




本次,我们来讲解一下关于C++11的新语法,当然我们只会讲一些常见的,实用的那一部分。
前言:
我们之前大部分都是C++98的语法,从所周知,为什么叫C++98?当然是1998年发布的,所以C++11也不例外,是2011年发布的,对于C++语法发布的故事还挺精彩的,有兴趣的可以自行去了解了解。
C++11的优势
C++11能更好地用于系统开发和库开发、语法更加泛华和简单化、更加稳定和安全,不仅功能更强大,而且能提升程序员的开发效率。这也是为什么我们现在来讲它,当然目前为止,C++版本更新到了有C++14,C++17,C++20,当然我们为了可能随着时代的发展,也是需要学习它的,但还是得过上那么一段时间,普及率高一些再学习它,现在就先学习C++11的语法。
好了,现在正式开始讲解:
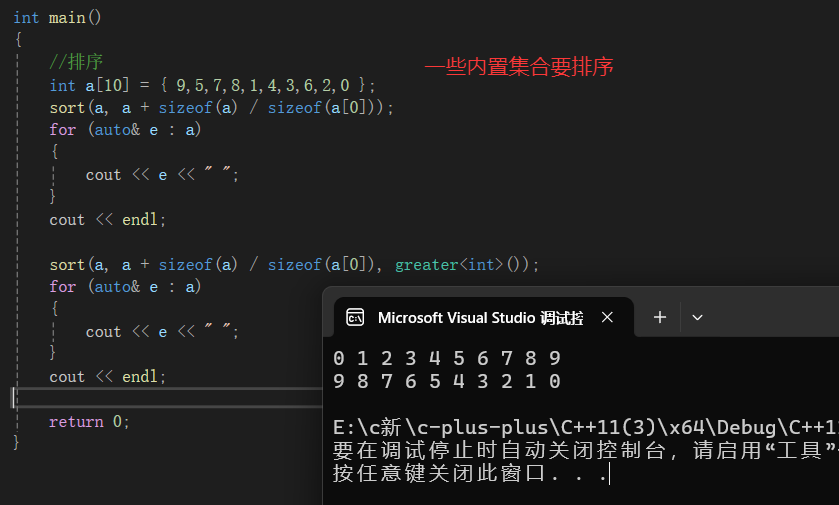
统一的列表初始化
1.{}的初始化
我们知道C++98是支持上面的初始化方式的。
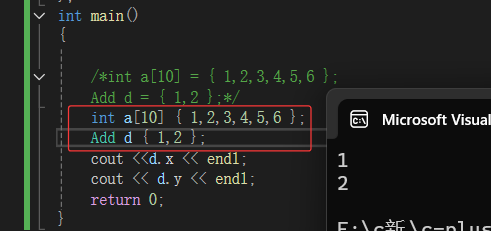
C++11扩大了用大括号括起的列表(初始化列表)的使用范围,使其可用于所有的内置类型和用户自定义的类型,使用初始化列表时,可添加等号(=),也可不添加。
但是,如果不加=,总觉得怪怪的,不太习惯,但是如果以后看到此类型的写法,也是正确的。
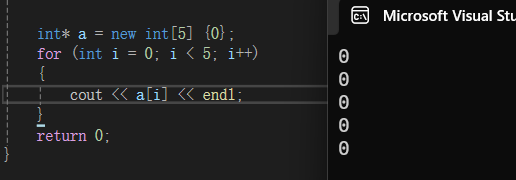
C++11中列表初始化也可以适用于new表达式中
创建对象时也可以使用列表初始化方式调用构造函数初始化
比如说之前我们写过的日期类时初始化日期,但是这里就不展示了。
注意:
而且这个特性还特别易混:(所以说我们还说按照C++98的写吧)
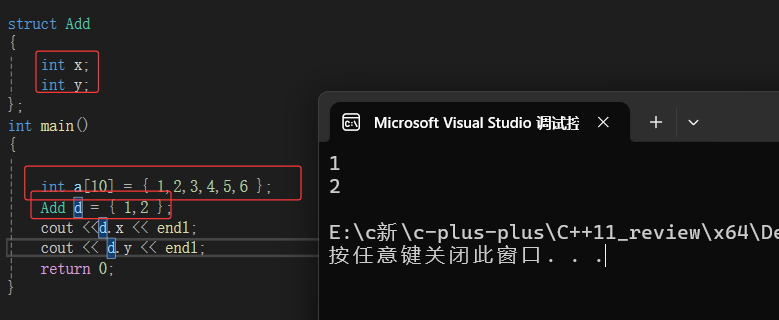
eg:vector<int > a={1,2,3,4,5,6};
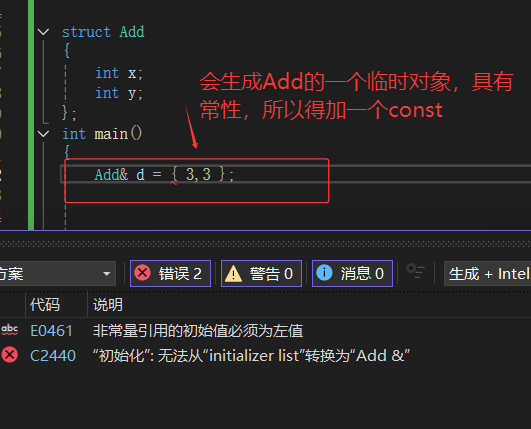
Add a={1,2};
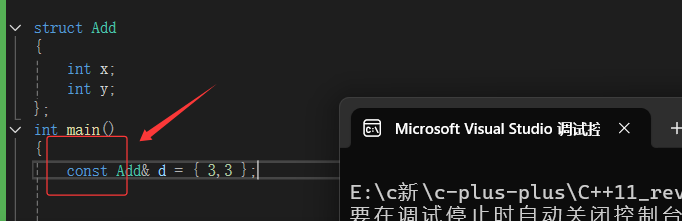
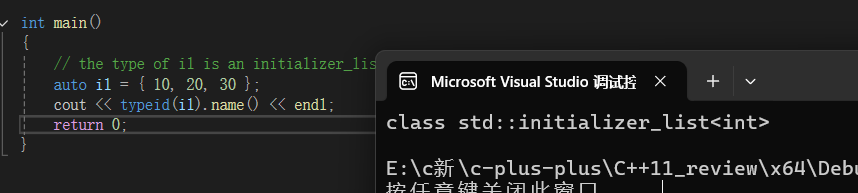
initializer_list
此类型用于访问 C++ 初始化列表中的值,该列表是 const T 类型的元素列表。
此类型的对象由编译器从初始化列表声明中自动构造,初始化列表声明是用大括号括起来的逗号分隔的元素列表:
std::initializer_list是什么类型:
ps:typeid用于获取类型信息,其name成员主要用于查看类型名称,一般不用于操作。
std::initializer_list一般是作为构造函数的参数,C++11对STL中的不少容器(vector,list等等)就增加std::initializer_list作为参数的构造函数,这样初始化容器对象就更方便了。也可以作为operator=的参数,这样就可以用大括号赋值
![]()

使用大括号对容器赋值
vector<int> v={1,2,3};
v={4,5,6};
那么我们发现vector上也支持了这玩意,那我们来想想,它是如何来支持的?如何让我们之前实现的vector也具有这个功能?

