 微积分在机器学习中的多元函数导数知识
微积分在机器学习中的多元函数导数知识








| 数据科学、数据分析、人工智能必备知识汇总-----主目录-----持续更新(进不去说明我没写完):https://blog.youkuaiyun.com/grd_java/article/details/140174015 |
|---|
1. 偏导数
之前讲的导数,是针对一元函数来讲的。
偏导数是导数的推广,对于多元函数来说,如果只对其中一元求偏导,那么其它自变量就固定不动,看成常量。也就是说偏偏只对一个变量求导数
d y d x \dfrac{dy}{dx} dxdy是对x求全导数的,如果我们对多元函数求导,里面的x直接求导,而y,z,…都认为是关于x的函数,也要求导
∂ f ∂ x \dfrac{\partial f}{\partial x} ∂x∂f是对x求偏导数,对于多元函数求导,里面x直接求导,而其他的y,z,…都认为是常数。
∂ f ∂ x 0 = d d x f ( x , y 0 ) ∣ x = x 0 = f x ′ ( x 0 , y 0 ) \dfrac{\partial f}{\partial x_0} =\dfrac{d}{dx}f (x,y_0)|_{x=x_0} = f^{'}_x(x_0,y_0) ∂x0∂f=dxdf(x,y0)∣x=x0=fx′(x0,y0)
上面是对一元函数f(x,y_0)在x_0处导数的3种写法,都代表相同的意思
∂ f ( x 0 , y 0 ) ∂ x = lim Δ x → 0 f ( x 0 + Δ x , y 0 ) − f ( x 0 , y 0 ) Δ x \dfrac{\partial f(x_0,y_0)}{\partial x}=\displaystyle\lim_{\Delta x \to 0}\dfrac{f(x_0+\Delta x,y_0)-f(x_0,y_0)}{\Delta x} ∂x∂f(x0,y0)=Δx→0limΔxf(x0+Δx,y0)−f(x0,y0)
∂ f ( x 0 , y 0 ) ∂ y = lim Δ y → 0 f ( x 0 , y 0 + Δ y ) − f ( x 0 , y 0 ) Δ y \dfrac{\partial f(x_0,y_0)}{\partial y}=\displaystyle\lim_{\Delta y \to 0}\dfrac{f(x_0,y_0+\Delta y)-f(x_0,y_0)}{\Delta y} ∂y∂f(x0,y0)=Δy→0limΔyf(x0,y0+Δy)−f(x0,y0)
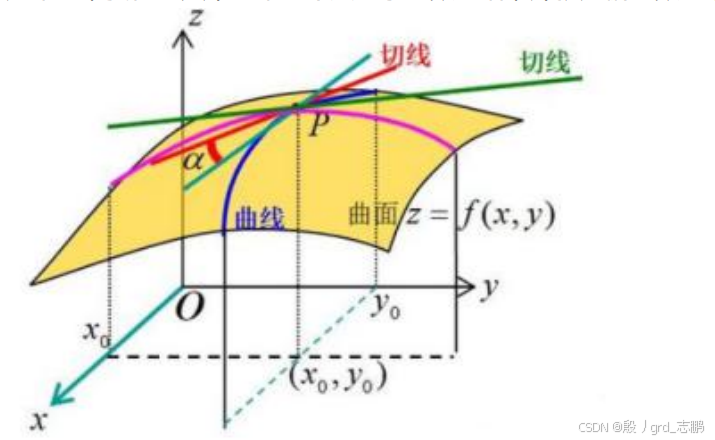
几何上面来讲的话,当我们将其它自变量全部设定为常数时,例如下图中,y恒定时,我们研究的曲线就是一个二维平面了,此时研究多元就变成了一元函数
就是在某个方向上对原函数来切一下,再去求导,就是偏导数

例子:已知 f ( x , y ) = x 2 + x y − y 2 f(x,y) = x^2 + xy - y^2 f(x,y)=x2+xy−y2
∂ f ∂ x = 2 x + y − 0 \dfrac{\partial f}{\partial x} = 2x+y - 0 ∂x∂f=2x+y−0
∂ f ∂ y = 0 + x − 2 y \dfrac{\partial f}{\partial y} = 0+x-2y ∂y∂f=0+x−2y
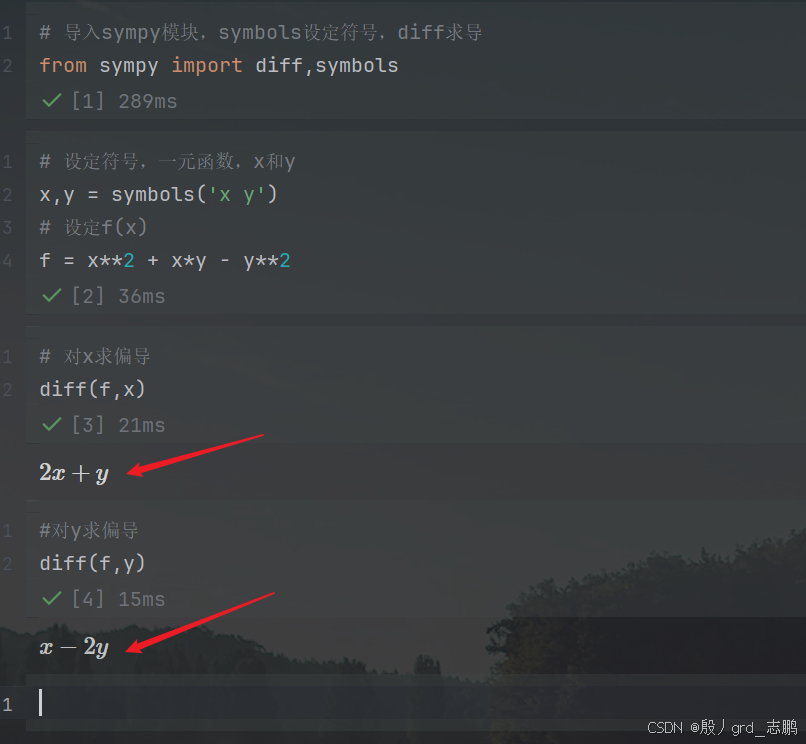
接下来用python来验证一下
# 导入sympy模块,symbols设定符号,diff求导
from sympy import diff,symbols
