




一台服务器在运行使用中失联,通过BMC远程kvm查看界面卡死,屏幕显示如下信息:
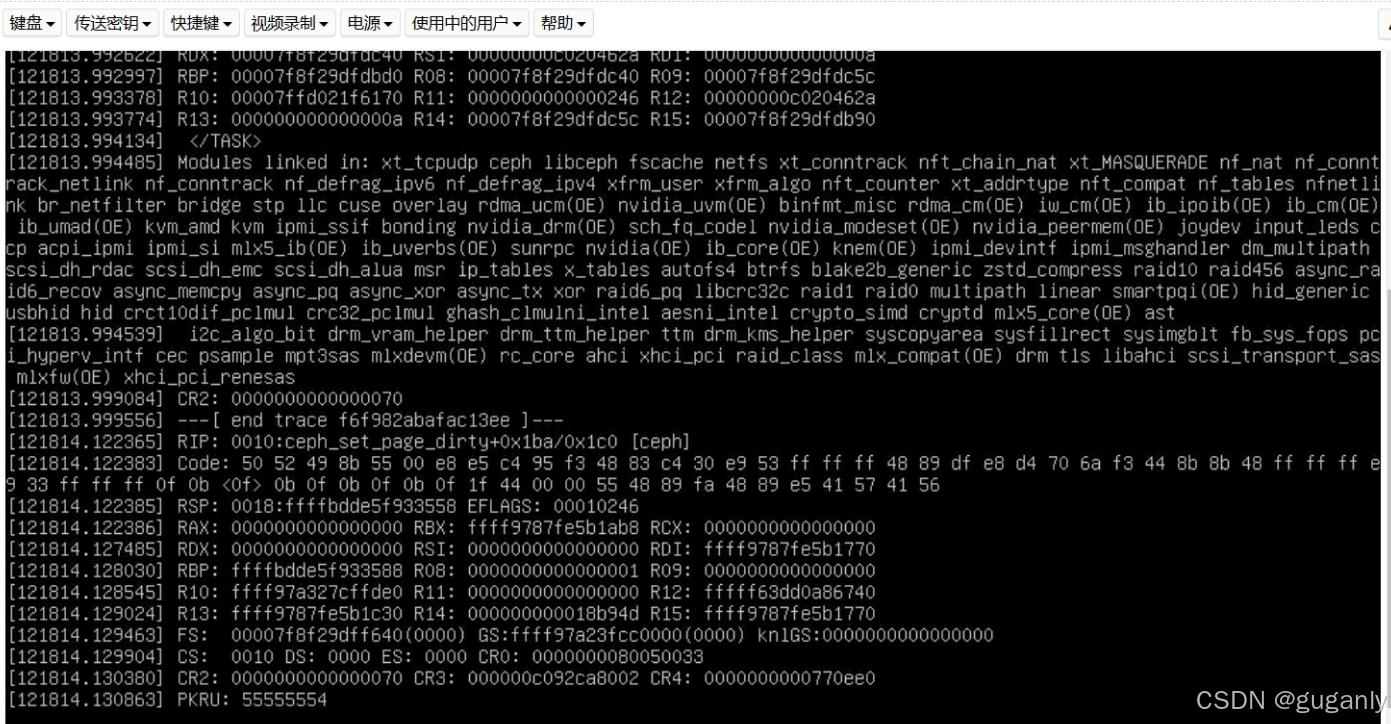
从提供的日志来看,服务器可能因为 内核崩溃(kernel panic) 而失联。日志中的 ---[ end trace f6f982abafac13ee ]--- 以及 RIP: 0010:ceph_set_page_dirty+0x1ba/0x1c0 [ceph] 表明问题可能与 Ceph 文件系统 相关。
可能的原因:
- Ceph 文件系统问题
ceph_set_page_dirty 这个函数在 Ceph 相关模块中,可能是由于 Ceph 存储故障、磁盘损坏或 Ceph 客户端 BUG 造成的崩溃。
- 硬件问题
CR2:0000000000000070 可能表示 空指针引用(NULL pointer dereference),通常是由于内存错误或者驱动程序错误导致的。
- 驱动模块冲突
日志显示 NVIDIA、Mellanox(mlx)、RDMA 相关模块,如果这些驱动有冲突,可能导致系统崩溃。
nvidia_uvm(OE), mlx5_ib(OE), ib_uverbs(OE) 等模块加载了,可能是 Mellanox RDMA 设备或者 NVIDIA 相关模块导致的。
- 内存或 I/O 设备故障
EFLAGS: 00010246 和 CR3: 00000000002Ca8002 可能表明 CPU 访问了无效的内存地址。
处理方法
- 短期恢复
- 重启服务器
由于 KVM 界面卡死,建议通过 BMC(iLO/IPMI/Redfish) 远程执行 冷重启(Power Cycle)。
如果 BMC 也无法操作,可能需要物理断电后重启。
- 进入救援模式
如果系统仍然崩溃,可以尝试进入 单用户模式 或 Live CD 进行检查。
- 长期修复
- 检查系统日志
进入系统后,查看 /var/log/messages 或 journalctl -xe 找到崩溃前的详细信息:
journalctl -k -b -1
(查看上次崩溃前的日志)
- 检查 Ceph 相关问题
运行:
dmesg | grep -i ceph
确保 Ceph 客户端和集群运行正常,检查 ceph status。
- 检查硬件
运行 内存测试(建议使用 Memtest86+)。
使用 smartctl 检查磁盘健康状态:
smartctl -a /dev/sdX
如果有 Mellanox 设备,检查驱动:
ethtool -i mlx5_core
- 升级驱动和内核
如果问题出在 Mellanox/NVIDIA 设备,建议更新固件和驱动:
sudo dnf update -y
或者升级到更稳定的 Linux 内核。
如果问题持续出现,可能需要调整 Ceph 配置、替换硬件或联系供应商进行进一步支持。



















 408
408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











