



定制CPU实现上的实时事件处理与抢占式硬件RTOS调度
摘要
现场可编程门阵列(FPGA)器件的快速发展极大地影响了设计方法学和开发工具。本文描述了一种基于硬件结构的原始实现,用于静态与动态任务调度。所提出的定制处理器具备实时操作系统硬件(HW‐RTOS)的功能,并通过FPGA电路进行验证。该解决方案用资源重映射机制取代了传统的堆栈保存概念,使得新任务可以从下一个处理器周期立即执行。所提出的硬件调度器实现了事件与中断的统一管理,通过将中断附加到任务的方法,同时保证满足实时系统的要求。所提出平台的鲁棒性和性能由上下文切换操作、任务间同步、通信机制以及多路复用资源的有效利用来保障。通过直接切换任务资源的数据路径,而非在内存中保存和恢复通用寄存器,从而消除了延迟。
索引词 — 现场可编程门阵列(FPGAs)、流水线处理、实时系统(RTSs) 调度
一、引言
自从计算单元的硬件实现成本已降低,设计技术也取得了显著进步[1],[2],架构师不断创新附加功能以保证系统可预测性和程序执行的并行性的能力[3]。
考虑到处理器性能的不断提升,就实时事件执行而言,所提出的解决方案的新颖之处在于我们减轻了中央处理器的调度活动,从而实现了更高的利用率。通过在硬件中实现调度算法并显著减少上下文切换时间,操作系统特定开销被大幅降低。当前实时操作系统(RTSs)的局限性体现在:1)CPU架构、内存和I/O子系统;2)高级语言及其编译器;3)异步中断的不可预测响应。上下文切换是调度算法和实时系统(RTSs)中的关键因素[4],因为它使操作系统能够进行系统将处理器分配给更高优先级任务。在全抢占式系统中,当前任务的执行可能在任何时刻被更高优先级的任务中断。被中断任务的执行只有在没有更高优先级任务就绪时才会恢复。在某些实现中,可以完全禁止上下文切换,以避免任务之间不可预测的干扰,并提高实时系统的鲁棒性。实时调度器必须根据坚实的理论原则进行设计,以确保程序的正确执行以及受控应用的正常运行。
可编程逻辑技术是任何电路设计师工具包的基本组成部分,并为嵌入式开发者设备提供支持。
为了获得对实时进程中异步事件的更短响应时间,研究人员针对处理器和RTOS架构展开了深入研究[5]。在这种情况下,该领域的大多数研究者得出结论:由于硬件实现的RTOS(HW‐RTOS),能够提升信息的并行处理能力,从而降低嵌入式系统的响应时间,因此必须将部分组件(甚至整个RTOS)嵌入到硬件中。
该解决方案引入了一种在硬件中实现的可配置抢占式调度器。实时事件处理的实现支持带有动态优先级的任务数量配置。中央处理器资源的复制确保了在抢占式硬件调度器直接控制下的硬件任务隔离。硬件实时操作系统(HW‐RTOS)可显著降低事件触发延迟,并成功消除大部分调度开销,为嵌入式应用提供更多的计算周期。
本工作的主要贡献是针对时间可预测的嵌入式系统提出的硬件调度器概念。动态调度器对实时操作系统的开销具有重大影响。实时处理器对操作系统设计的软件影响相当直接。
