 Java JVM 垃圾回收与收集器详解
Java JVM 垃圾回收与收集器详解





 本文深入探讨了Java JVM的垃圾回收机制,包括判断对象存活的可达性分析算法和三色标记法,以及各种垃圾收集算法如标记清除、标记复制、标记整理。此外,介绍了不同垃圾收集器的特点,如Serial、ParNew、ParallelScavenge、ParallelOld和CMS,以及G1收集器的区域划分和GC过程。文章还提到了JVM调优相关的工具和GC日志分析,帮助理解JVM内存管理和性能优化。
本文深入探讨了Java JVM的垃圾回收机制,包括判断对象存活的可达性分析算法和三色标记法,以及各种垃圾收集算法如标记清除、标记复制、标记整理。此外,介绍了不同垃圾收集器的特点,如Serial、ParNew、ParallelScavenge、ParallelOld和CMS,以及G1收集器的区域划分和GC过程。文章还提到了JVM调优相关的工具和GC日志分析,帮助理解JVM内存管理和性能优化。
说到jvm垃圾回收,其实就要搞清楚三个东西: 判断哪些对象是垃圾;垃圾如何搜集,搜集算法有哪些,适用什么场合;实现这些算法的垃圾搜集器有哪些,优缺点。
一:判断对象是否存活
引用计数法:
- 对象被某个地方引用时,引用计数值+1;引用失效时-1; 当为0说明不可用。
- 不能解决相互引用的问题。
可达性分析算法:
- 通过所有的GC Roots对象查找引用链,如果某个对象不在引用链上,则为不可达,可以回收掉。
- 什么样的对象可作为GC Roots对象?
- 栈帧局部变量表中reference引用的对象
- 方法区中 static 和 final引用的对象
- 本地方法栈JNI(Native方法)引用的对象
- jvm内部的引用:如 系统类加载器,常驻对象(NullPointException、OutOfMemoryError等),基本数据类型的Class对象等。
可达性分析算法标记垃圾的过程,是使用三色标记法。白色: 对象未被访问过(访问就是查找引用链的过程)黑色: 对象以及它关联的对象,都被访问过。灰色: 对象本身被访问了,但是它关联的其他对象还没有被全部访问。过程:
- 最开始时,所有对象都被放到白色集合中;
- 将GC Roots直接引用到的A类对象放到灰色集合;
- 将A类对象引用的对象全部放到灰色集合; 将A类对象放到黑色集合; 依次重复此过程,知道遍历完所有对象,这时候灰色集合为空。
- 将剩下没有在链上的白色集合中对象回收。
- finalize()是Object的方法,在上面可达性分析算法中被标记为不可用对象,也不是非死不可。 如果对象重写了finalize()方法,在此方法中将自己与引用链上任何一个对象关联,就可以不被回收。
- finalize()只能被jvm调用一次,所以只有一次拯救自己的机会。
上面说到引用链,谈一谈引用:
- 强引用:
- 强引用的对象不会被回收,内存不足时抛出OutOfMemoryError异常。 比如 A a = new A();
- 软引用:
- 内存不足时会被回收,如果内存充足,及时发生GC也不会被回收。 使用SoftReference可将对象A置为软引用
SoftReference<A> cacheRef = new SoftReference<>(new A()); 获取A对象时cacheRef.get(); 但是不能用'=' 关联,比如A a = cacheRef.get(); 否则又会变成强引用。- 适用场景:软引用的特性,比较适合作缓存。
- 弱引用:
- 不管内存是否足够,GC就会回收。 使用WeakReference可将对象A置为弱引用
WeakReference<A> cacheRef = new WeakReference<>(new A());- 适用场景:也可以作缓存。
- 虚引用:
- 虚引用必须和引用队列-ReferenceQueue 一起使用,当要被回收前,当虚引用的对象要被回收之前会加入队列,就可以用来跟踪对象被垃圾回收器回收的活动轨迹。
