






 本文描述了在使用Spark对DataFrame进行GroupBy操作时遇到的错误,并详细记录了解决过程。通过重命名带有括号的列名,成功避免了在将数据写入HDFS时出现的AnalysisException。
本文描述了在使用Spark对DataFrame进行GroupBy操作时遇到的错误,并详细记录了解决过程。通过重命名带有括号的列名,成功避免了在将数据写入HDFS时出现的AnalysisException。
今天使用spark对一个dataframe中的数据以某一个为主键做groupby进行求和,数据类似如下:
scala> userDF.show
+---------+--------+
| userid | count |
+--------+---------+
| 11111111| 102|
| 2222222| 97|
| 3333333| 10|
| 11111111| 24|
+----------+-------+
scala> val dataFrame = userDF.groupBy("userid").sum("count")
dataFrame: org.apache.spark.sql.DataFrame = [uid: string, sum(count): bigint]
scala>dataFrame.repartition(5).write.mode(SaveMode.Overwrite).parquet("hdfs://xxx.xxx.xxx.xxx:8020/userdata/userdata_20181017")
结果出错了,报了下面的错(org.apache.spark.sql.AnalysisException: Attribute name "xxxxx" contains invalid character(s) among ",;{}()\n\t=".):
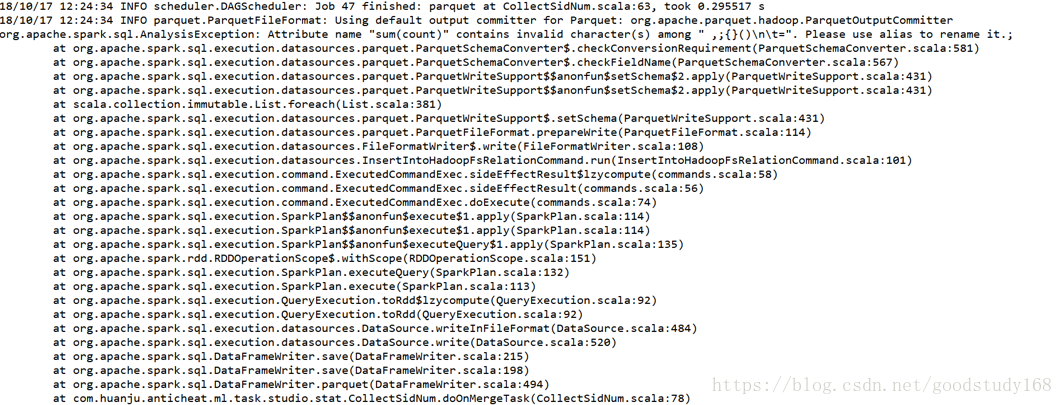
想来想去,dataframe的数据没问题,根据报错分析下,提示有特殊字符,那在dataframe的表头仅有“sum(count)”,这里面包含有括号,于是想着对dataframe表头进行重命名,代码如下:
scala> val dataFrame = userDF.groupBy("userid").sum("count").toDF("userid", "count")
dataFrame: org.apache.spark.sql.DataFrame = [uid: string, sum(count): bigint]
scala>dataFrame.repartition(5).write.mode(SaveMode.Overwrite).parquet("hdfs://xxx.xxx.xxx.xxx:8020/userdata/userdata_20181017")
结果数据能正确写到hdfs上了。

















 1158
1158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