# 设定符号,一元函数,x和y
x,y = symbols('x y')
# 设定f(x)
f = x**2 + x*y - y**2
# 对x求偏导
diff(f,x)
#对y求偏导
diff(f,y)
2. 高阶偏导数
∂ 2 f 省略 \dfrac{\partial^2 f}{省略} 省略∂2f:看上面,可以知道是对函数f求2阶偏导,而分母下面就是对谁求
∂ 2 f ∂ x 2 = ∂ ∂ x ( ∂ f ∂ x ) \dfrac{\partial^2 f}{\partial x^2}=\dfrac{\partial}{\partial x}(\dfrac{\partial f}{\partial x}) ∂x2∂2f=∂x∂(∂x∂f):表示两次偏导都对x求
∂ 2 f ∂ x ∂ y = ∂ ∂ y ( ∂ f ∂ x ) \dfrac{\partial^2 f}{\partial x \partial y}=\dfrac{\partial}{\partial y}(\dfrac{\partial f}{\partial x}) ∂x∂y∂2f=∂y∂(∂x∂f):表示先对x求偏导,再对y求偏导
∂ 2 f ∂ y ∂ x = ∂ ∂ x ( ∂ f ∂ y ) \dfrac{\partial^2 f}{\partial y \partial x}=\dfrac{\partial}{\partial x}(\dfrac{\partial f}{\partial y}) ∂y∂x∂2f=∂x∂(∂y∂f):表示先对y求偏导,然后再对x求偏导
∂ 2 f ∂ y 2 = ∂ ∂ y ( ∂ f ∂ y ) \dfrac{\partial^2 f}{\partial y^2}=\dfrac{\partial}{\partial y}(\dfrac{\partial f}{\partial y}) ∂y2∂2f=∂y∂(∂y∂f):表示两次偏导都对y求
所以和一元高阶导数差不多,只不过多元函数求高阶偏导,可以依次选择对哪个变量求
例子:设 f ( x , y ) = x 2 + x y − y 2 f(x,y) = x^2 + xy -y^2 f(x,y)=x2+xy−y2
∂ 2 f ∂ 2 x = ∂ ∂ x ( 2 x + y ) = 2 \dfrac{\partial^{2} f}{\partial^{2} x} =\dfrac{\partial}{\partial x}(2x+y)=2 ∂2x∂2f=∂x∂(2x+y)=2
∂ 2 f ∂ x ∂ y = ∂ ∂ y ( 2 x + y ) = 1 \dfrac{\partial^{2} f}{\partial x \partial y} =\dfrac{\partial}{\partial y}(2x+y)=1 ∂x∂y∂2f=∂y∂(2x+y)=1
∂ 2 f ∂ y ∂ x = ∂ ∂ x ( x − 2 y ) = 1 \dfrac{\partial^{2} f}{\partial y \partial x} =\dfrac{\partial}{\partial x}(x-2y)=1 ∂y∂x∂2f=∂x∂(x−2y)=1
∂ 2 f ∂ 2 y = ∂ ∂ y ( x − 2 y ) = − 2 \dfrac{\partial^{2} f}{\partial^{2} y} =\dfrac{\partial}{\partial y}(x-2y)=-2 ∂2y∂2f=∂y∂(x−2y)=−2
此时我们可以发现 ∂ 2 f ∂ x ∂ y \dfrac{\partial^{2} f}{\partial x \partial y} ∂x∂y∂2f = ∂ 2 f ∂ y ∂ x \dfrac{\partial^{2} f}{\partial y \partial x} ∂y∂x∂2f,这就可以衍生出一个重要定理——偏导连续,混偏相同。也就是高阶导数和求导次序无关。
