



seq2seq模型
定义
sequence to sequence模型是一类End-to-End的算法框架,也就是从序列到序列的转换模型框架。
应用场景
机器翻译
聊天机器人
文本摘要生成
图片描述生成
诗词生成
故事风格改写
代码补全
思路
seq2seq可以说是基于RNN提出的生成序列的模型,一般来说,对于基础的RNN我们可以输入一段序列数据得到一个输出结果,而seq2seq则可以输出一段序列结果。seq2seq分为encoder(编码)和decoder(解码)两个过程:
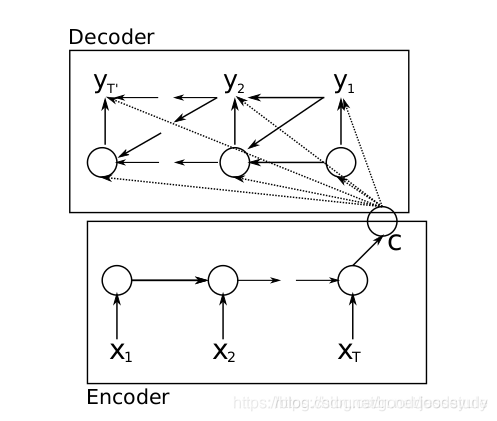
输出C称为语义向量,用来表示输入的整个序列的含义,得到语义向量之后,就来到解码过程,把语义向量输入到另一个RNN,RNN基于语义向量再逐个输出新的序列:
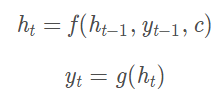
可以这样理解,对于这种结构的seq2seq,它的每一个输出,由整个输入句子的意思、以及之前的输出共同决定,比如现在要把句子"today is a good day"翻译成中文,我们把语义向量输入到RNN得到第一个输出"今天",然后第二个输出是由"今天"以及语义向量共同决定的,以此类推,其实这还是RNN的正常输出。
引入注意力机制
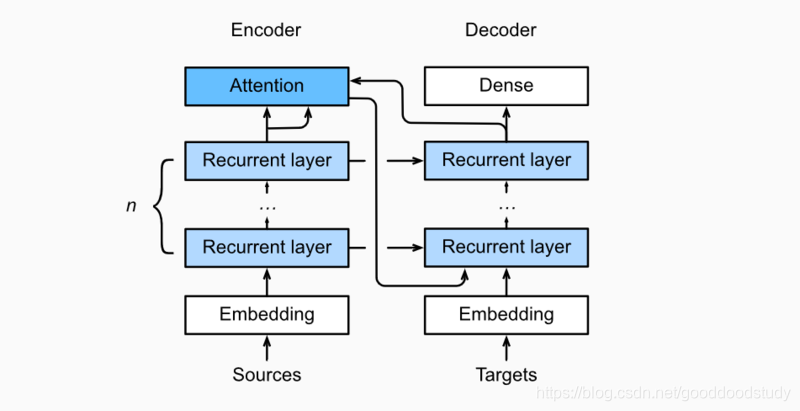
将注意机制添加到sequence to sequence 模型中,以显式地使用权重聚合states。下图展示encoding 和decoding的模型结构,在时间步为t的时候。此刻attention layer保存着encodering看到的所有信息——即encoding的每一步输出。在decoding阶段,解码器的 t 时刻的隐藏状态被当作query,encoder的每个时间步的hidden states作为key和value进行attention聚合. Attetion model的输出当作成上下文信息context vector,并与解码器输入 Dt 拼接起来一起送到解码器:
import sys
sys.path.append('/home/kesci/input/d2len9900')
import d2l
解码器代码实现
定义attention_cell,embedding,以及dense,全连接层,将最终解码的num_hiddens映射到词表
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqAttentionDecoder, self).__init__(**kwargs)
self.attention_cell = MLPAttention(num_hiddens,num_hiddens, dropout)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.LSTM(embed_size+ num_hiddens,num_hiddens, num_layers, dropout=dropout)
self.dense = nn.Linear(num_hiddens,vocab_size)
输出为outputs的一个转置
outputs = self.dense(torch.cat(outputs, dim=0))
return outputs.transpose(0, 1), [enc_outputs, hidden_state,
enc_valid_len]
训练和预测
将model进行训练,500轮,可以看到loss降低一直降到0.023,收敛,时间也比较慢。
训练
d2l.train_s2s_ch9(model, train_iter, lr, num_epochs, ctx)
epoch 50,loss 0.104, time 54.7 sec
epoch 100,loss 0.046, time 54.8 sec
epoch 150,loss 0.031, time 54.7 sec
epoch 200,loss 0.027, time 54.3 sec
epoch 250,loss 0.025, time 54.3 sec
epoch 300,loss 0.024, time 54.4 sec
epoch 350,loss 0.024, time 54.4 sec
epoch 400,loss 0.024, time 54.5 sec
epoch 450,loss 0.023, time 54.4 sec
epoch 500,loss 0.023, time 54.7 sec
预测
训练好模型之后进行语句翻译。我们将需要翻译的句子送到seq2seq模型里面进行Decoder,可以看到能够准确翻译。
for sentence in ['Go .', 'Good Night !', "I'm OK .", 'I won !']:
print(sentence + ' => ' + d2l.predict_s2s_ch9(
model, sentence, src_vocab, tgt_vocab, num_steps, ctx))
Go . => va !
Good Night ! => !
I'm OK . => ça va .
I won ! => j'ai gagné !

















 277
277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