二:垃圾收集算法
上面已经知道了如何判别对象是否存活,下面来看看,当内存不足需要回收时,都有哪些收集垃圾的算法:
标记清除算法
- 该算法分两阶段: 标记 和 清除。 标记就是上面介绍的,扫描对象发现没有在引用链中的对象就会被标记,然后清除该对象释放内存。
- 缺点:
- 需要清除的对象越多,需要标记和清除的执行时间越长,效率越低。
- 由于对象随机分配,所以清除后会有大量内存碎片,利用率很低。
标记复制算法:
- 将内存划分为同等大小的两个区域,每次使用其中一块。 当内存不够需要回收时,将存活的对象一起复制到新的区域,再回收旧区域的所有对象。
- 标记的过程同上面一样,此算法解决了内存碎片问题,因为在复制过程中就把存活对象放到一起了。 但是还有两个问题:
- 内存利用率低,每次只能使用一半的内存,更容易发生GC。
- 如果存活对象较多,那么复制成本会增加,回收率也降低。因此,类似老年代这种就不适合了; 但是对于新生代就适用,因为90%的对象都可以被回收,所以新生代将内存默认8:1:1分成了3块。
标记整理算法:
- 为了解决复制算法的缺陷,充分利用内存,标记整理法的过程是先标记,然后将存活对象整体移动到内存空闲区,然后,将边界意外的内存回收释放。
- 这种算法与第一种-标记清除法的差别在于,回收的时候是否需要移动对象。 优缺点并存吧:
- 移动:回收内存会更复杂,停顿时间更长。
- 不移动:分配内存更复杂,因为有内存碎片。
不过话说回来,GC的最终目的就是为了能更好的分配,另外就算移动对象,整体看来吞吐量也更高。 所以相对标记清除法,整理算法还是更好一些。
对于老年代来说,对象存活时间长,数量多,所以采用标记整理的回收算法。
三:垃圾搜集器
垃圾搜集器,其实就是前面介绍的两种理论 (判断对象是否存活,使用哪一种算法搜集垃圾) 的落地实现。 当然,垃圾搜集器也有多种,侧重点不一样,下面来看一看:
- 吞吐量:CPU用于运行用户代码的时间与CPU总消耗时间的比值(吞吐量 = 运行用户代码时间 / ( 运行用户代码时间 + 垃圾收集时间 ))。例如:虚拟机共运行100分钟,垃圾收集器花掉1分钟,那么吞吐量就是99%
- 暂停时间:执行垃圾回收时,程序的工作线程被暂停的时间。
对于与用户交互较多,比较看重用户体验的系统,一般注重gc的暂停时间,如果太长,用户感觉一直卡在那里; 对于不注重用户交互的系统,比如一些运算为主的,则重视吞吐量。
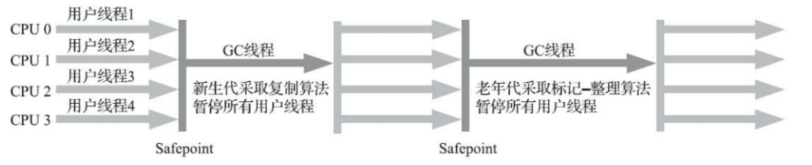
Serial属于单线程搜集器,并且在gc线程工作时,所有用户线程都要停止等待。 这种搜集器适合单核CPU下效率高,但是现在基本不适用了。 包括Serial Old针对老年代的搜集器也不适用了
使用方式:-XX:+UseSerialGC
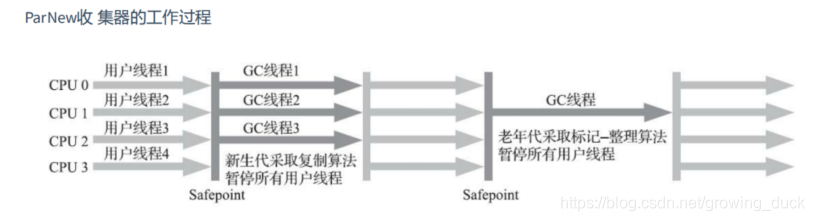
ParNew 就是Serial的多线程版本,可以设置gc的线程数。 gc过程也会停止所有用户线程
使用方式:-XX:+UseParNewGC (开启此参数老年代会使用Serial Old: ParNew+Serial Old)设置线程数 : XX:ParllGCThreads
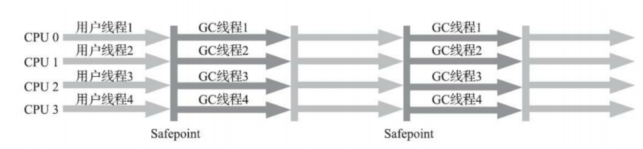
- 一个新生代的吞吐量优先的搜集器,可以自动调节新生代Eden和suvisor的比例。
- 使用方式:-XX:+UseParallelGC (开启此参数老年代会使用Serial Old: Parallel Scavenge+Serial Old)
- 最大垃圾收集停顿时间:-XX:MaxGCPauseMillis