本文组织如下。第二节对不同的实时操作系统进行了比较,并分析了来自实时嵌入式系统领域的类似文章。第三节介绍了基于MIPS32架构的硬件RTOS加速器的概念。第四节描述了在验证第三节中提出的理论要素期间获得的实际结果。第五节提出了结论和未来研究方向。
II. 基于MIPS32架构的硬件RTOS加速器的概念与工作原理
本文提出的解决方案可用于多种特定应用,以监控和控制工业流程。通过使用硬件调度器,在实时应用环境中,中断的行为更加可预测,因为任务只能被关联到更高优先级任务的中断所打断。从经济影响来看,该解决方案通过集成到软件应用的新现场总线和网络设备中,可带来显著的生产力增长。
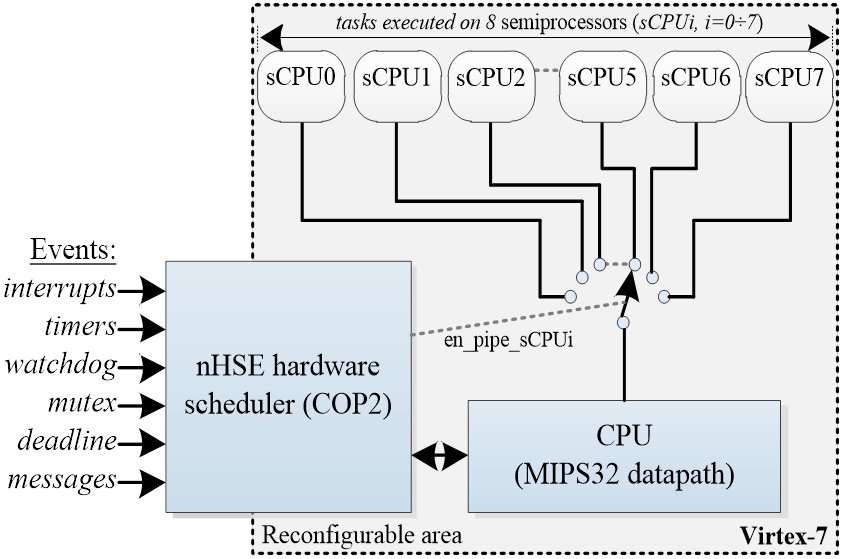
nMPRA(用于n个任务的多流水线寄存器架构)概念指的是一种具有多个(n)流水线寄存器的架构,最初在和中提出并描述。该项目基于五级MIPS流水线结构,其程序计数器、流水线寄存器和通用寄存器均被复制了n倍。结果形成了一种表示n倍复用资源的结构,称为半处理器(sCPU)。该sCPU的第i个实例被称为半处理器i(sCPUi)。基于nHSE(硬件调度引擎),提出的解决方案提供了一种对中断和事件进行统一管理的方法。根据硬件触发事件,硬件实时操作系统(HW‐RTOS)决定哪个任务(sCPUi)在CPU数据路径上执行。如图1所示,HW‐RTOS(nMPRA+nHSE)执行的功能与其软件调度器完全相同(选择下一个要执行的任务‐sCPUi),并且该操作通过硬连线逻辑实现。由nHSE调度器通过图1中所示的en_pipe_sCPUi硬件信号完成从一个sCPUi到另一个sCPUi的切换,无需保存寄存器或清除流水线寄存器内容。
考虑到系统时间约束,由硬件实时操作系统(HW‐RTOS)管理的任务与基于软件的内核情况下的任务具有相同的特性。与软件解决方案不同,通过硬件实现,任何中断都具有相同的响应时间。此外,本文提出的解决方案还可以根据中断所关联任务的优先级,为中断提供静态或动态优先级。这些优先级由mrPRIsCPUi寄存器确定(见图2),这些寄存器存储了对应sCPUi的优先级,其中i = 1至n −1。
速率单调或最早截止时间优先抢占式调度算法可以通过nHSE模块,结合集成的mrTEVi定时器和硬件触发任务来实现。

用于实现中央处理器数据路径中的程序计数器、寄存器文件和流水线寄存器的资源数量与所实现的半处理器(sCPUi)[7]的数量成正比。与传统的处理器架构相比,在传统架构中,任务上下文切换需要将寄存器保存到堆栈上,从而导致抖动效应,而基于硬件实时操作系统(nMPRA+nHSE)的任务上下文切换可以在一个时钟周期内完成,并且调度器对外部事件的响应可在1.5个周期后实现。
