



 本文深入探讨了Spark的运行原理,包括MapReduce流程、内存管理和优化策略,以及与Hadoop的区别。解析了RDD特性、Shuffle过程和Spark的执行模式,适合希望深入了解Spark架构的开发者。
本文深入探讨了Spark的运行原理,包括MapReduce流程、内存管理和优化策略,以及与Hadoop的区别。解析了RDD特性、Shuffle过程和Spark的执行模式,适合希望深入了解Spark架构的开发者。
spark 问题总结
另可参见:https://www.cnblogs.com/miqi1992/p/5621268.html
spark 的MapReduce运行过程
-
将文件读入,并split,每个split对于一个map task
-
由input format将其转化为一个个的key/value对,然后对其调用Mapper里面的map函数分区,每个分区对应一个reduce task
-
输入输出均为hdfs,内部为map本地磁盘
spark-submit的时候如何引入外部jar包
-
把外部包打进spark程序包,一起提交
-
使用spark-submit命令的参数 --jar,带上本地外部jar包
如何解决spark内存溢出问题
-
加内存,简单粗暴 (可以加大spark.driver.memory、spark.executor.memory、spark.kryoserializer.buffer)
-
将rdd的数据写入磁盘不要保存在内存之中(因为spark过程都在内存中进行)
-
如果是collect操作导致的内存溢出,可以增大 Driver的 memory 参数
hadoop和spark的都是并行计算,那么他们有什么相同和区别
| Hadoop | spark |
|---|---|
| 只有map和reduce操作 | API中提供大量其他RDD操作如join,groupby等 |