在stl源码中:

vector(initializer_list<T> lt)
{
reserve(lt.size());
for (auto e : lt)
{
push_back(e);
}
}
vector<T>& operator=(initializer_list<T> l)
{
swap(v);
return *this;
}
声明方式的简洁:
C++11提供了许多简洁的声明方式,在模板中尤其显示处来。
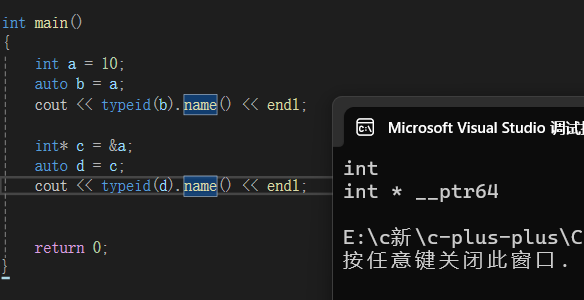
1.auto
这个是自动推导类型,我们在初学C++时就已经介绍过了,也是平时中非常常用的一个。
auto这个关键字历史:
- C语言:早期作为“自动存储期”变量的声明符,表明变量在栈上分配内存,离开作用域后自动销毁,现代使用中已很少主动写(默认不写就是auto属性)。
- C++11及以后:功能被重新定义为自动类型推导,编译器会根据变量的初始化值自动判断其数据类型,简化代码。
此外,在我们之前模拟实现各种容器的时候也知道,它在迭代器使用和范围for时也非常使用。
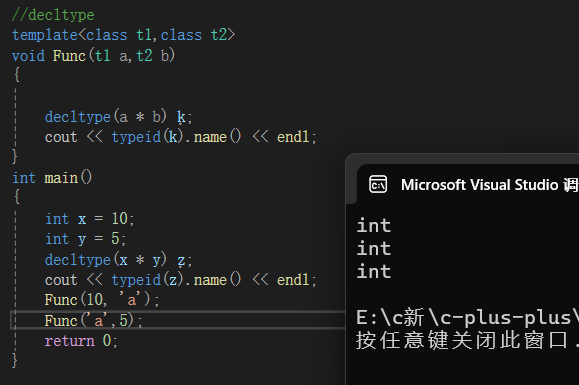
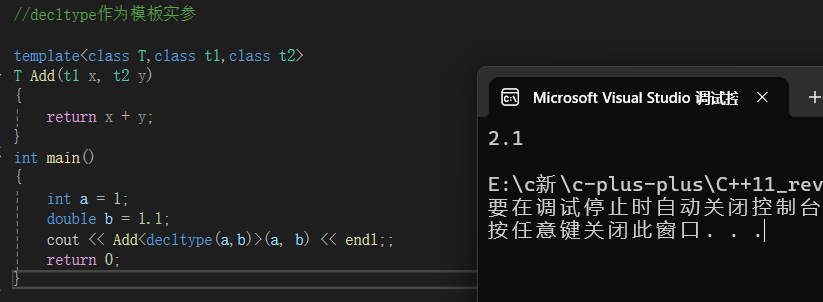
2.decltype
关键字decltype将变量的类型声明为表达式指定的类型
decltype推出对象的类型,再定义变量,或者作为模板实参
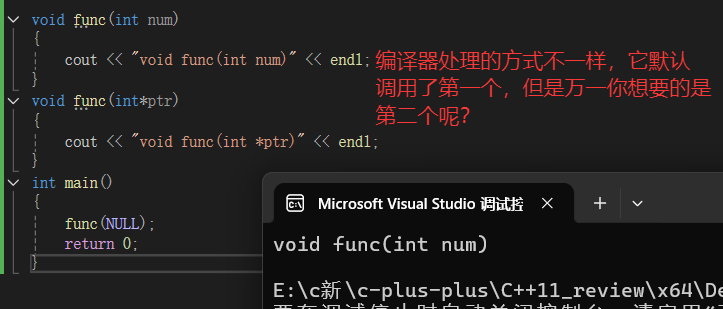
3.nullptr空指针
我们知道,在C语言中,NULL通常被定义成((void*)0),本质上是一个空指针常量,
由于C++早期中NULL被定义成字面量0,这样就可能回带来一些问题,因为0既能指针常量,又能表示整形常量。所以出于清晰和安全的角度考虑,C++11中新增了nullptr,用于表示空指针
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif
std::nullptr_t是一种特殊的类型,能够隐式类型转化为任意指针类型,包含(void*)和成员指针类型,但是不能隐式转化为整数类型。
那么有人可能会想了,什么情况下它会产生二义性?
知识点:为什么有人说尽量用const,enum,inline去替代宏呢?这里总结了几点:
主要是基于类型安全、作用域控制、调试便利性等多方面的考量,以下是具体原因:
const与宏比较:
| 名称 | - 类型安全: | - 作用域控制: | - 调试: |
| 宏 |
宏只是简单的文本替换,不具备类型信息 例如 #define PI 3.14159 ,宏 PI 没有类型,在使用时可能会因为类型不匹配引发潜在错误 | 宏的作用域规则简单粗暴,它从定义点开始直到文件结束或者被 #undef 取消定义,可能会在不期望的地方生效,导致命名冲突。 | 宏在预处理阶段就被替换掉了,在调试过程中,调试器看到的是替换后的代码,难以追踪宏的原始定义位置。 |
| const | const 常量具有明确的类型, const double PI = 3.14159; ,编译器会进行类型检查,提高代码的安全性和可靠性。 | const 常量可以像普通变量一样有明确的作用域,比如定义在函数内部的 const 常量只在该函数内有效,定义在命名空间中的 const 常量也只在对应的命名空间内有效, 便于代码的组织和维护。 | const 常量在调试时能清晰地看到其名称和类型,有助于快速定位问题。 |