任何sCPUi特定资源的激活或停用均可通过en_pipe_sCPU0至en_pipe_sCPUn-1信号完成,如图3所示。中央处理器使用IP块存储器生成器8.3(版本1)从片上存储器中获取每条指令,并生成对应的数据路径控制位。对于被激活的sCPUi,这些控制位随着指令经过各个流水线阶段,并设定处理器的实际操作。硬件中的冒险检测和转发模块可确保该硬件加速流水线处理器在存在数据、结构及控制冒险时仍能高效且正确地运行。对于每个流水线阶段,硬件会检测该阶段是否需要仍在流水线中的数据,并判断数据是否可以转发,或是否必须暂停流水线。
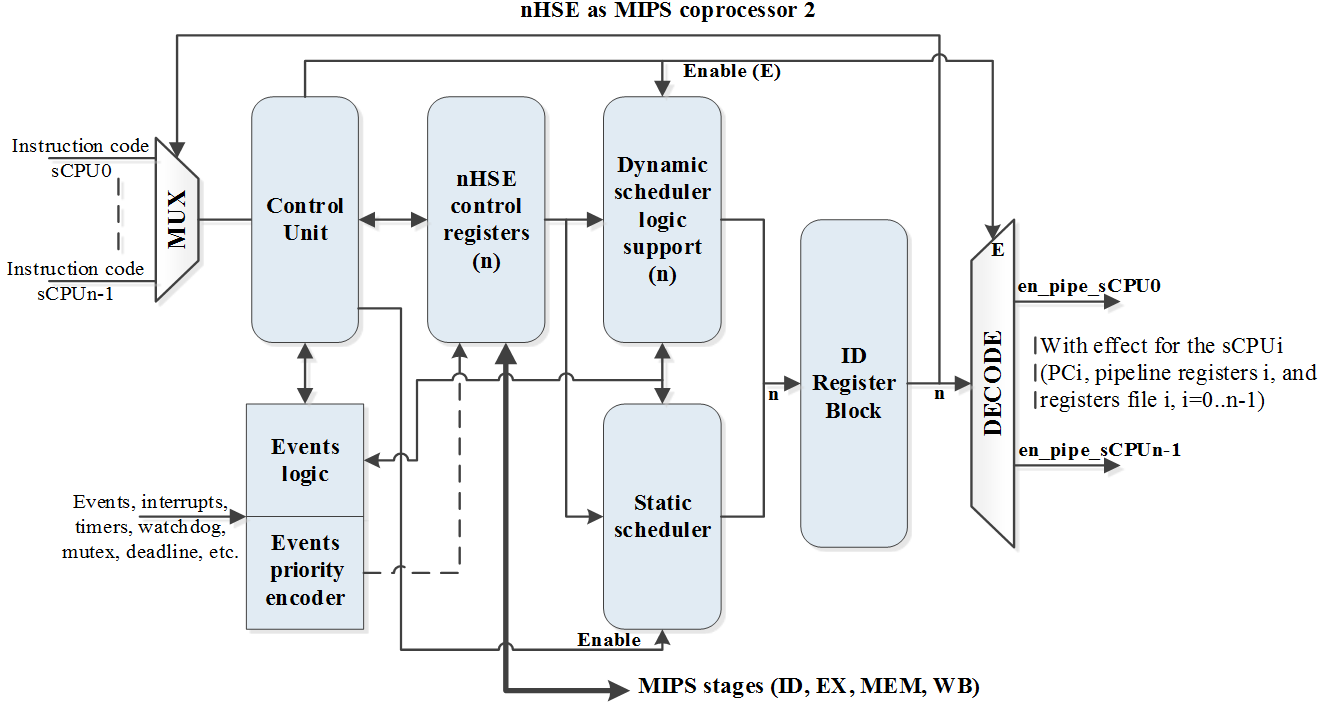
MIPS32 COP0 是允许中断、陷阱、系统调用和其他异常的处理器管理单元。它能够区分用户模式和内核模式,提供状态信息,并可覆盖程序流程。
所提出的处理器本身不包含虚拟内存。然而,COP0的子集符合MIPS32标准。顶层MIPS32处理器表示根据硬件设计图对硬件实时操作系统处理器的各个功能模块(包括硬件调度器模块)进行实例化和连接。数据存储器控制器负责处理处理器对数据存储器的所有读写请求。
所有数据访问(无论是大端、小端、字节、半字、字或非对齐传输)都被转换为通过32位总线向数据存储器发出的简单读写命令数据总线,其中读取命令为1位,写入命令为4位,对应32位字中的每个字节各占1位。数据和指令存储器接口模块通过四步握手协议提供对IP模块内存的访问。
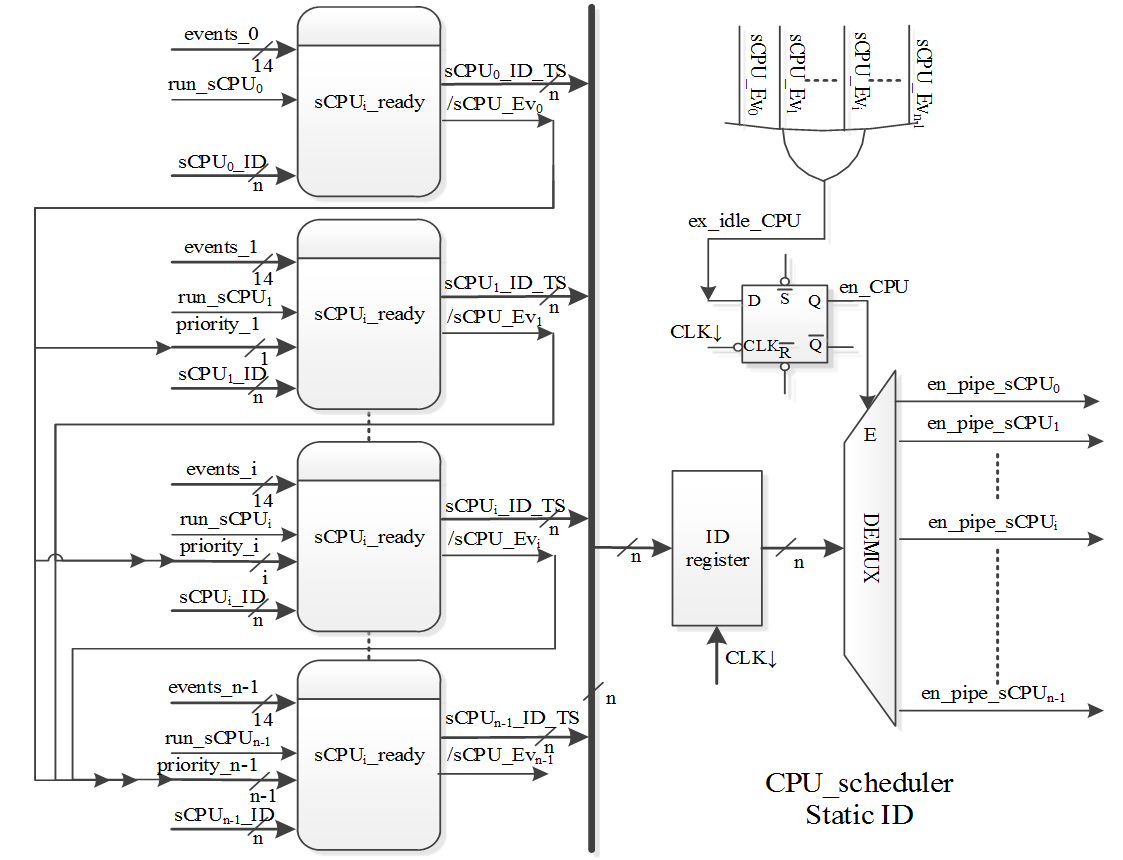
为了验证硬件加速RTOS,我们考虑了以下性能测试:任务切换以及事件(包括中断)响应抖动、事件继承其所关联任务的优先级、多事件的并发同步、使用编码器和陷阱单元处理事件(也适用于中断)的优先级排序、静态与动态任务调度,以及实时操作系统的接口函数。硬件调度器是一个有限状态机(FSM),其输入信号包括中断、截止时间、看门狗定时器、互斥量、消息和自支持执行。每个sCPU都有一个唯一标识符(ID),该标识符为从0到 n − 1的整数。当在crTRi寄存器级别发生多个中断或已验证事件时,实现事件优先级编码的硬件模块将为附加到 sCPUi的最高优先级中断生成相应的编号(见图3)。实时事件处理单元为静态和动态调度器提供使能信号,硬件产生的输出即为sCPU的激活信号。在任意时刻仅有一个此类输出信号处于有效状态(见图3,oi ≡ en_pipe_sCPUi)。
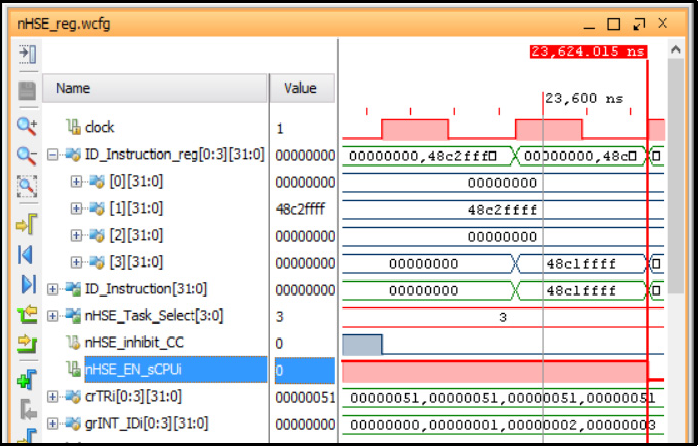
如图6所示,四个sCPUi的资源复制由ID_指令_寄存器[3:0]流水线寄存器表示。通过Vivado仿真器,可以观察到在实时事件处理模块层级设计的控制和监控寄存器。