| Map中间结果写磁盘,Reduce中间结果写HDFS,多个MR之间通过HDFS交换数据 | spark的迭代计算都是在内存中进行的 |
| Hadoop任务是一个job。 | spark任务是一个application,对应一个sparkContext,并产生一个生命周期一样的executor。 |
| job分为 map task和reduce task,task都在自己的进程里,task结束,进程结束。——任务调度和启动开销较大 | application中是job,job由action产生,几个action就几个job。每个job有多个stage,stage里面有多个task,这些task由executor执行,没有job也会有executor,因此可以快速启动运算。 |
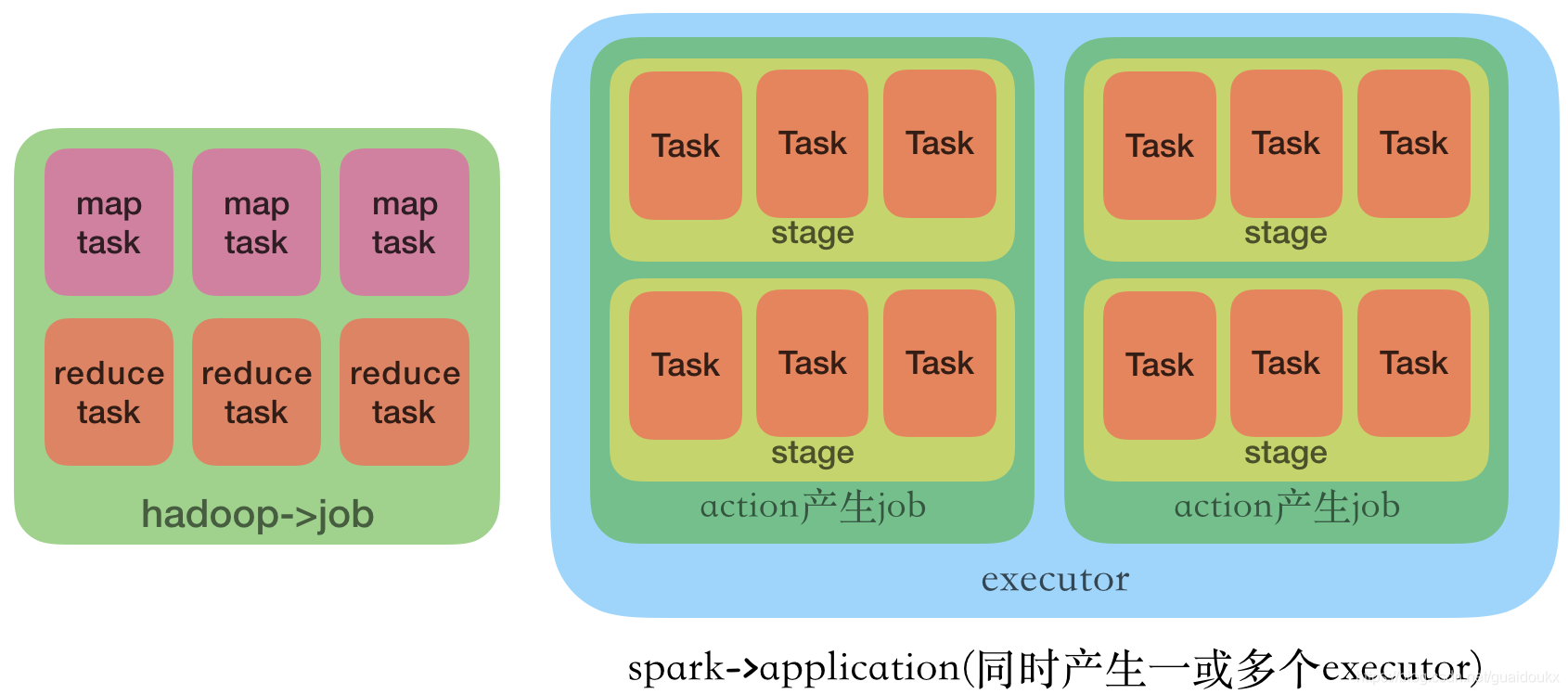
spark在一个同一框架下,可以进行批处理、流式计算、交互式计算
spark shuffle过程
Shuffle描述着数据从map task输出到reduce task输入的这段过程。shuffle是连接Map和Reduce之间的桥梁。通常shuffle分为两部分:
Map阶段的数据准备:一般将在map端的Shuffle称之为Shuffle Write,
Reduce阶段的数据拷贝处理:在Reduce端的Shuffle称之为Shuffle Read.
RDD是什么
Resilient Distributed Datasets,弹性分布式数据集
•分布在集群中的只读对象集合(由多个Partition构成)
•可以存储在磁盘,也可以存在内存中(多种存储级别)
•通过并行“转换(transformation)”操作构造,从一个RDD转换到另一个RDD
•失效后自动重构
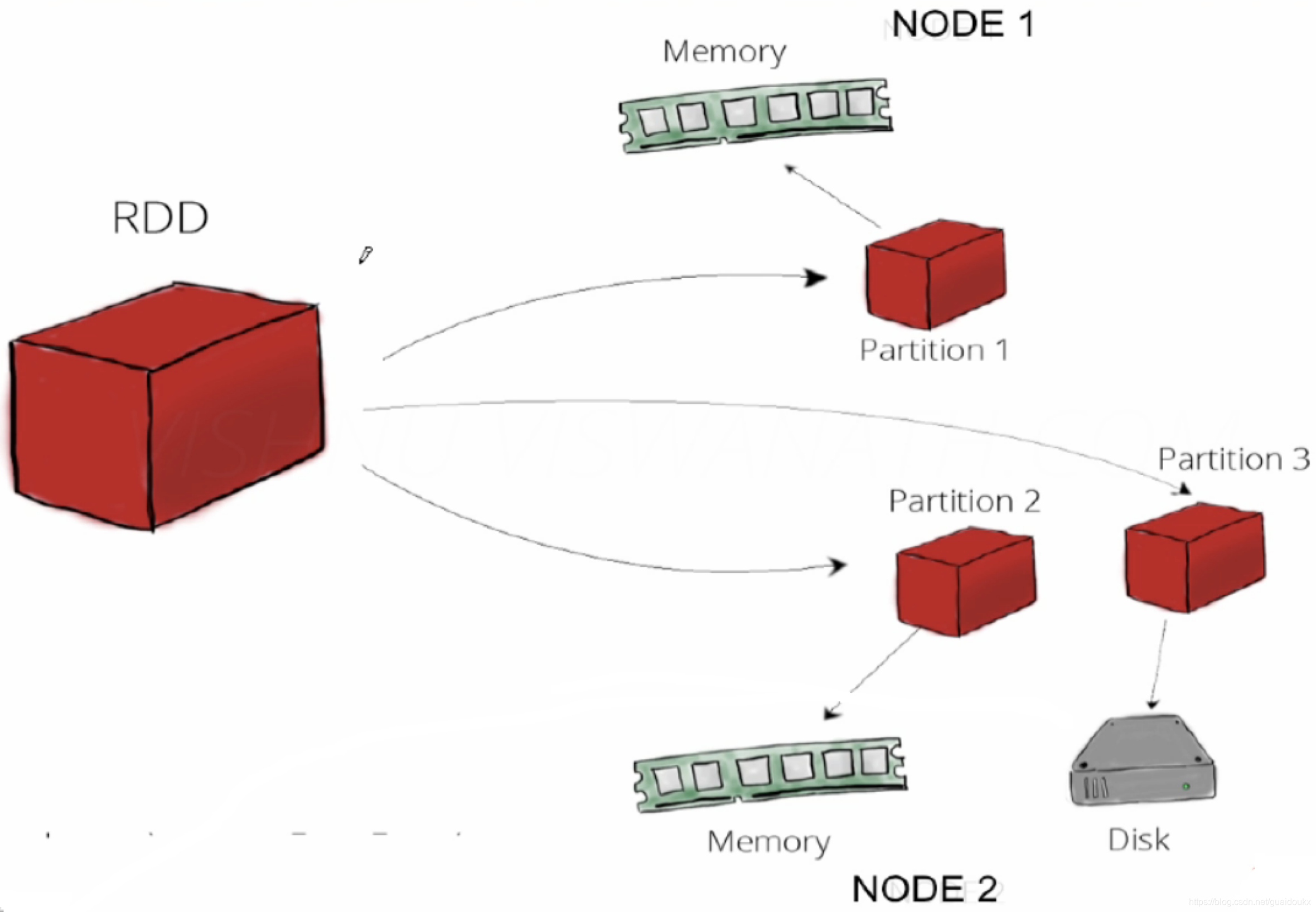