| enum | enum 定义的枚举类型是有类型的,不同枚举类型之间不能直接赋值和比较,能有效避免类型错误 | enum 可以通过 enum class (强类型枚举)的方式定义,枚举值在枚举类型的作用域内,避免了命名冲突。 | (维护代码性强)enum 可以方便地添加新的枚举值,并且可以为枚举值指定特定的整数值 |
| inline | inline 函数是真正的函数,编译器会对参数进行类型检查,提高代码的安全性 | (代码可读性)inline 函数遵循函数的语法规则,具有更好的可读性和可维护性。而宏函数的语法比较特殊,尤其是当宏函数体比较复杂时,代码的可读性会变差。 | inline 函数在调试时可以像普通函数一样进行单步调试,更易于排查问题。虽然 inline 函数会在调用处展开代码,但编译器仍然保留了函数的相关信息,方便调试。 |
4.范围for
(它是我们的语法糖,很方便,但是也不要把它想成很高大上,我们之前模拟实现各类容器时讲到过迭代器后,发现它的本质是傻瓜式,即:获取iterator begin,iterator end,在遍历++罢了)
5.智能指针
(后面讲,知识点太多了,单独分享)。
STL的变化:
1.更新了array:静态数组,非类型静态数组。
对比维度 普通数组(原生数组) std::array(C++11 引入) 大小与长度获取 需手动通过 计算长度,无法直接获取 内置 成员函数,可直接、清晰获取长度(如 )array.size() 安全性 边界检查,越界访问(如下标超范围)仅导致“未定义行为”(可能崩溃或结果异常) 无 支持 成员函数做边界检查,越界时抛出 异常,更安全 赋值与拷贝 不支持直接整体赋值(如 报错) 支持直接整体赋值(如 合法) 功能扩展性 无额外成员函数,仅能通过下标访问元素,功能单一 支持多种容器通用操作(如 判断是否为空、/ 获取首尾元素),可与 STL 算法(如 )无缝配合 内存特性 内存连续存储,与 一致,无额外内存开销 内存连续存储,无额外内存开销(仅封装原生数组,不增加冗余空间) 但是,有很多人说它鸡肋:相比普通数组没解决“动态大小”核心痛点,相比更灵活的 std::vector 又显得“死板”,导致在部分场景下显得“不上不下”,用的时候体验感不好。
2.除了这个外,还更新了forward_list(单链表)。
它只支持了头插,头删:是在当前位置之后插的;尾删时必须要找前一个结点(这样效率就低了)虽然哈希桶可以用这个接口:但是它本来要实现这个功能就不复杂,所以没太大必要用它,另外,如果哈希桶用这个接口的话,迭代器的封装就不好写了。
唯一的优势:节省了一个指针(每个结点),但我们对内存空间没太注重的必要(对于当代的计算机)。
3.所有容器新增了emplace系列(这个就跟push_back的功能差不多,只是效率上高了一点点,但是到了后面,了解完了右值引用后,结合起来发现都差不多,大差不差)
虽然,,有很多人吐槽C++11,但是它还是更新出提高效率的功能的:
右值引用
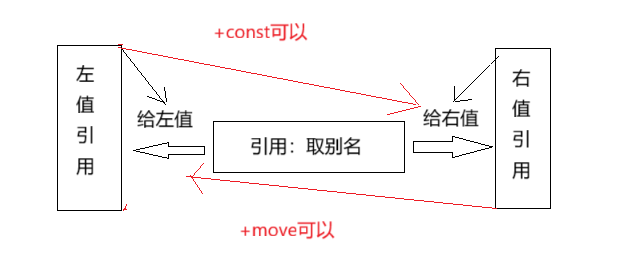
我们在之前刚开始了解C++的时候,给大家介绍过关于左值引用的使用,现在又右值引用。但是,无论左值引用还是右值引用,都是给对象取别名。
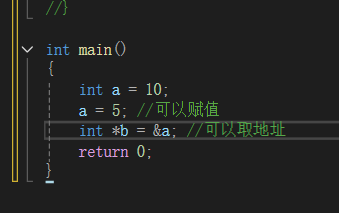
左值引用
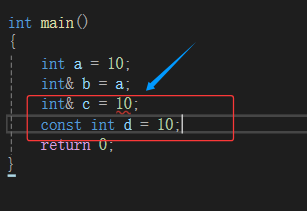
左值是一个表示数据的表达式(如变量名或解引用的指针),我们可以获取它的地址+可以对它赋值,左值可以出现赋值符号的左边,右值不能出现在赋值符号左边。定义时const修饰符后的左值,不能给他赋值,但是可以取它的地址。左值引用就是给左值的引用,给左值取别名
