



阅读本文大概需要 3 分钟。
昨天的文章「能做的只有这么多了」我真的惊呆了,我必须抱歉的说一开始我并没有这么乐观,我只是抱着能帮一点是一点的心态,没想到这么多人赞赏,截止目前已经有 1000 多人赞赏,算上阅读量,平均每 5 个人 就有 1 个人赞赏,总额已经筹得将近 14000 块,我真的很欣慰,真心的,为你们同意我的价值观,为你们是一群善良的人感到欣慰。

这件事再次刷新了我的三观,充分证明大多数人内心深处都是善良的,只是我们太容易妥协,太容易忘却,太容易浮躁,太容易迷失,好在通过这件事让大家引起了共鸣。
不管是现实还是网上大家遇到类似的事情太多了,受骗上当也太多了,很多人已经麻木了,不再选择相信,包括我自己也是,我在地铁口或者广场碰到一些乞讨的我一般都视若不见,因为我也受骗过,好在我并没有因此而丧失那点仅有的善良。这次很多人留言最多的是「我相信张哥的判断,一定是真的」。而事实证明我的判断是正确的,评论里有他同学的留言证明了此事,更让我没想到的是王同学的班主任特地给我留言专门道谢,还给我发了一张截图:
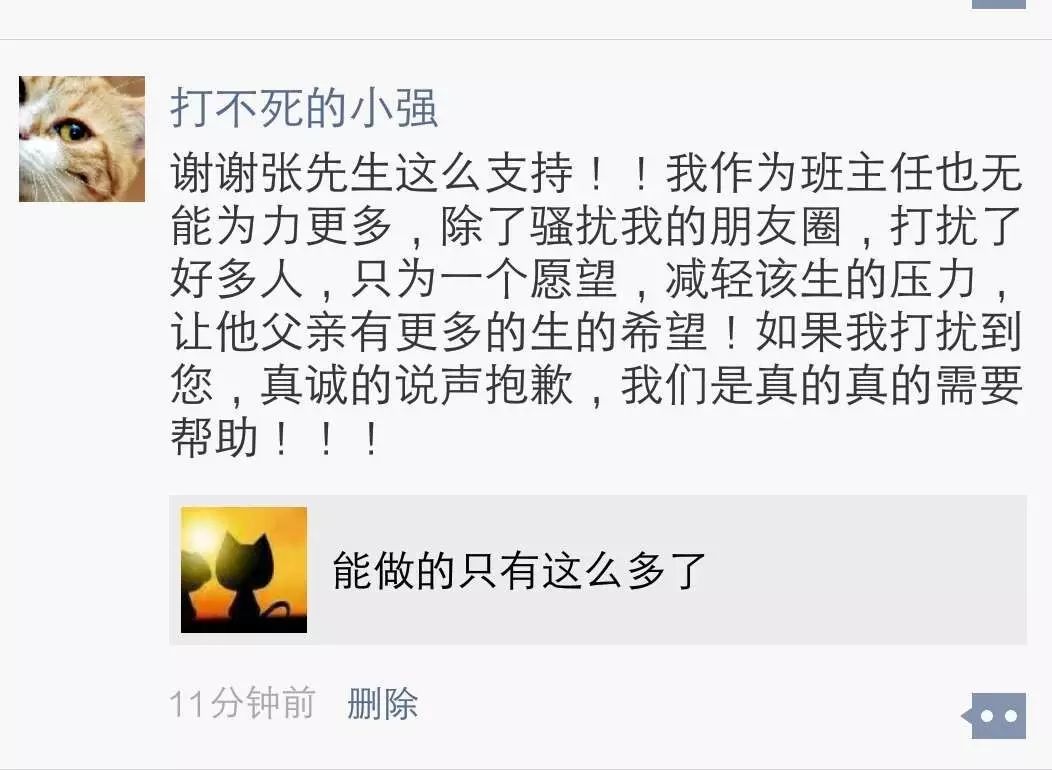
所以大家更不用担心了,这件事肯定是真的!
有一句读者的留言我觉得说的非常好:这世界上有六十多亿人,每天都会有人需要帮助,自己没看到也就罢了,自己刚好点开这篇文章看到了就随手帮助下,不求别的,只求心安!
是的,心安两个字说的轻松,但是真正能做到的又有多少!
这些赞赏的人跟王同学素昧平生,只凭我的一篇文章很多人就 50、100 的赞赏,我真的为你们相信我说句感谢,也替王同学对你们说句感谢。我说了赞赏金额根据自身情况尽力就好,但是我觉得这种情况支援 5 块钱已经算是最小额度了,所以特意为此改了赞赏数字。
之前很多人赞赏支持我 1 块, 2 块的不在少数,我从未因为你们赞赏的少而嫌弃你们,所有的回复都是公平对待,只要赞赏都是对我的支持与认可。但是今天我要说一句,所有赞赏的都是有爱心之人,但是这次还赞赏 1块,2 块的未免有点小气,支援个 5 块应该没什么影响吧?现在总额度离 15w 还有不少差距,所以这里能多帮助一点是一点,所以呼吁大家赞赏最起码能从 5 元起步。
我们这里只能帮助一次,之后的花费我相信一定会更多,后面的路会更难走,所以我跟王同学做了一些交流,告诉他一些别的众筹平台,希望他不要放弃,多做点尝试,能筹钱的每个渠道都要去尝试下,有一丝机会都要尽全力去争取!
最后,我再呼吁下大家,如果还没有赞赏的,那么烦请去这篇文章「能做的只有这么多了」赞赏下,如果已经赞赏过了,就不必重复赞赏了,毕竟这事不是你一个人能解决的,还是要靠更多人的力量!
另外,我还能再多做一点,比如写这篇文章让更多的读者看到,如果大家愿意,不妨随手点击下留言区上方的广告,有效点击一次就可以了,广告所得我也会一并捐给王同学,虽然杯水车薪,但是能多做点就尽力去做!
技术固然很重要,但是技术不是全部,面对浮躁的社会,希望这里还可以有一盏明灯!
PS:我媳妇这两天预产期,我在随时做准备,这是在我的宝宝出生前做的最有意义的一件事了,所以最近可能没太多时间更新技术文章,还请大家谅解。另外,为了多赚点奶粉钱,下周接了两篇软文推广,绝对正规,请大家理解下,我会在评论明确说明的,如果支持就点击下,如果反感不妨直接忽略。
完成这篇文章,此时深夜 2 点。

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









