # 如果路径 path 存在,返回 True; 如果路径 path 不存在,返回 False
path = listdirs[1]
if os.path.exists(path):
print(path, "文件存在")
else:
print(path, "文件不存在")
# 7) 创建名字为 fileName 的txt文件
file_name = "memo"
file = open(file_name + '.txt', 'w')
file.close()

4. 循环获取指定文件夹下的指定类型文件
import os
import sys
def read_allFiles(path):
# 获取指定文件夹 path 下的所有文件
path_files = []
files = os.listdir(path) # 得到文件夹下的所有文件名称
for file in files:
if not os.path.isdir(file):
file_name = os.path.join(path, file)
path_files.append(file_name)
return path_files
def read_all_specified_type_files(path, type):
# 获取指定文件夹 path 下的所有 type 类型文件
specified_files = []
path_files = read_allFiles(path)
for file in path_files:
file_name = os.path.basename(file) # 获取文件名
if file_name.find(type) != -1:
specified_files.append(file) # 将文本文件提取出来
return specified_files
def test_of_read_allFiles():
route = "data"
folder = os.path.exists(route) # 判断是否存在文件夹如果不存在则创建为文件夹
if not folder:
os.makedirs(route)
all_files = read_allFiles(route)
print(all_files)
txt_files = read_all_specified_type_files(route, ".txt")
if txt_files:
f = open(txt_files[0], 'r') # 打开文本文件
print(f.read()) # 读取文本文件内容
f.close()

5. Python 中常用的数据结构整理
import os
import re
import argparse
import random
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import xlrd
import xlwt
import xlsxwriter
import sys
def command_parser():
parser = argparse.ArgumentParser()
parser.add_argument('--input', '-i', type=str, required=True, help='input')
parser.add_argument('--output', '-o', type=str, required=True, help='output')
return parser.parse_args()
def learn_set():
# 集合 set
# 集合(set)是一个无序的不重复元素序列。
# 可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
basket = {'apple', 'orange', 'pear', 'banana'}
a = set('abracadabra')
thisset = set(("Google", "Runoob", "Taobao"))
thisset.add("Facebook") #为集合添加元素
thisset.remove("Taobao") #该方法不同于 discard() 方法,因为 remove() 方法在移除一个不存在的元素时会发生错误,而 discard() 方法不会。
thisset.discard("Taobao")
size = len(thisset)
thisset.clear() #移除集合中的所有元素
s = "Runoob"
if s not in thisset:
print(s, "is not in thisset")
x = {"apple", "banana", "cherry"}
y = {"google", "microsoft", "apple"}
z = x.difference(y) # 用于返回集合的差集,即返回的集合元素包含在第一个集合中,但不包含在第二个集合(方法的参数)中
# z = {'cherry', 'banana'}
z = x.intersection(y) # 用于返回两个或更多集合中都包含的元素,即交集
# z = {'apple'}
x.intersection_update(y) # 用于获取两个或更多集合中都重叠的元素,即计算交集. intersection_update() 方法不同于 intersection() 方法,因为 intersection() 方法是返回一个新的集合,而 intersection_update() 方法是在原始的集合上移除不重叠的元素。
z = x.union(y) # 返回两个集合的并集,即包含了所有集合的元素,重复的元素只会出现一次。
x.update(y) # 用于修改当前集合,可以添加新的元素或集合到当前集合中,如果添加的元素在集合中已存在,则该元素只会出现一次,重复的会忽略。
#集合推导式
#{ expression for item in Sequence }
#或
#{ expression for item in Sequence if conditional }
setnew = {i**2 for i in (1,2,3,4,5)} # 计算数字 1,2,3 的平方数
a = {x for x in 'hello every one' if x not in 'abc'} # 判断不是 abc 的字母并输出
def learn_string():
# 字符串可以使用引号(' 或 " )来创建字符串。
var1 = 'Hello World!'
var2 = "Runoob"
if "M" not in var1 :
print("M 不在变量 a 中")
# find(str, beg=0, end=len(string)) 检测 str 是否包含在字符串中,如果指定范围 beg 和 end ,则检查是否包含在指定范围内,如果包含返回开始的索引值,否则返回-1
str1 = "Runoob example....wow!!!"
str2 = "exam"
print(str1.find(str2)) # 7
# count() 方法用于统计字符串里某个字符出现的次数。可选参数为在字符串搜索的开始与结束位置。
# str.count(sub, start= 0,end=len(string)) start 是字符串开始搜索的位置。默认为第一个字符,第一个字符索引值为0。
print (str1.count(str2,0,15)) # 1
# str.isdigit() # 检测字符串是否只由数字组成。
str = "123456";
print (str.isdigit()) # True
# len() 方法返回对象(字符、列表、元组等)长度或项目个数。
str = "runoob"
len(str) # 6
# rstrip() 删除 string 字符串末尾的指定字符,默认为空白符,包括空格、换行符、回车符、制表符。
txt = "banana,,,,,ssqqqww....."
x = txt.rstrip(",.qsw") # x = banana #移除逗号(,)、点号(.)、字母 s、q 或 w,这几个都是尾随字符
# strip([chars]) 在字符串上执行 lstrip()和 rstrip()
str = "code_1024"
s = str.strip('\n')
s = s.split()
s = s.split(' ')
s = s.strip().startswith('code')
def learn_list():
# 列表是最常用的 Python 数据类型,它可以作为一个方括号内的逗号分隔值出现
# 列表的数据项不需要具有相同的类型
# 创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可
list1 = ['Google', 'Runoob', 1997, 2000]
# list.append(obj) 在列表末尾添加新的对象
# list.count(obj) 统计某个元素在列表中出现的次数
# list.index(obj) 从列表中找出某个值第一个匹配项的索引位置
# list.pop([index=-1]) 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值
# list.reverse() 反向列表中元素
# list.sort( key=None, reverse=False) 对原列表进行排序
# list.copy() 复制列表
# 列表推导式
#[表达式 for 变量 in 列表]
#[out_exp_res for out_exp in input_list]
#或者
#[表达式 for 变量 in 列表 if 条件]
#[out_exp_res for out_exp in input_list if condition]
multiples = [i for i in range(30) if i % 2 == 0]
def learn_tuple():
# Python 的元组与列表类似,不同之处在于元组的元素不能修改
# 元组使用小括号(),列表使用方括号[]
# 元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可
tup1 = ('Google', 'Runoob', 1997, 2000)
def learn_map():
# 字典是另一种可变容器模型,且可存储任意类型对象。字典的每个键值 key = > value 对用冒号: 分割,每个对之间用逗号(,)分割,整个字典包括在花括号 {} 中, 格式如下所示:
# d = {key1: value1, key2: value2, key3: value3}
# 键必须是唯一的,但值则不必。值可以取任何数据类型,但键必须是不可变的,如字符串,数字。
tinydict = {'name': 'runoob', 'likes': 123, 'url': 'www.guihun.com'}
# 使用大括号 {} 来创建空字典
emptyDict = {}
print(type(emptyDict)) # <class 'dict'>
print(tinydict['name'])
tinydict['Age'] = 8
# del tinydict['Name'] # 删除键 'Name'
# tinydict.clear() # 清空字典
# del tinydict # 删除字典
print(str(tinydict)) # 输出字典,可以打印的字符串表示。
# dict.get(key, default=None) # 返回指定键的值,如果键不在字典中返回 default 设置的默认值
# key in dict # 如果键在字典dict里返回true,否则返回false
# dict.keys()、dict.values() 和 dict.items() # 返回的都是视图对象( view objects),提供了字典实体的动态视图,这就意味着字典改变,视图也会跟着变化。
# 视图对象不是列表,不支持索引,可以使用 list() 来转换为列表。
map_record = {1:"a", 2:"b", 3:"c"}
for key ,val in map_record.items():
print("key : ", key, "val : ", val)
#字典推导式
#{ key_expr: value_expr for value in collection }
#{ key_expr: value_expr for value in collection if condition }
dic = {x: x**2 for x in (2, 4, 6, 8)} #以数字为键,数字的平方为值来创建字典
# 字典转列表并以字典值升序排列
dataList = sorted(dataMap.items(), key=lambda d:d[1], reverse=False)
if __name__ == "__main__":
learn_set()
learn_string()
learn_list()
learn_tuple()
learn_map()