例子辅助:左值: int a=10; int*b=new int(1); const int c=5; 左值引用: int*& rp = p; int& rb = b; const int& rc = c; int& pvalue = *p;
什么是右值?什么是右值引用?
右值也是一个表示数据的表达式,如:字面常量、表达式返回值,函数返回值(这个不能是左值引用返回)等等,右值可以出现在赋值符号的右边,但是不能出现出现在赋值符号的左边,右值不能取地址。右值引用就是对右值的引用,给右值取别名。
注意:=左边操作数一定是左值
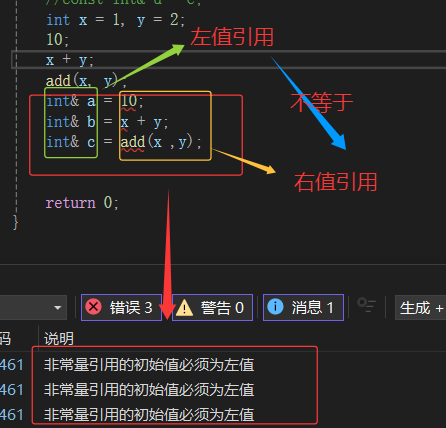
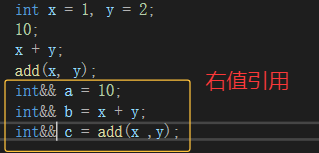
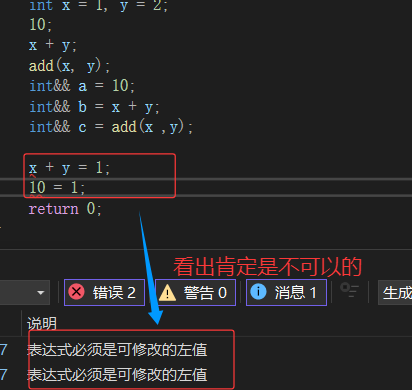
ps:右值是不能取地址的,但是给右值取别名后,会导致右值被存储到特定位置,且可以取到该位置的地址,也就是说例如:不能取字面量10的地址,但是bb引用后,可以对bb取地址,也可以修改bb。如果不想aa被修改,可以用const int&& aa 去引用,
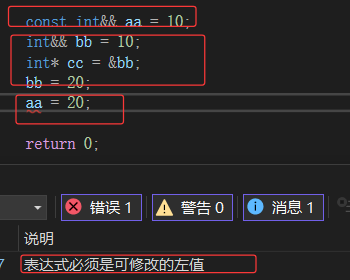
比较左值引用与右值引用:
左值引用加const才可给右值取别名。这也是为什么之前我们写函数时void func(const int &x)的原因:这样它即可引用左值又可引用右值。
右值引用加move可以给左值取别名
左值引用的使用场景和价值
场景:1.做参数 2.做返回值
价值:减少拷贝。
缺点:局部变量做返回解决不了。出了作用域生命周期就结束了。
在 C++ 里,当函数按值返回对象(像这里的 string 类型)时,理论上会先创建返回对象的拷贝,再用这个拷贝去初始化接收返回值的对象(比如 main 里的 ret )。但如果是连续的拷贝操作,有些编译器会进行优化,直接在销毁原对象前,把原对象的值拷贝给最终要接收的对象( ret ),不过这种拷贝对于大对象(比如很长的字符串)来说,会有较大的性能开销,因为涉及大量数据的复制。

接下来实现,我们会在之前实现string的基础上添加上
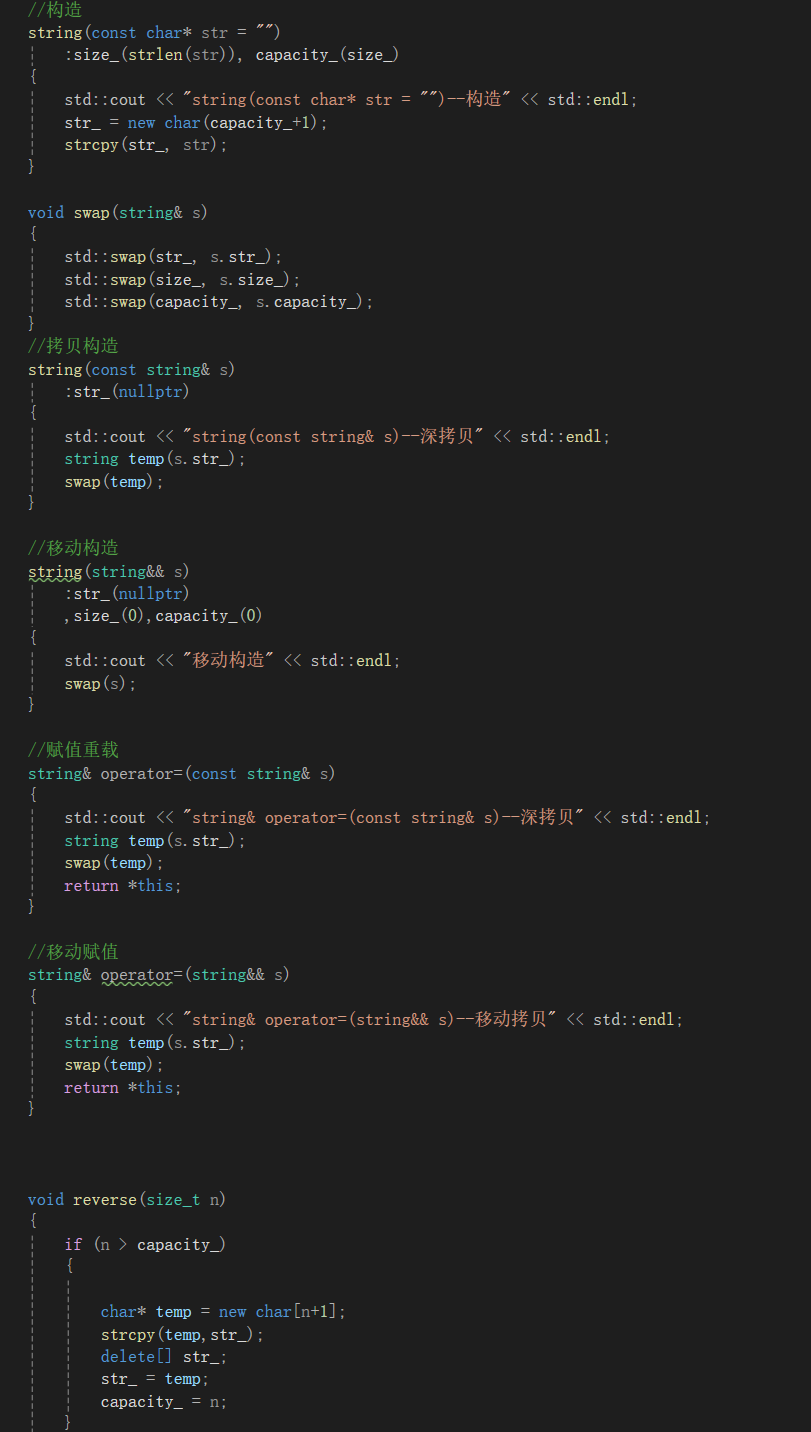
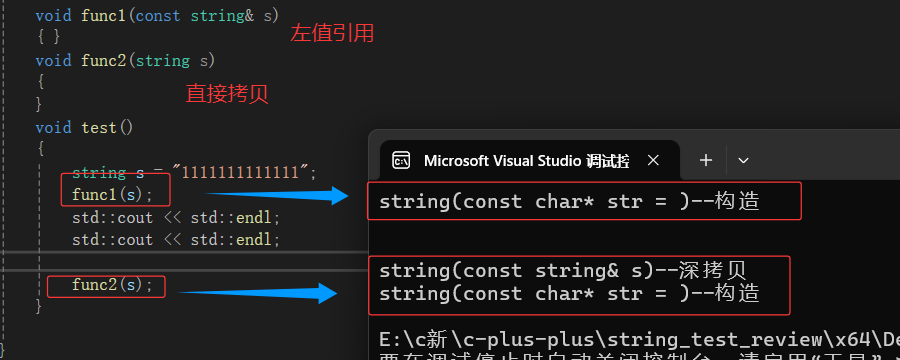
接着,我们先来对比一下使用左值引用与没有使用两种的区别:
我们会发现使用了左值引用的函数,在调用时,直接构造,而不用先拷贝在构造。这也进一步说明了我们左值引用确实是像上面所说的减少拷贝,提高效率的。
正常本来这里应该是构造+两次拷贝构造的,但是现在我用VS2022的时候发现它直接优化了。
C++中,返回值优化,可以让你在返回对象时,直接构造对象,而避免拷贝构造
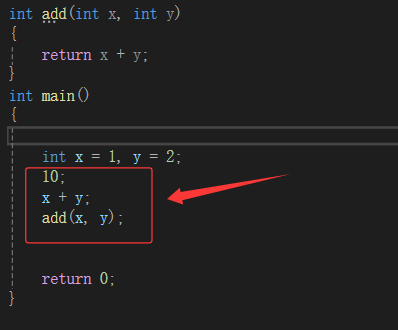
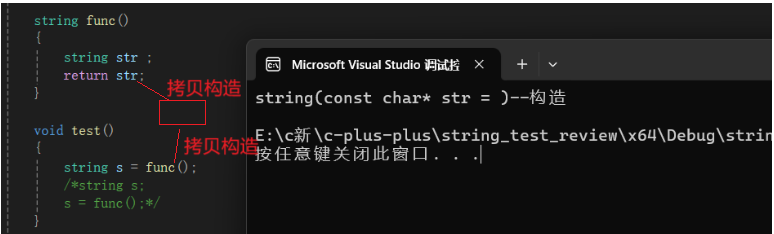
正常分析:
func的返回值是一个右值,用这个右值构造s,如果没有移动构造,调用就会匹配调用拷贝构造,因为const左值引用是可以引用右值的,这里也就是一个深拷贝。
我们可以看到,如果我们写了移动拷贝的话,因为这个是右值引用,所以编译器会走更匹配的右值引用版本的移动拷贝,而不去走深拷贝。
接着,我们再来认识几个名词:
内置类型的右值:纯右值。
自定义类型的右值:将亡值。(ps:为什么叫将亡值?因为它的生命周期只在自己的作用域)。
eg:
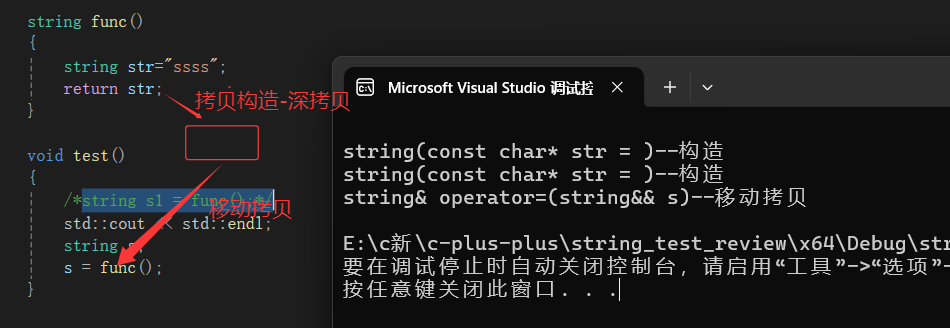
上面的func函数,return str;
main函数那里s=func(),即s=右值将亡值。此时就可以采用移动拷贝的方式了。
而如果是s=左值,就得老老实实去拷贝了
右值引用和移动语义解决上述问题:
在模拟的string中增加移动构造,移动构造本质是将参数右值的资源窃取过来,占位已有,那么就不用做深拷贝了,所以它叫做移动构造,就是窃取别人的资源来构造自己
用例子去形象化理解:电视剧的仙人练功:
方式一:老老实实去练----代价就是慢,得花时间100万年那种(深拷贝)
方式二:一个人准备挂的时候,吸收掉他的内功---提升内力快。反正它都要挂了,不吸收白不吸收。(移动拷贝)
移动拷贝有个坑:不仅吸收你的功力,而且还要把他不要的东西丢给你。(直接转化成资源)
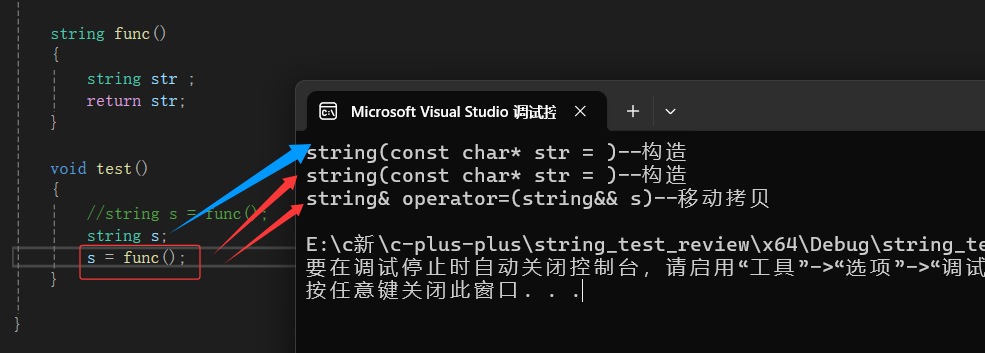
我们上面说到过vs2022直接把拷贝构造优化掉了(同时也不好演示移动构造)。
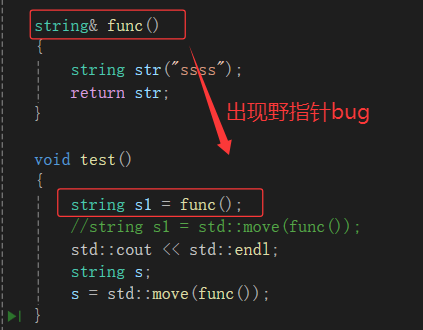
但按正常来说:虽然str是左值,但str毕竟做了func表达式的左值,本来不是str做,是它的拷贝对象去做,但是拷贝对象被优化了,相当于str做了,而str又符合将亡值特征,所以编译器把str会识别成右值---将亡值。
问题一:
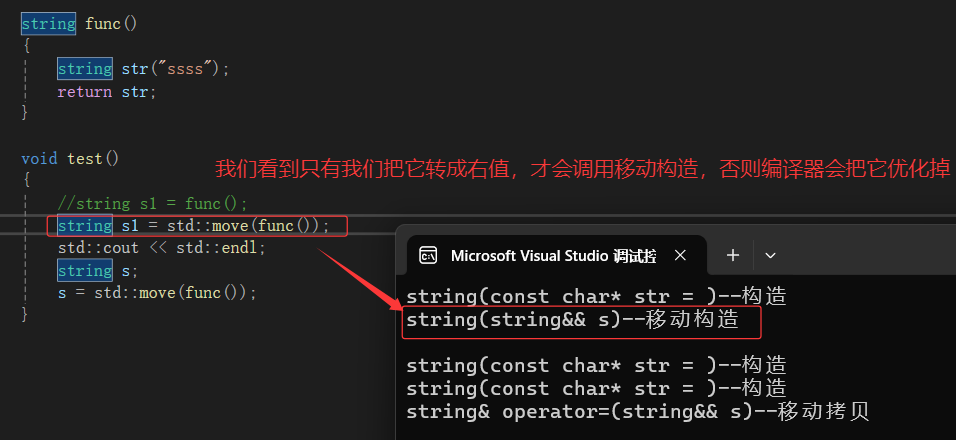
我们在func的返回值上加了&或者&&的话,发现编译不过。为什么呢?
你加了就不是返回str了,而是它的别名。编译器是怎么做优化的?
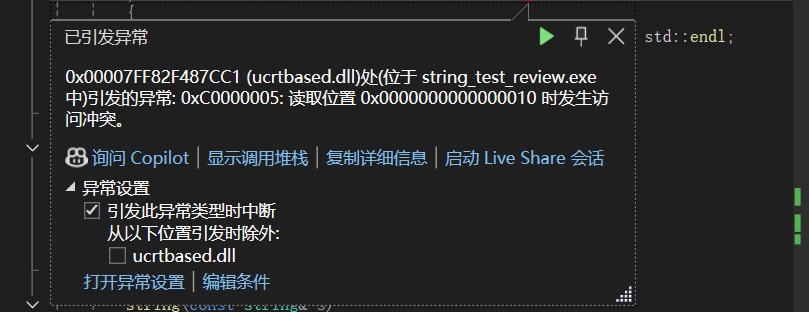
因为:你用的是传值返回,所以先深拷贝一次,再拷贝一次浅拷贝,当它做这表达式的返回值时,str已经销毁了,而你取了别名还要去访问它,所以就造成了野指针了。
但是当你把它转成右值的话,它就可以了。
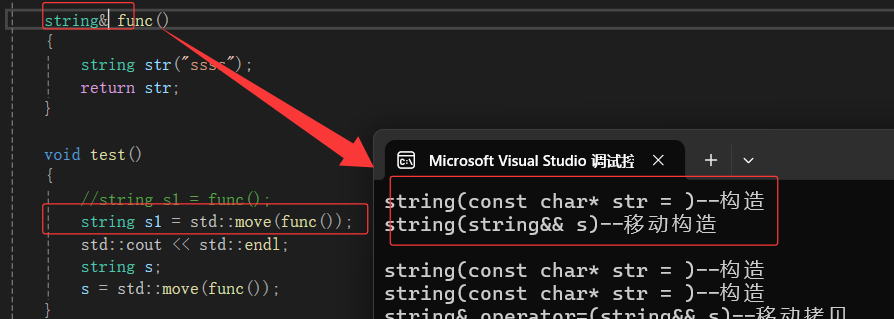
ps:在看上图,我们会发现调用了(一次拷贝没有显示编译器优化了)一次移动赋值。因为如果是用一个已经存在的对象接收,编译器就没办法优化了。func函数中会先用str生成构造生成一个临时对象,但是我们可以看到,编译器很聪明的在这里把str识别成了右值,调用了移动构造。然后在把这个临时对象做为func函数调用的返回值赋值给ret1,这里调用的移动拷贝。
但是,不知道是不是现在编译器优化,直接把拷贝构造优化掉的原因,并没有调用移动构造,而是直接构造(省去了深拷贝??没啥区别?)
算法题中体现优势:
如果没有C++11,想要减少拷贝上的消耗,不得不在参数那里引入左值引用减少拷贝,而现在出了C++11后就可以不用在参数加了

总结:
1.右值引用的核心价值是减少拷贝,提高效率。
2.右值引用的核心价值是进一步减少拷贝,弥补左值引用,没有解决的场景:eg:传值返回。
3.右值引用在传参中,如果出了作用域,返回对象(引用返回)还在的场景已经很好了(以前需要拷贝,现在不用),但是引用上减少拷贝,减少的是自定义类型,内置类型不在乎,代价都不大(eg:内置类型最大也就是8字节)。
右值引用的场景:
1.自定义类型中深拷贝的类,必须传值返回的场景:
内置类型不考虑,哪怕浅拷贝的自定义类型:右值引用,移动构造
换一角度来讲,我们之前写过的日期类要不要写移动构造/赋值呢?
没必要,你是一个右值,自定义类型右值,是将亡值 ,你都要走了,转移过来,eg:树->转根)
而日期类,只是年给给年,月给给月,这跟拷贝构造有什么区别?