通过nHSE_任务_选择(ID_sCPUi) 和 nHSE_使能_sCPUi(en_sCPU0‐en_sCPUn-1)信号,硬件调度器模块控制所有sCPUi的执行状态。nHSE_禁止_上下文切换信号可以在某些关键情况下(如原子指令)禁止上下文切换。因此,指令wait Rj是该指令的一部分专门用于集成硬件调度器运行的组。该指令将Rj寄存器的内容移至crTRi控制寄存器,从而在硬件调度器级别验证任务i的预期事件。如果在执行wait Rj指令时至少有一个事件处于激活且有效状态,则该任务不会被挂起。
硬件调度器支持互斥量和运行时统计,并可为每个任务定义和处理受保护的内存块;此外,还可实现任务间同步和通信机制,用于任务之间的数据通信。
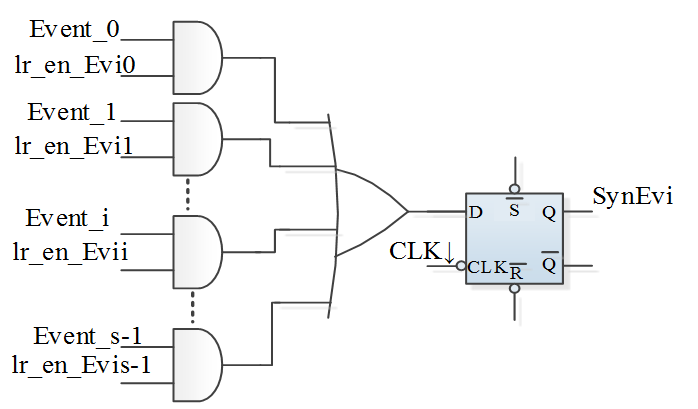
这些机制的硬件实现可确保实时任务具有极短的锁定时间,从而满足分配给任务的截止时间。为了在nHSE层面实现任务间同步与通信机制,我们设计了一个包含寄存器和组合逻辑的硬件模块。该电路可自动生第一个空闲事件的地址(从0开始)。为了避免在事件寄存器文件 (ERF)中搜索消息源时消耗大量时钟周期,搜索基于内容可寻址存储器(CAM)原理进行。当事件被激活时,该机制表现出一种行为;而当目标任务读取该事件以确定发送者及消息内容时,则表现出另一种行为。在此背景下,硬件加速RTOS能够在执行硬实时任务的同时实现上述机制,从而提高静态或动态调度器实现的效率。
三、基于硬件抢占式调度器的实际结果
本节描述了为测试和验证基于xc7vx485tffg1761‐2现场可编程门阵列可重构系统、美国加利福尼亚州圣何塞赛灵思公司(Xilinx, Inc., San Jose, CA, USA)的Vivado 2018.2设计套件以及英国斯托尼茨 Pico科技公司(Pico Technology, St Neots, U.K.)的PicoScope 2205MSO示波器所提出的硬件实时操作系统而执行的操作。
A. 功能、设置和性能在 nMPRA+nHSE
所提出的架构基于资源倍增技术。有关专用于硬件调度器的指令集的详细描述,请查阅nMPRA规格文档。基于当前的技术发展,与[6]中描述的版本相比,当前提出的处理器实现基于Verilog HDL [8],[9], Vivado 2018.2开发环境以及Xilinx VC707开发套件。
如图6所示,四个sCPUi的资源复制由ID_指令_寄存器[3:0]流水线寄存器表示。通过Vivado仿真器,可以观察到在实时事件处理模块层级设计的控制和监控寄存器。通过nHSE_任务_选择(ID_sCPUi) 和 nHSE_使能_sCPUi(en_sCPU0‐en_sCPUn-1)信号,硬件调度器模块控制所有sCPUi的执行状态。nHSE_禁止_上下文切换信号可以在某些关键情况下(如原子指令)禁止上下文切换。因此,指令wait Rj是该指令的一部分专门用于集成硬件调度器运行的组。该指令将Rj寄存器的内容移至crTRi控制寄存器,从而在硬件调度器级别验证任务i的预期事件。如果在执行wait Rj指令时至少有一个事件处于激活且有效状态,则该任务不会被挂起。