6. Python format 格式化输出
6.1 固定宽度
format()可以指定输出宽度为多少,当字符串长度少于设定值的时候,默认用空格填充。
if __name__ == "__main__":
data = [{'name': 'Tom', 'college': 'Tsinghua University'},
{'name': 'Micheal', 'college': 'Harvard University'},
{'name': 'Tony', 'college': 'Massachusetts Institute of Technology'}]
#固定宽度输出
for item in data:
print('{:10}{:40}'.format(item['name'], item['college']))

6.2 对齐方式
format()支持左对齐,右对齐,居中,分别对应<,>,^
if __name__ == "__main__":
data = [{'name': 'Tom', 'college': 'Tsinghua University'},
{'name': 'Micheal', 'college': 'Harvard University'},
{'name': 'Tony', 'college': 'Massachusetts Institute of Technology'}]
print('{:-^50}'.format('居中'))
for item in data:
print('{:^10}{:^40}'.format(item['name'], item['college']))
print('{:-^50}'.format('左对齐'))
for item in data:
print('{:<10}{:<40}'.format(item['name'], item['college']))
print('{:-^50}'.format('右对齐'))
for item in data:
print('{:>10}{:>40}'.format(item['name'], item['college']))

6.3 数字格式化
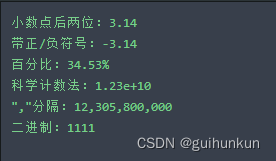
if __name__ == "__main__":
# 取小数点后两位
num = 3.1415926
print('小数点后两位:{:.2f}'.format(num))
# 带+/-输出
num = -3.1415926
print('带正/负符号:{:+.2f}'.format(num))
# 转为百分比
num = 0.34534
print('百分比:{:.2%}'.format(num))
# 科学计数法
num = 12305800000
print('科学计数法:{:.2e}'.format(num))
# ,分隔
num = 12305800000
print('","分隔:{:,}'.format(num))
# 转为二进制
num = 15
print('二进制:{:b}'.format(num))
6.4 进度条
import time
if __name__ == "__main__":
length = 1000
for i in range(1, length + 1):
percent = i / length
bar = '*' * int(i // (length / 50))
time.sleep(0.01)
print('\r进度条:|{:<50}|{:>7.1%}'.format(bar, percent), end='')
print('\n')

















 1753
1753

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