所以浅拷贝的类,移动构造不要实现,没有什么需要转移的资源,只能是直接拷贝。而且它返回拷贝的代价也不是很大。

按照语法:右值引用只能引用右值,但右值引用一定不能引用左值吗?因为:有些场景下,可能真的需要用右值去引用左值实现移动语义。当需要用右值引用引用一个左值时,可以通过move函数将左值转化为右值。C++11中,std::move()函数位于 头文件中,
注意:!!!它并不搬移任何东西,唯一的功能就是将一个左值强制转化为右值引用,然后实现移动语义
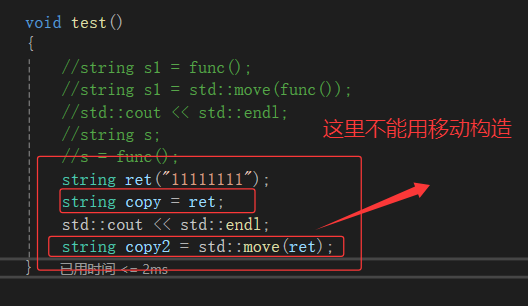
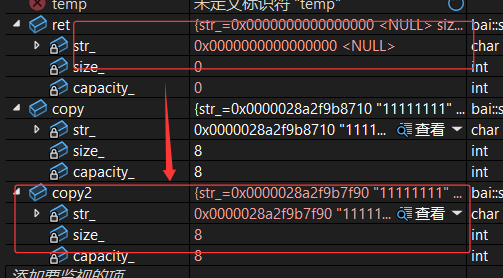
当ret的资源会“转移给”copy2,而ret的资源就会变成空壳(资源所有权让渡,自身不再持有有效的资源)。
补充:std::move 本身不移动数据,而是将变量标记为“可移动的右值”,告诉编译器:“这个变量的资源可以被转移,后续不用再保留它的原始数据了”。
因此:这种情况可不能使用移动构造!!!!!
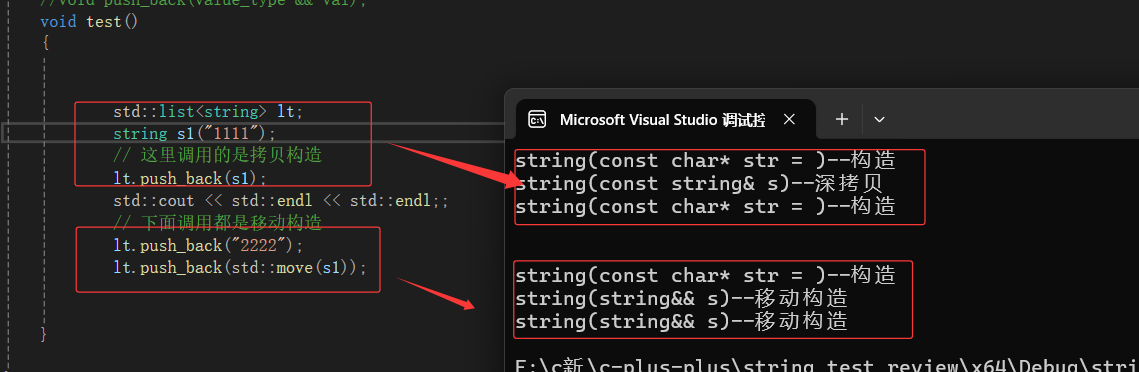
场景2:
→构造 + 拷贝构造,
那里多了一次是因为 现代写法 String temp(s)
为什么下面是移动构造?s1传参过来,要构造一个临时对象即隐式类型转化,然后传给右值引用的push_back。
之前:构造+拷贝构造
现在:构造+移动构造(资源只产生了一份)
什么时候才能优化?只有在同一行中才能优化,如上面图代码。或者返回值时才存在优化。
string存在在哪里?string里面给了一个常量字符串,不是存在常量区,而是在堆上开空间,把这个数据拷贝过来。存在自己的指针指向堆上的空间(看上面string的构造代码)
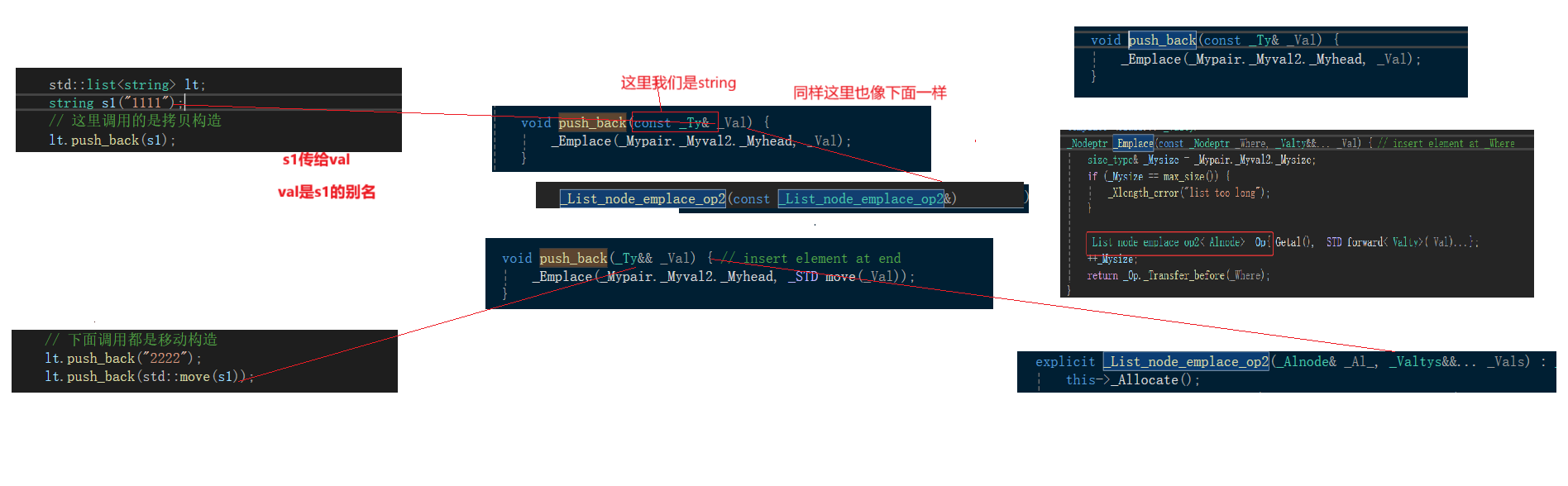
lt.push_back("222222");→lt.push_back("22222"); →这个是常量字符串,它是右值,那么它是否强行给它弄成左值??