如果函数 z = f ( x , y ) z=f(x,y) z=f(x,y)的两个二阶混合偏导数 f x y ′ ′ ( x , y ) f^{''}_{xy}(x,y) fxy′′(x,y)及 f y x ′ ′ ( x , y ) f^{''}_{yx}(x,y) fyx′′(x,y)在区域D内连续,则在区域D内恒有 f x y ′ ′ ( x , y ) = f y x ′ ′ ( x , y ) f^{''}_{xy}(x,y)=f^{''}_{yx}(x,y) fxy′′(x,y)=fyx′′(x,y),也就是 ∂ 2 f ∂ x ∂ y \dfrac{\partial^{2} f}{\partial x \partial y} ∂x∂y∂2f = ∂ 2 f ∂ y ∂ x \dfrac{\partial^{2} f}{\partial y \partial x} ∂y∂x∂2f
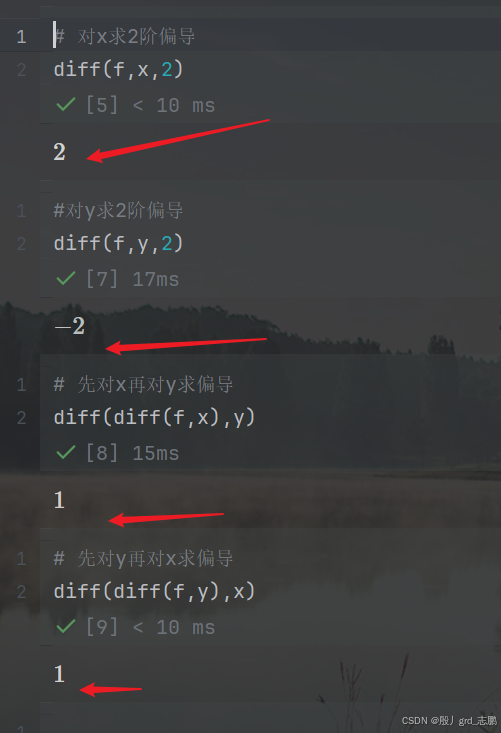
python验证一下
# 导入sympy模块,symbols设定符号,diff求导
from sympy import diff,symbols
# 设定符号,一元函数,x和y
x,y = symbols('x y')
# 设定f(x)
f = x**2 + x*y - y**2
# 对x求2阶偏导
diff(f,x,2)
#对y求2阶偏导
diff(f,y,2)
# 先对x再对y求偏导
diff(diff(f,x),y)
# 先对y再对x求偏导
diff(diff(f,y),x)
3. 梯度
机器学习中的梯度下降法和牛顿法很多地方都会用到梯度的概念
∇ f ( x ) \nabla f(x) ∇f(x)= ( ∂ f ∂ x 1 , ∂ f ∂ x 2 , ⋯ , ∂ f ∂ x n ) T \Bigg({\dfrac{\partial f}{\partial x_1},\dfrac{\partial f}{\partial x_2},\cdots,\dfrac{\partial f}{\partial x_n}}\Bigg)^{T} (∂x1∂f,∂x2∂f,⋯,∂xn∂f)T
梯度可以看成是一元函数它的导数,对于多元函数的推广。对于多元函数如果它的自变量有 N 个,例如 x 1 x 2 ⋯ x n x_1\space x_2 \space \cdots \space x_n x1 x2 ⋯ xn
那么它的梯度是个向量,是由对 x 1 x 2 x_1\space x_2 x1 x2 等,不断的求偏导数构成的一个向量,称之为梯度
梯度我们用倒三角(nabla)这个符号来表示,作用于 f ( x ) f(x) f(x)得到这样一个向量,式子里面的 T T T表示往往我们把它转置一下,看成是列向量
4. 雅可比矩阵
本科高数不学的东西,就是由一阶偏导数构成的矩阵,发明它的目的主要是为了
简化求导公式,对多元的复合函数求导,如果我们用雅可比矩阵来计算的话,它会写起来非常简洁,这在我们的人工神经网络反向推导的过程中往往会看到的鉴于可能有人没学过神经网络,所以假设神经网络有两层A和B,A有3个神经元 x 1 , x 2 , x 3 x_1,x_2,x_3 x1,x2,x3,B有2个 y 1 , y 2 y_1,y_2 y1,y2。现在要A通过某函数f,3个节点映射到B的2个上,就需要用到这个矩阵
假设有这样一个函数 y i = f ( x i ) y_i = f(x_i) yi=f(xi)可以把 n 维 x 向量 n维x向量 n维x向量映射为 k 维的向量 y k维的向量 y k维的向量y