硬件调度器支持互斥量和运行时统计,并可为每个任务定义和处理受保护的内存块;此外,还可实现任务间同步和通信机制,用于任务之间的数据通信。
这些机制的硬件实现可确保实时任务具有极短的锁定时间,从而满足分配给任务的截止时间。为了在nHSE层面实现任务间同步与通信机制,我们设计了一个包含寄存器和组合逻辑的硬件模块。该电路可自动生第一个空闲事件的地址(从0开始)。为了避免在事件寄存器文件 (ERF)中搜索消息源时消耗大量时钟周期,搜索基于内容可寻址存储器(CAM)原理进行。当事件被激活时,该机制表现出一种行为;而当目标任务读取该事件以确定发送者及消息内容时,则表现出另一种行为。在此背景下,硬件加速RTOS能够在执行硬实时任务的同时实现上述机制,从而提高静态或动态调度器实现的效率。

时刻T2表示执行0xC8030000指令(参见表I),该指令在时间T1从内存中提取。结果是将数据存储器中的字0 × 8400ffff复制到全局寄存器中grERFi。字 0 × 8400ffff (32’b1_00001_00000_00000 1111111111111111) 表示从 sCPU1(标识符_源 = 00001)向 sCPU0(标识符_目标 = 00000)发送消息 _0000011111 的操作。由于该消息从优先级较低的 sCPU1 半处理器发送至具有更高优先级的 sCPU0,因此该操作涉及由 T3 标记的 sCPU1 与 sCPU0 之间的上下文切换。crEVi[0]= 0 × 00000040控制寄存器指示调度器发生了消息事件,该事件通过寄存器 crTRi [0]= 00000071 中对应的位进行验证。grEv_Select_sCPU= 6 记录了由 sCPU0 执行的任务0 处理任务间通信事件的事实。此指令的执行是不可分割的,因此在此期间如果发生更高优先级的事件,其执行最多可能延迟三个时钟周期。
从架构角度来看,同步和通信机制的实现基于原子指令,确保了卓越的性能。
本文提出的实验结果展示了一种动态硬件调度器的实际实现。此外,基于本研究工作,已有若干文章发表在期刊和国际会议上,提出了改进实时事件处理模块的方法。因此,本工作提出了一种完整实现,包括对硬件实时操作系统 (HW‐RTOS)的进一步改进以及增加调试端口。
硬件调度器负责以下操作:确定哪个任务被选中进入运行状态,并进行相应的上下文切换;中断挂接;管理每个独立的sCPUi所使用的时钟周期,统计空闲时钟周期,并管理已执行任务的两个时间限制;在相应的sCPUi时间段到期时,将任务从接收状态切换到就绪状态。