对RDD的操作
- Transformation (从一个RDD到**
另一个RDD**)
- 可通过Scala集合或者hadoop数据集构造一个新的RDD
- 通过已有的RDD产生新的RDD
- 例如:map, filter, groupByKey, reduceByKey
- Action (从一个RDD得到**
值**)
-
通过RDD计算得到一个或者一组值
-
例如:count, reduceByKey, saveAsTextFile
惰性执行( Lazy Execution)
•Transformation只会记录RDD转化关系,并不会触发计算,Action是触发程序执行的算子

Spark运行模式
详见:https://zhidao.baidu.com/question/2079382256907194868.html
- Local(本地模式)
- 单机运行,通常用于测试
- Standalone(独立模式)
- 独立运行在一个集群中,使用Spark自带的资源管理器(集群中一台机器是master,用来控制集群的资源分布)(无需依赖任何其他资源管理系统)
- Yarn/Mesos
-
运行在资源管理系统上,比如Yarn
-
Yarn-client
-
Yarn-cluster (区别我也不清楚,就说没用过就好了)
-
Spark的适用场景
Spark是基于内存的迭代计算框架,适用于需要多次操作特定数据集的应用场合。需要反复操作的次数越多,所需读取的数据量越大,受益越大,数据量小但是计算密集度较大的场合,受益就相对较小(大数据库架构中这是是否考虑使用Spark的重要因素)

















 633
633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