{ y = f ( x ) ↑ ↑ k n \begin{cases} y &= &f(x)\\ \uarr & & \uarr\\ k & & n \end{cases} ⎩ ⎨ ⎧y↑k=f(x)↑n
其中每个 x ı ˋ x_ì xıˋ和每个 y i y_i yi 都是相关的,也就是每个 y i y_i yi都是单独从 x i x_i xi映射过来的函数。它的雅可比矩阵就是每个 y i y_i yi 分别对每个 x i x_i xi 求偏导,然后构成的矩阵叫做雅可比矩阵
第一行就是 y 1 对 x 1 y_1 对 x_1 y1对x1、 x 2 一直到 x n x_2 一直到 x_n x2一直到xn 求偏导,第二行就是 y 2 对 x 1 、 x 2 一直到 x n y_2 对 x_1、x_2 一直到 x_n y2对x1、x2一直到xn求偏导,第k行就是 y k 对 x 1 y_k 对 x_1 yk对x1、 x 2 一直到 x n x_2 一直到 x_n x2一直到xn求偏导
[ ∂ y 1 ∂ x 1 ∂ y 1 ∂ x 2 ⋯ ∂ y 1 ∂ x n ∂ y 2 ∂ x 1 ∂ y 2 ∂ x 2 ⋯ ∂ y 2 ∂ x n ⋯ ⋯ ⋯ ⋯ ∂ y k ∂ x 1 ∂ y k ∂ x 2 ⋯ ∂ y k ∂ x n ] \begin{bmatrix} \dfrac{\partial y_1}{\partial x_1} & \dfrac{\partial y_1}{\partial x_2} & \cdots &\dfrac{\partial y_1}{\partial x_n} \\\\ \dfrac{\partial y_2}{\partial x_1} & \dfrac{\partial y_2}{\partial x_2} & \cdots &\dfrac{\partial y_2}{\partial x_n} \\\\ \cdots & \cdots & \cdots &\cdots \\\\ \dfrac{\partial y_k}{\partial x_1} & \dfrac{\partial y_k}{\partial x_2} & \cdots &\dfrac{\partial y_k}{\partial x_n} \\\\ \end{bmatrix} ∂x1∂y1∂x1∂y2⋯∂x1∂yk∂x2∂y1∂x2∂y2⋯∂x2∂yk⋯⋯⋯⋯∂xn∂y1∂xn∂y2⋯∂xn∂yk
如果 x i x_i xi 是 n n n维向量,y是k个值的结果,那么雅可比矩阵就是 k ∗ n k*n k∗n 的矩阵
[ y 1 y 2 ] y 1 = x 1 2 + 2 x 1 x 2 + x 3 y 2 = x 1 − x 2 2 + x 3 2 [ x 1 x 2 x 3 ] \begin{bmatrix} y_1 \\\\y_2 \end{bmatrix}\begin{array}{cc} y_1 = x_1^2 + 2x_1x_2+x_3 \\\\ y_2 = x_1 - x_2^2+x_3^2 \end{array}\begin{bmatrix} x_1 \\\\x_2\\\\x_3 \end{bmatrix} y1y2 y1=x12+2x1x2+x3y2=x1−x22+x32 x1x2x3
如果 x 1 , x 2 , x 3 x_1,x_2,x_3 x1,x2,x3 会映射成为 y 1 , y 2 y_1,y_2 y1,y2, y 1 是 x 1 , x 2 , x 3 y_1 是 x_1,x_2,x_3 y1是x1,x2,x3 的函数, y 2 也是 x 1 , x 2 , x 3 y_2 也是 x_1,x_2,x_3 y2也是x1,x2,x3 的函数,那么它的雅可比矩阵是怎么构成的呢 ?