MaxGCPauseMillis代表毫秒,并不是越小越好。 表面上看,gc时间变短了,吞吐量也上去了,这种理解是错误的。 因为gc时间变短是通过将新生代内存变小,但是这样gc次数就会更频繁,再加上cpu切换线程的损耗,虽然每次gc时间变短,但总的gc时间边长,吞吐量也下降。 比如: 新生代500M内存,10s搜集一次,每次停顿100ms。 现在将MaxGCPauseMillis设置成70,也就是每次停顿70ms,这时候内存被降低到300M,结果每5s发生一次gc。
所以,其实是以牺牲新生代内存和吞吐量为代价。
- 吞吐量大小-XX:GCTimeRatio GCTimeRatio是1-100的整数n,代表想达到n/(1+n)的吞吐量。
- 设置年轻代线程数 XX:ParllGCThreads 当cpu合数小于等于8,默认cpu核数相同; 当cpu核数超过8, ParllGCThreads设置为 3+(5*CPU_COUNT)/8
- -XX:+UseAdaptiveSizePolicy 使用该参数之后,就不要手工指定年轻代、Eden、Suvisor区的比例,晋升老年代的对象年龄等
- 作为老年代的并发搜集器,与Parallel Scavenge搭配使用,效果不错。
- 使用方式:-XX:+UseParallelOldGC (开启此参数年轻代会使用 Parallel Scavenge: Parallel Scavenge:+Parallel Old)
CMS垃圾搜集器
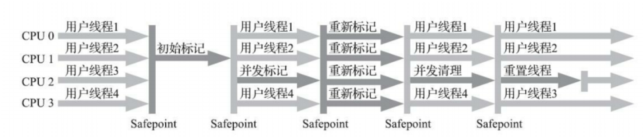
CMS是以最短停顿时间为目标的搜集器。 比之前的搜集器过程要复杂。 分为4个阶段:
- 初始标记: stop-the-world暂停所有工作线程,标记GC Roots直接关联的对象(时间很短)。
- 并发标记: gc线程与用户线程并存,根据第一步的对象查找引用链上的对象(时间较长)。
- 重新标记: 前两步已经标记了大部分对象,但在此过程中用户线程在运行,所以可能有变化,需要再次确认(时间介于前两步之间)。
- 并发清除: 开始gc。
耗时最长的是并发标记阶段,但也不需要stop-the-world,所以整个过程是低停顿的。
对于标记过程,我们知道可达性分析是用三色标记法,但是对于并发gc的搜集器,在stot-the-world阶段不会有问题,此阶段没有用户线程参与,对象引用关系不会发生变化。 但是在并发标记阶段,就可能出现多标或漏标的情况(比如将一个对象标记为灰色,这过程中引用关系断了,它应该是白色垃圾才对)。 所以,CMS还需要一个重新标记的过程,此过程也是需要STW的。
CMS缺点:
- 对cpu敏感:
其实并发搜集器对cpu都敏感,CMS更明显。 虽然并发阶段不会导致用户线程全部停止,但是会暂用一部分线程,导致程序变慢。 默认启动回收线程数是 (CPU核数n + 1) / 4; 因此,当n<4时,就会有大于25%的线程在gc,系统缓慢就会很明显了。
- 无法处理浮动垃圾:
一般老年代搜集器,在老年代空间不足时候进行Full GC,这种情况下是STW,全部是gc线程在工作。 CMS不是,在gc(标记 + 清理)过程中是允许都允许用户线程执行。 所以,即使经过重新标记阶段,到了并发清除阶段还会产生浮动垃圾(也就是多标的情况)。
另外,清除阶段允许用户线程工作,所以需要预留一定空间阈值,在jdk1.6后该阈值是92%,也就说老年代内存空间使用率达到92%就会触发gc。 即使这样,剩余空间如果还不能满足新对象分配,就会出现“并发失败”(Concurrent Mode Failure),jvm就会启动临时方案: 停止所有用户线程,使用Serial Old来回收。 一旦发生这种情况,系统停顿时间反而更长了。
- 内存碎片:
cms采用的算法是 标记-清除法,会有内存碎片产生,导致老年代剩余空间很多却不够大对象的分配,发生Full GC。 cms给了两个参数来控制进行内存碎片合并:
-XX: +UseCMS-CompactAtFullCollection 是否开启合并功能,默认是。-XX: CMSFullGCsBeforeCompaction 发生多少次Full GC后,下一次gc开始前先合并内存.