图8展示了通过修改ID寄存器中存储的sCPUi_ID_TS信号来表示的与时间相关的事件(参见图5)。在此情况下,已设置以下sCPUi时间间隔:mrTEVi[0]= 32’h0C1F6CE0,mrTEVi[1]= 32’h0FF00000,mrTEVi[2]= 32’h12010000,并且mrTEVi[3]= 32’h170F0000。因此,调度器从处于就绪状态的任务中选择优先级最高的任务进行执行。换句话说,被选中执行的任务是已准备好运行且优先级最高的任务。处于接收状态或被抢占状态的任务不被视为可执行任务。如果在执行wait Rj指令时,至少有一个事件处于激活状态且该任务未被挂起。定制架构中的硬件调度器模块会持续监控所有动态附加到sCPU的事件。实时事件处理模块负责调度执行任务,同时考虑所有处于就绪状态任务的优先级和状态。
B. 结果与验证测量
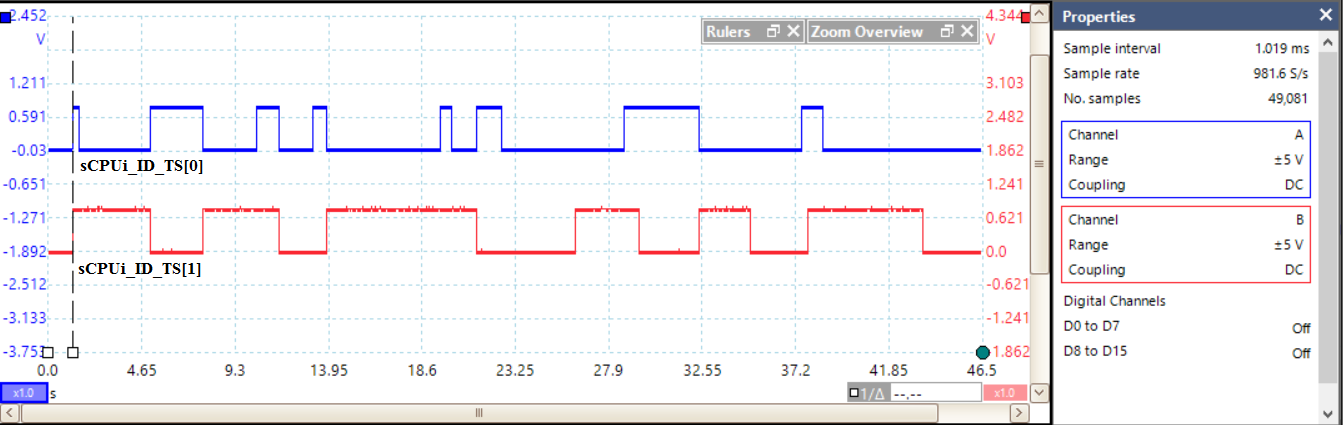
在验证测试中,使用PicoScope 2205MSO示波器来测量抢占式调度器处理来自Virtex‐7开发套件上按钮产生的外部异步中断时的抖动。我们测试了任务上下文开关抖动、任务间通信事件性能以及对外部事件的延迟,因为这些参数对于具有硬实时要求的任务执行至关重要。
在处理外部异步中断的情况下,基于实时事件处理模块和抢占式硬件RTOS调度的实际测量,已获得仅280.9 ns的响应时间。
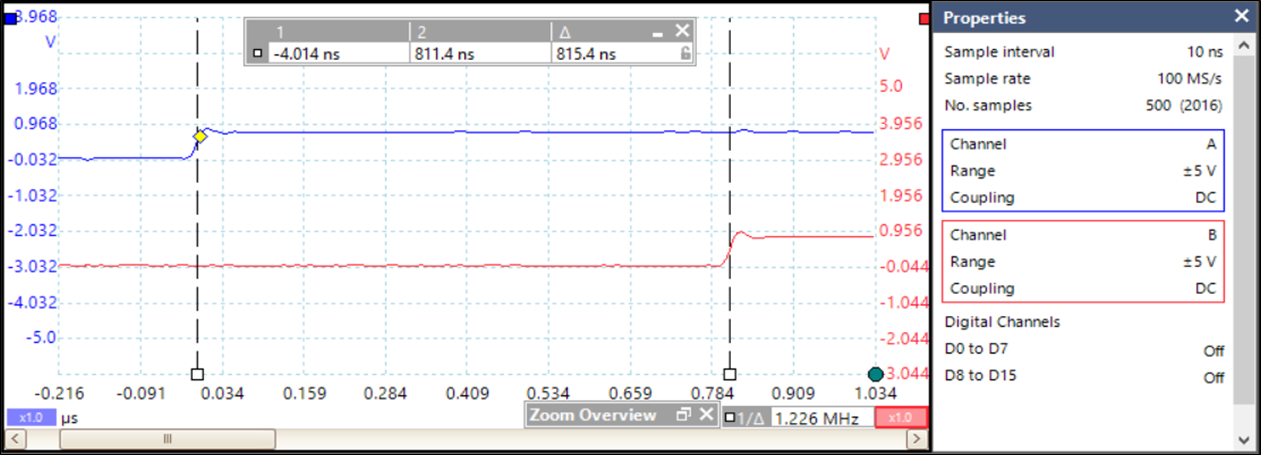
实际测量结果验证了通过Vivado 2018.2环境[10]获得的波形以及创新的实时硬件调度器的性能。还进行了其他验证测试,包括任务间同步和通信机制,并考虑了如 μC/OS‐II等实时操作系统软件。在本测试中,我们使用了 STMicroelectronics的Keil MCBSTR9评估板,该板包含STR912FAW44 ARM处理器(ARM966E‐S 32位 RISC微控制器)。在nMPRA测试中,发送消息时,sCPU1设置现场可编程门阵列[的一个引脚,如图9(a)]中的光标1所示;当消息被接收时,sCPU0设置另一个引脚,由光标2捕获。由于硬件调度器是基于优先级的抢占式调度器,在发送消息时,实时调度器一旦退出不可中断周期 (nHSE_inhibit_CC= 0),便会立即暂停sCPU1,并执行上下文切换以运行与相应处理程序关联的sCPU0代码。
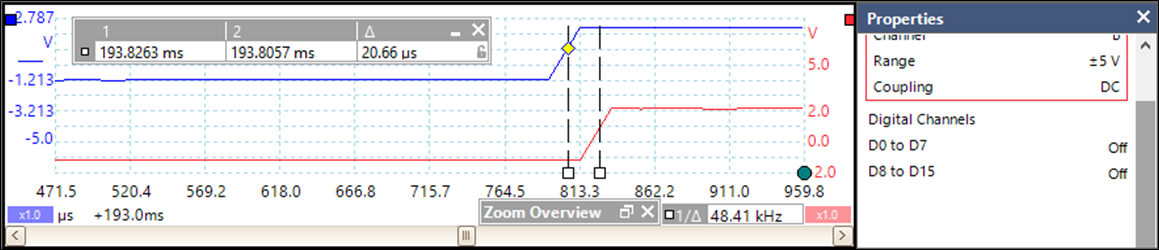
由于在grERFi全局寄存器中的关联查找是通过硬件实现的,因此跳转到陷阱单元得以完成仅需两个时钟周期。因此,如图9(a)所示,基于硬件加速 RTOS的应用响应时间为815.4ns,即在33 MHz下为 26.9个时钟周期。图9(b)显示了当使用 μC/OS‐II和五级流水线ARM966E‐S微控制器、频率为25 MHz时的响应时间 Δt= 20.66 μs。
该项目并非旨在描述流水线数据路径的完整解决方案,而是旨在验证所提出的架构及集成硬件调度器在可重构系统中的实践实现。