答:并不是转移常量字符串 → 并不是它传给 value
这里的 value - type 实质是 string
它可传过去的原因是它走了一个隐式类型转换,单参数构造
函数隐式类型转换,是不是要构造一个匿名对象再传过去
其次,就算它是字符串的话,这个表达式隐式 整体而言返回的是
新元素的地址(也算左值)
2、容器的插入接口,如果插入对象是左值,可以利用移动构造转移资源给数据结构中的对象,也可以减少拷贝。
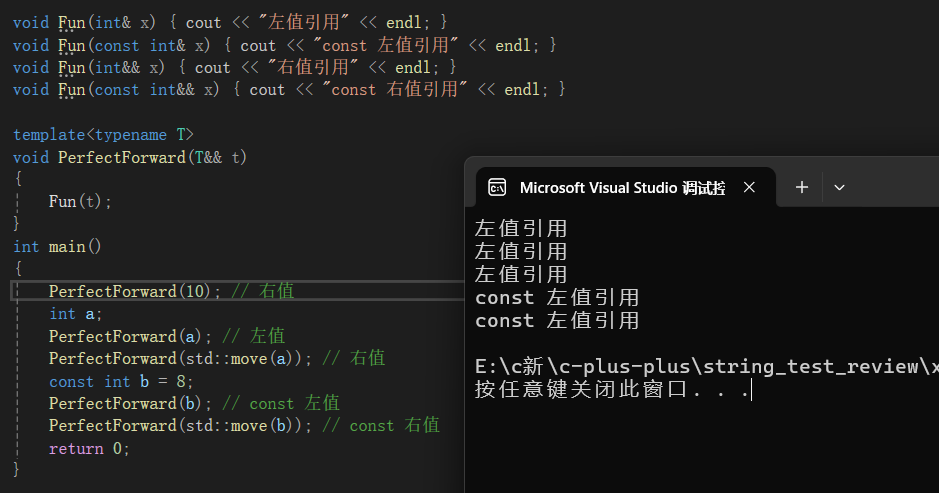
万能引用(结合模板和引用折叠)
1. 万能引用的定义
“万能引用” 是指:在模板语境下,形如 T&& 的引用( T 是模板参数),它既可以接收左值,也可以接收右值。
2. “引用折叠” 规则(核心逻辑)
为了让 T&& 能灵活适配左值 / 右值:
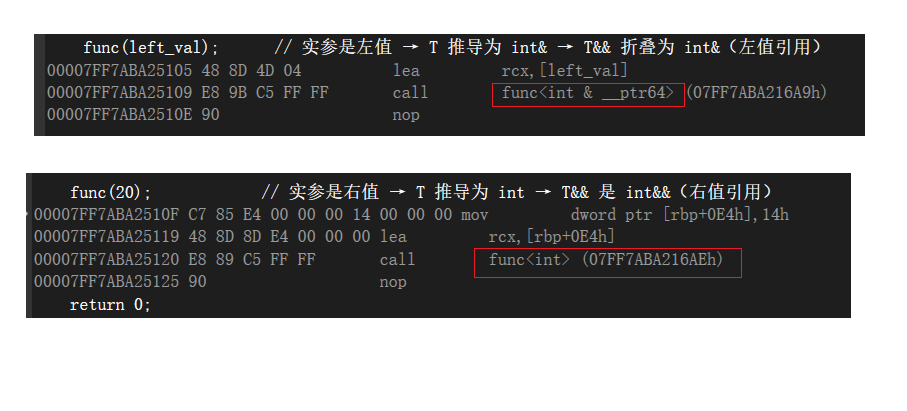
- 如果传递的实参是左值:模板参数 T 会被推导为左值引用类型(比如实参是 int& ,则 T 推导为 int& )。此时 T&& 会折叠为 int& && → 最终变成 左值引用 int& 。- 如果传递的实参是右值:模板参数 T 会被推导为非引用类型(比如实参是 10 ,则 T 推导为 int )。此时 T&& 就是 右值引用 int&& 。
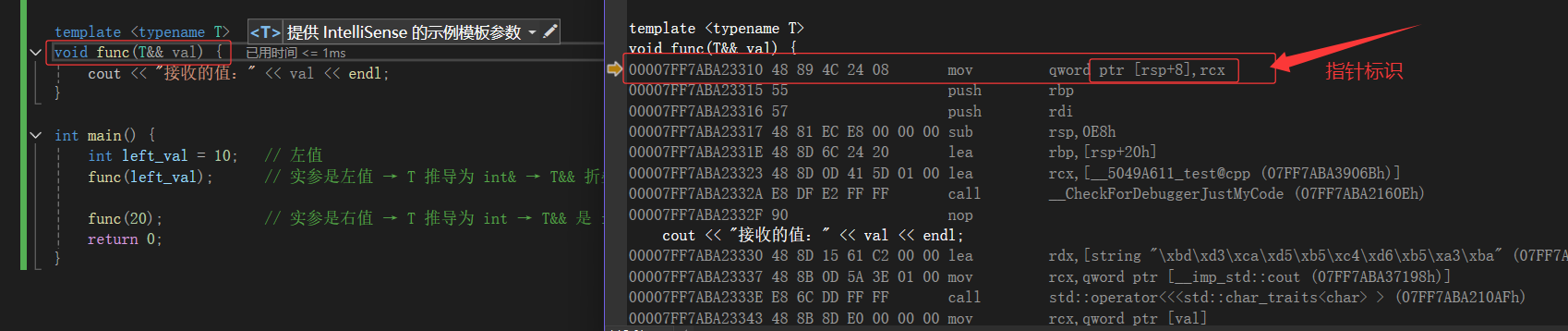
#include <iostream> using namespace std; template <typename T> void func(T&& val) { cout << "接收的值:" << val << endl; } int main() { int left_val = 10; // 左值 func(left_val); // 实参是左值 → T 推导为 int& → T&& 折叠为 int&(左值引用) func(20); // 实参是右值 → T 推导为 int → T&& 是 int&&(右值引用) return 0; }
通过上面的汇编,我们就可以更加清楚的证明出就是像我们说的那样!!!
之前说move以后的左值表达式是右值eg:int c=a+b;a+b传值返回的是右值。但没说右值引用是属于右值。
注意:右值是不能够修改的,不能取地址,而如果右值引用不支持修改的话,就没办法玩了。
func() { string str("xxxxxxx"); return str; } string ret=func();str识别成右值,本质上就是把str的资源转移给它。右值调用移动构造,要不要修改构造函数里的string&& s,s的属性是什么?如果s的属性是右值,它能传给左值吗?
理解:你是右值,你不能修改,我是你的右值引用,你可认为我可以开一块空间,把你的值存起来。
int&&rrr=10;rrr++;是可以的;
把你自己(属性)当作左值,因为右值引用,引用了别人,自己是能修改的。
总结:
右值引用变量的属性会被编译器识别成左值,
否则在移动构造的场景下,无法完成资源转移,必须要修改
右值能不能传给左值引用??
×,只可传给 const 左值引用
完美转发
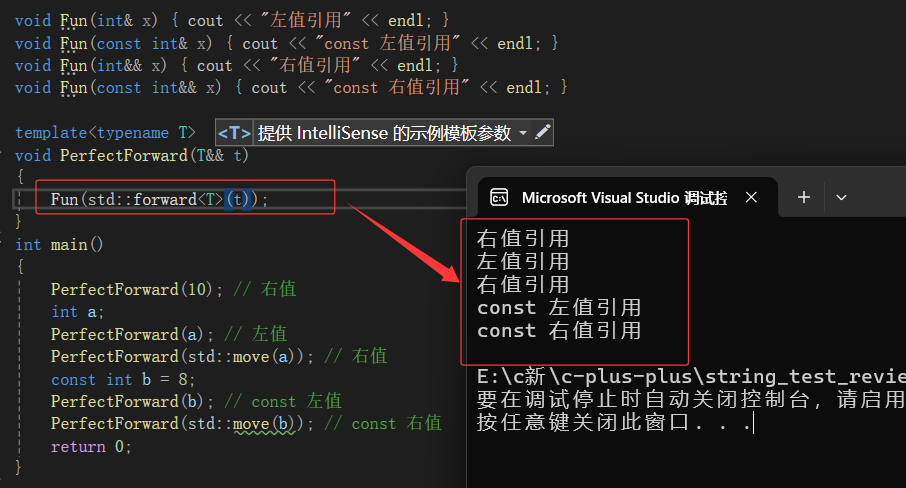
如果我就想留它本身的属性呢??
完美转发:t 是左值引用,保持左值属性,右值就保持右值属性)/
(forward<T> t)
→如果我就是要保持这个属性呢? 有的地方不需要保持属性,左值引用
默认就是左值,这个才可转移资源
可能有人疑惑的是,为什么这有些明明是右值引用,打印出了却是左值引用?