[ 2 x 1 + 2 x 2 2 x 1 1 1 − 2 x 2 2 x 3 ] \begin{bmatrix} 2x_1+2x_2 & 2x_1 &1 \\\\ 1 & -2x_2 & 2x_3 \end{bmatrix} 2x1+2x212x1−2x212x3
5. Hessian 矩阵
对于一个多元函数来说的,它就相当于一元函数的二阶导数
怎么定义的呢?有一个n元函数,例如 x 1 , x 2 直到 x n x_1,x_2 直到 x_n x1,x2直到xn
它的 hessian 矩阵是一个 n*n的矩阵,矩阵里面的元素是什么呢?
它的所有的元素是二阶偏导数构成的,第一个元素是对 x 1 x_1 x1 求二阶偏导数,第二个元素是对 x 1 x 2 x_1x_2 x1x2 求偏导数,因为咱们前面讲过,多元函数高阶偏导数和顺序无关,所以 hessian 矩阵是对称矩阵
[ ∂ 2 f ∂ x 1 2 ∂ 2 f ∂ x 1 ∂ x 2 ⋯ ∂ 2 f ∂ x 1 ∂ x n ∂ 2 f ∂ x 2 ∂ x 1 ∂ 2 f ∂ x 2 2 ⋯ ∂ 2 f ∂ x 2 ∂ x n ⋯ ⋯ ⋯ ⋯ ∂ 2 f ∂ x n ∂ x 1 ∂ 2 f ∂ x n ∂ x 2 ⋯ ∂ 2 f ∂ x n 2 ] \begin{bmatrix} \dfrac{\partial^2 f}{\partial x_1 ^2} & \dfrac{\partial^2 f}{\partial x_1 \partial x_2} & \cdots & \dfrac{\partial^2 f}{\partial x_1 \partial x_n}\\\\ \dfrac{\partial^2 f}{\partial x_2 \partial x_1} & \dfrac{\partial^2 f}{\partial x_2^2} & \cdots & \dfrac{\partial^2 f}{\partial x_2 \partial x_n}\\\\ \cdots & \cdots & \cdots & \cdots\\\\ \dfrac{\partial^2 f}{\partial x_n \partial x_1} & \dfrac{\partial^2 f}{\partial x_n \partial x_2} & \cdots & \dfrac{\partial^2 f}{\partial x_n^2} \end{bmatrix} ∂x12∂2f∂x2∂x1∂2f⋯∂xn∂x1∂2f∂x1∂x2∂2f∂x22∂2f⋯∂xn∂x2∂2f⋯⋯⋯⋯∂x1∂xn∂2f∂x2∂xn∂2f⋯∂xn2∂2f
例子: 设 f ( x , y , z ) = 2 x 2 − x y + y 2 − 3 z 2 设f(x,y,z) = 2x^2 - xy + y^2 - 3z^2 设f(x,y,z)=2x2−xy+y2−3z2,接下来按如下顺序依次求2阶偏导,然后一行一行放到矩阵中,就构成了 hessian 矩阵
∂ 2 f ∂ x 2 = ∂ ∂ x ( 4 x − y ) = 4 \dfrac{\partial^2 f}{\partial x^2} = \dfrac{\partial}{\partial x}(4x - y) = 4 ∂x2∂2f=∂x∂(4x−y)=4
∂ 2 f ∂ x ∂ y = ∂ ∂ y ( 4 x − y ) = − 1 \dfrac{\partial^2 f}{\partial x \partial y} = \dfrac{\partial}{\partial y}(4x - y) = -1 ∂x∂y∂2f=∂y∂(4x−y)=−1
∂ 2 f ∂ x ∂ z = ∂ ∂ z ( 4 x − y ) = 0 \dfrac{\partial^2 f}{\partial x \partial z} = \dfrac{\partial}{\partial z}(4x - y) = 0 ∂x∂z∂2f=∂z∂(4x−y)=0
∂ 2 f ∂ y ∂ x = ∂ ∂ x ( − x + 2 y ) = − 1 \dfrac{\partial^2 f}{\partial y \partial x} = \dfrac{\partial}{\partial x}(-x + 2y) = -1 ∂y∂x∂2f=∂x∂(−x+2y)=−1**