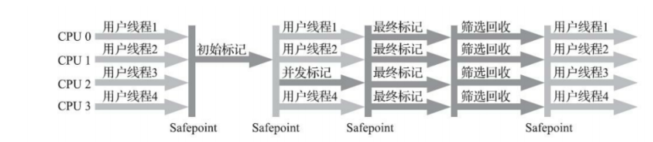
G1搜集器主要针对多cpu,大容量内存的服务端,利用高配置特性,在尽量满足最短停顿时间的同时,还能提高吞吐量。。
如上图:
- G1将堆划分约为2048个大小相同独立的region块,大小为2的N次幂,即1MB, 2MB,4MB…
- 也保留了新生代、老年代的概念,但在物理上是不连续的,这一点不同于其他搜集器; 另外,不会固定新生代和老年代的大小比例,每个Region根据实际情况都可以扮演新生代或老年代。
- 增加了一种新的Humongous区域,蓝色部分。 用于存放Region放不下的大对象,属于老年代。
G1 GC过程:
有两种GC模式,都是STW的。过程有4个阶段:
- 初始标记 :和CMS一样只标记GC Roots直接关联的对象
- 并发标记 :进行GC Roots Traceing过程
- 最终标记 :修正并发标记期间,因程序运行导致发生变化的那一部分对象
- 筛选回收 :根据时间来进行价值最大化收集
下面来看看两种GC的过程:
- Young GC: -年轻代GC。
- 当没有足够空间分配新对象时触发
- Mixed GC: -GC整个年轻代和一部分老年代。
- 当老年代的空间达到设定阈值时触发,如: -XX:InitiatingHeapOccupancyPercent=45 表示当老年代的大小占整个堆大小的45%时触发。
- 搜集过程同年轻代的图示差不多,只不过也会搜集蓝色部分的老年代垃圾。 注意: 这里不是搜集所有的老年代区域,只是其中一部分。 在并发标记和最终标记过程中会计算老年代区域回收区域中,哪些区域回收价值最大。
其实:还有full gc阶段。 如果在mixed gc过程中,分配速度过快内存不足就会发生full gc,但是应该尽量调优防止full gc的发生。
参数设置:
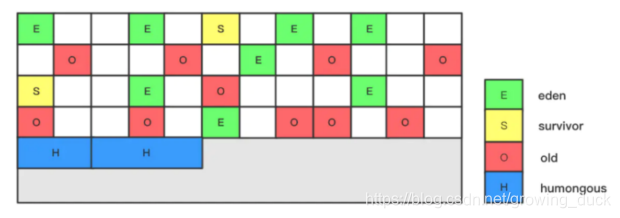


好了,了解这么多GC搜集器,年轻代和老年代怎么组合呢?