本节中进行并展示的测试证明了所提出概念在嵌入式系统中的适用性,这些系统需要更高的计算能力来运行实时应用,同时必须确保极低的响应时间,以保证任务执行的实时特性以及最坏情况执行时间(WCET)系数的计算。
表II 展示了所提出的处理器在三种版本下的片上系统资源需求,分别对应4、8和16个sCPUi/互斥锁/任务间通信事件。所提出处理器的性能由资源倍增构成,因此 nMPRA4、nMPRA8和nMPRA16标签分别对应4、8和 16个sCPUi的实现。grMutex4和grERF4标签对应具有四个互斥锁和四个消息通信功能的中央处理器版本寄存器。实现顺序和组合元件所需的资源不会随着 nMPRA sCPUi的倍增而成比例增加。所提出处理器的性能不依赖于处理能力,而是依赖于上下文切换速度和调度算法的执行速度。该架构满足实时系统的要求,具有低内存与低功耗的特点。在硬件中实现任务控制块(TCB)、每个sCPUi级别上的事件优先级以及互斥锁或消息的关联查找所需资源绝不可忽视,这些因素共同构成了赛灵思 xc7vx485tffg1761‐2现场可编程门阵列电路的整体资源消耗。由于不包含任务间同步与通信机制的处理器实现是不现实的,因此本文也包含了这些机制的实现资源需求,以及静态与动态嵌入式调度器的实现。
四、相关工作
本节分析并比较了多个实时操作系统实现,包括实时调度领域提出的项目。表III展示了不同实时操作系统及其所提供功能的比较。
如今的实时操作系统实现了多种常见功能,例如中断和任务的动态优先级、多事件处理以及基于优先级的嵌套中断。
实时操作系统(RTOS)特有的功能,如任务调度、同步和任务间通信机制,在实时系统(RTS)中起着特殊作用。因此,以下是一些在改进RTOS功能和硬件调度器方面具有代表性的项目。本文将重点介绍与所分析架构的调度器相关的理论和实践方面,以及实时特性系统的特征。
Akesson et al.[17]提出了一种名为predator的新处理器。该架构具有高度可预测性,可成功应用于嵌入式系统,甚至实时应用中。所提出的处理器采用具有可预测行为的多核结构、可分析缓存以及编译器控制的内存管理。作者实现了多核系统特有的可预测机制。为了实现实时多核架构,作者在核心、缓存和内存之间采用了交叉开关作为通信机制[18],[19]。因此,为确保对共享资源的独占访问,将属于不同执行线程的代码和数据分配到同一内存时,需要设计一个实时调度器。
架构已发展为具有推测性/乱序执行和动态调度的流水线装配线,而内存则采用多级分层组织,并包含转译后备缓冲区(TLB)。在这种情况下,计算现代处理器的最坏情况执行时间系数需要付出相当大的努力。
[20]中提出的解决方案提出了一种称为精确计时机器(PRECISION TIMED MACHINES, PRET)的CPU架构。PRET实现的时序行为可保证更可预测的执行。为此,在设计阶段会出现许多与内存层次结构、流水线技术、功耗、编程语言以及实时任务调度相关的约束。