∂ 2 f ∂ y 2 = ∂ ∂ y ( − x + 2 y ) = 2 \dfrac{\partial^2 f}{\partial y^2} = \dfrac{\partial}{\partial y}(-x + 2y) = 2 ∂y2∂2f=∂y∂(−x+2y)=2
∂ 2 f ∂ y ∂ z = ∂ ∂ z ( − x + 2 y ) = 0 \dfrac{\partial^2 f}{\partial y \partial z} = \dfrac{\partial}{\partial z}(-x + 2y) = 0 ∂y∂z∂2f=∂z∂(−x+2y)=0
∂ 2 f ∂ z ∂ x = ∂ ∂ x ( − 6 z ) = 0 \dfrac{\partial^2 f}{\partial z \partial x} = \dfrac{\partial}{\partial x}(-6z) = 0 ∂z∂x∂2f=∂x∂(−6z)=0
∂ 2 f ∂ z ∂ y = ∂ ∂ y ( − 6 z ) = 0 \dfrac{\partial^2 f}{\partial z \partial y} = \dfrac{\partial}{\partial y}(-6z) = 0 ∂z∂y∂2f=∂y∂(−6z)=0
∂ 2 f ∂ z 2 = ∂ ∂ z ( − 6 z ) = − 6 \dfrac{\partial^2 f}{\partial z^2} = \dfrac{\partial}{\partial z}(-6z) = -6 ∂z2∂2f=∂z∂(−6z)=−6
hessian矩阵为: [ 4 − 1 0 − 1 2 0 0 0 − 6 ] \begin{bmatrix} 4 & -1 & 0\\\\ -1 & 2 & 0\\\\ 0 & 0 & -6 \end{bmatrix} 4−10−12000−6
Hessian 矩阵和函数的凹凸性是有密切关系的,如果 hessian 矩阵正定,可以说函数 f(x)是凸函数,如果是负定,它就是凹函数,矩阵正定怎么定义的呢 ?
6. 极值判别法则
之前的微积分基础中讲过,对于一元函数,f(x)的一阶导数等于0处有极值,当 f(x)的二阶导数大于 0时是极小值,当 f(x)的二阶导数小于0时是极大值,可以参考X的平方这个函数
https://blog.youkuaiyun.com/grd_java/article/details/144348388

多元函数的极值判别法则
首先 f(x)的一阶导数等于0,这点是驻点的话,那它就可能是极值点,它是极大值还是极小值或者不是极值怎么判定的 ?
看 hessian 矩阵,在 f(x)的一阶导数等于0处,就是驻点处
如果 hessian 矩阵是正定的话,函数在该点有极小值
如果 hessian 矩阵是负定的话,函数在该点有极大值
如果 hessian 矩阵不定,还需要看更高阶的导数
正定是线性代数的知识:https://blog.youkuaiyun.com/grd_java/article/details/144393637
对于任意向量 X ≠ 0 X≠0 X=0,都有 x T A x > 0 x^TAx>0 xTAx>0,那就是正定矩阵,如果是 ≥ ≥ ≥的话,那就是半正定矩阵。怎么判断矩阵是正定的呢?
X T X X^TX XTX半正定:对于任意的非零向量 u u u, u X T X u = ( X u ) T X u → 令 v = X u v T v ≥ 0 uX^TXu = (Xu)^TXu\space\xrightarrow{令v = Xu}\space v^Tv≥0 uXTXu=(Xu)TXu 令v=Xu vTv≥0
上面这个反正我是不想用,一般会根据以下几个原则去判断
矩阵的特征值全部大于0
矩阵的所有顺序主子式都大于 0,这个一般上学时候考试做题用的多,机器学习用的少,几乎没用过
矩阵合同于单位矩阵





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