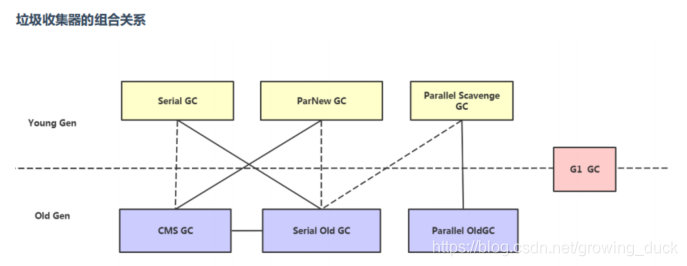
图中虚线代表,可以但是不建议组合使用的搭配。
四:jvm 常用指令
jps:
jps [options] [hostid] 。 查看服务器上所有java进程的情况,本机可以不写hostid
jps -l 输出 jar 包路径,类全名jps -m 输出 main 参数jps -v 输出 JVM 参数
jinfo:
jinfo [option] <pid>。查看JVM运行的设置参数,也可以动态修改jvm参数
options 参数解释:- no options 输出所有的系统属性和参数
- -flag <name> 打印指定名称的参数
- -flag [+|-]<name> 打开或关闭参数
- -flag <name>=<value> 动态设置参数
- -flags 打印所有参数
- -sysprops 打印系统配置
jinfo -flag MaxHeapSize 2788; 查看进程号为2788的最大堆内存
jinfo -flags 2788; 不指定名字,就是查看所有的参数信息 ':=' 这种是手动改过的参数
jinfo -flag +PrintGCDetails 2788; 开启打印gc的详细信息(没有+,则是查看该参数的启用情况)
jstat:
jstat [option] <pid> [interval] [count] 。 查看JVM运行时候状态信息
interval count: 间隔多长时间打印一次信息,总共打印多少次。 count 不指定默认一直打印
jstat -class pid 1000 10 查看类加载信息,1s统计一次,共10次
jstat -gc 17970 2000 20 查看gc情况,2s统计一次,共20次
jstack:
jstack 观察线程情况 常用在cpu飙高时,如产生死锁或者死循环,如查找死循环:
a、用top命令查看暂用cpu高的pid
b、jstack pid > pid.txt 把线程情况输入到文件中
c、sz pid.txt 下载文件下来
d、top -p pid -H 用top命令查看该pid内,占用cpu高的线程,,取一个占用较高的线程id到刚才的文件中查找,看看该线程执行了什么方法(文件中的id是线程16进制的),可以看到,执行该方法的可能还有其他多个线程,这些线程cpu占有率都是较高的。
jmap:
jmap [option] <pid>
jmap 查看物理内存占用情况,可以查看某个进程内所有对象情况,最常用的是导出内存日志文件,用jhat或者MAT分析内存溢出情况,如:
jmap -dump:format=b,file=heap.hprof pid
另一种情况是启动时加参数,发生溢出时候自动导出:
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=./
五: GC日志
在jvm启动时,要加上一些gc日志参数,这样才能打印gc日志,方便进行分析:
- -XX:+PrintGC:打印简单GC日志。 类似:-verbose:gc
- -XX:+PrintGCDetails :打印GC详细信息
- -XX:+PrintGCTimeStamps :输出GC的时间戳(以基准时间的形式)
- -XX:+PrintGCDateStamps :输出GC的时间戳(以日期的形式)
- -XX:+PrintHeapAtGC :在进行GC的前后打印出堆的信息
- -Xloggc:../logs/gc.log :指定输出路径收集日志到日志文件
GC日志分析:
[GC (Allocation Failure) [PSYoungGen: 6146K->904K(9216K)] 6146K->5008K(19456K), 0.0038730
secs] [Times: user=0.08 sys=0.00, real=0.00 secs]
发生了GC,原因是内存分配失败。 发生的区域是新生代,gc前使用了6146k,gc后使用了904k, 新生代总大小是9216k; gc前堆总共使用了6146k,gc后使用了5008k,整个堆的大小是19456k。 堆gc的总耗时是0.0038730s。 用户态消耗的cpu时间是0.08s,内核态消耗cpu时间是0s,gc的时间是0s(实际是有时间的,只不过只取了两位精度)。
GC日志分析工具:
GC日志通常非常多,我们不可能凭肉眼去看上面的内容。 这时候就需要可视化的分析工具。 下面推荐两个:
- GCeasy:一款在线的GC日志分析器,可以免费使用:在线分析工具 https://gceasy.io/index.jsp
- GCViewer:需要安装jdk或者java环境才可以使用。
- 下载:https://sourceforge.net/projects/gcviewer
- 启动:java -jar gcviewer-1.37-SNAPSHOT.jar
注意,gc日志和上面jmap导出的dump文件是两个东西。 gc日志主要是为了分析gc的情况,进行jvm调优等。 dump文件通常是cpu飚高,内存暂用大时,分析内存对象情况的。

















 1824
1824

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