实时操作系统的开销是指处理器执行内核函数所消耗的时间,例如上下文切换、将任务插入队列、启动执行中断处理程序[21],更新数据结构(如任务控制块TCB和信号量控制块SCB),或实现任务间同步与通信机制。这些功能的执行时间相较于任务的执行时间周期非常短;因此,即使在实时内核验证的最终测试中,这种CPU开销通常也在调度分析中被忽略。在[22]中介绍的PTARM项目通过五级流水线实现来隔离每个执行线程。为了实现卓越性能,必须至少有四个线程处于活动状态,以通过轮转调度使处理器保持完全占用。当流水线中交错的线程少于四个时,会损失大量的CPU周期。
与其他主流架构相比,所提出的硬件调度器模块将通过仿真以及基于FPGA技术的实际实现,实现对外部刺激的极佳响应时间和可控的确定性。本文介绍了与所提出架构最接近的当前成果和可比实现,并进行了分析。基于 nMPRA + nHSE概念在硬件调度器实现中获得的实际结果,保证了该研究成果的科学贡献及其相对于国内外技术水平的相关性。
V. 结论与未来工作
本文提出了一种针对与同一任务(sCPUi)关联的中断和事件进行硬件优先级排序的可靠解决方案。通过实时事件处理模块,最小化了外部异步中断和任务间通信事件的响应时间。因此,如果基于优先级的调度器选择相应的 sCPUi执行,高优先级事件的处理可在其发生后的下一个时钟周期立即开始。理论上的、实践上的和实验性贡献如下。
1) 将文献中最具代表性的处理器架构与本文提出的处理器进行比较。
2) 研究将实时事件处理单元集成到 MIPS32架构的COP2中(选择要在COP2中实现的指令,对局部、全局、控制和监控寄存器进行分组,以便根据处理器规范进行访问)。考虑采用多个片上流水线寄存器组以实现极快的上下文切换。
3) 为硬件调度器增加新的寄存器,以便在现场可编程门阵列(FPGA)中实现(这些寄存器用于存储由sCPUi关联并处理的事件的标识符)。
4) 通过使用优先级编码器和利用陷阱单元直接传输至事件处理程序,提高对多个同时发生的事件和多个同时发生的中断的灵活性和响应时间。
该硬件调度器的实现可以通过优化其基于的有限状态机来改进;中断系统和异常处理系统也可以得到改进。定制CPU该实现由于任务上下文的完全隔离,提供了高度的使用安全性,从而消除了数据损坏的可能性。然而,新处理器通过硬件实现的功能设计确保了关键任务执行的确定性,这得益于为其提供保障的优先级机制。
关于该领域当前的研究状态,可以通过提供简单的指令缓存和单周期指令获取来改进该系统。本项目的一个未来目标是构建一种创新的多核架构,扩展有关CPU数据路径资源倍增以及nHSE抢占式调度器硬件实现的概念。

















 1169
1169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