这是因为:引用类型的唯一作用就是限制了接收的类型,后续使用中都退化成了左值
即:引用(包括右值引用)在命名,被使用时,会退化成左值:因为它有名字,能够被操作,符合左值的特征。
保持它的属性:完美转发
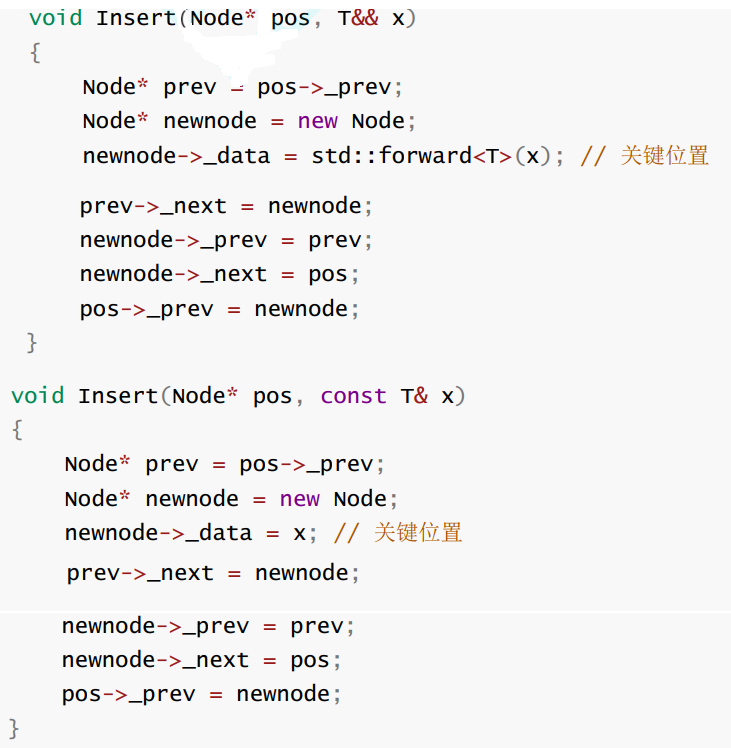
(修改自己模拟实现的list)
lambda表达式
一般都是局部的匿名函数对象。
C++中可以调用对象的有:
1.函数指针:(能不用就不用)void*(*ptr)(int x)
2.仿函数 : ---类重载operator(),对象可以像函数一样使用
3.lambda:匿名函数对象---auto自动推导,函数内部直接定义使用。
表达式书写格式:
[capture-list] (parameters) mutable -> return-type { statement }
[capture-list] : 捕捉列表,该列表总是出现在lambda函数的开始位置,编译器根据[]来判断接下来的代码是否为lambda函数,捕捉列表能够捕捉上下文中的变量供lambda函数使用。
(parameters):参数列表。与普通函数的参数列表一致,如果不需要参数传递,则可以连同()一起省略
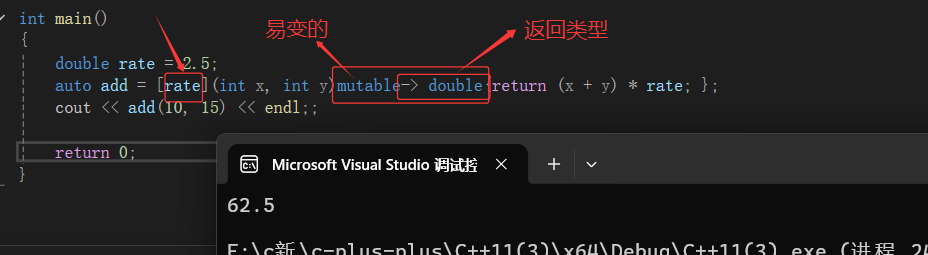
mutable:默认情况下,lambda函数总是一个const函数,mutable可以取消其常量性。使用该修饰符时,参数列表不可省略(即使参数为空)。
->returntype:返回值类型。用追踪返回类型形式声明函数的返回值类型,没有返回值时此部分可省略。返回值类型明确情况下,也可省略,由编译器对返回类型进行推导。
{statement}:函数体。在该函数体内,除了可以使用其参数外,还可以使用所有捕获到的变量。
2. 捕获列表说明
捕捉列表描述了上下文中那些数据可以被lambda使用,以及使用的方式传值还是传引用。
[var]:表示值传递方式捕捉变量var
[=]:表示值传递方式捕获所有父作用域中的变量(包括this)
[&var]:表示引用传递捕捉变量var
[&]:表示引用传递捕捉所有父作用域中的变量(包括this)
[this]:表示值传递方式捕捉当前的this指针
父作用域指包含lambda函数的语句块
b. 语法上捕捉列表可由多个捕捉项组成,并以逗号分割。
比如:[=, &a, &b]:以引用传递的方式捕捉变量a和b,值传递方式捕捉其他所有变量[&,a, this]:值传递方式捕捉变量a和this,引用方式捕捉其他变量
c. 捕捉列表不允许变量重复传递,否则就会导致编译错误。
比如:[=, a]:=已经以值传递方式捕捉了所有变量,捕捉a重复
d. 在块作用域以外的lambda函数捕捉列表必须为空。
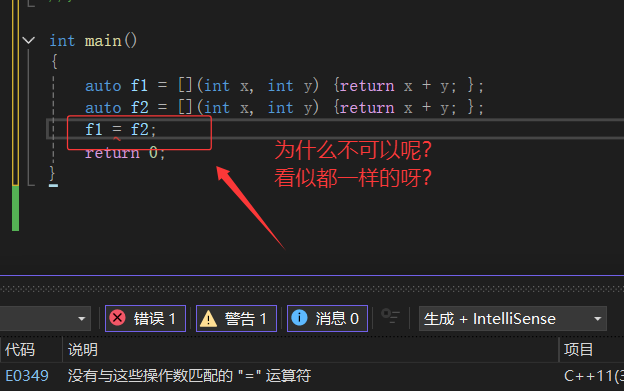
e. 在块作用域中的lambda函数仅能捕捉父作用域中局部变量,捕捉任何非此作用域或者非局部变量都会导致编译报错。f. lambda表达式之间不能相互赋值,即使看起来类型相同
一大堆晦涩难懂的文字固然难懂,所以不如我们直接通过写代码来认识!!
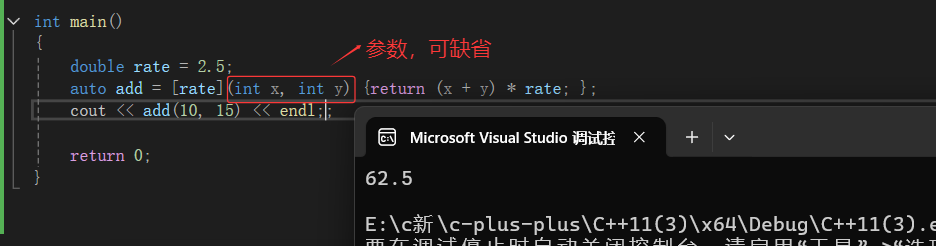
对于想要实现一个自定义的类,编程者们觉得不方便,麻烦得每次都实现很多个类,所以lambda出现就是为了减少这么麻烦的。像上面,我们使用lambda就直接可以写成这样:
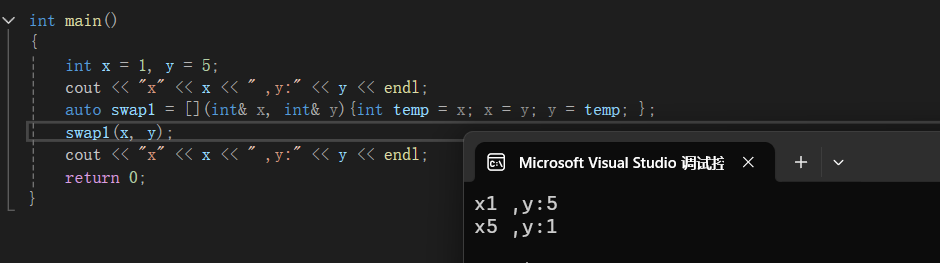
交换:
上面的mutable--易变的,让捕捉的x和y可以改变了,但是他们依旧是外面x和y的拷贝
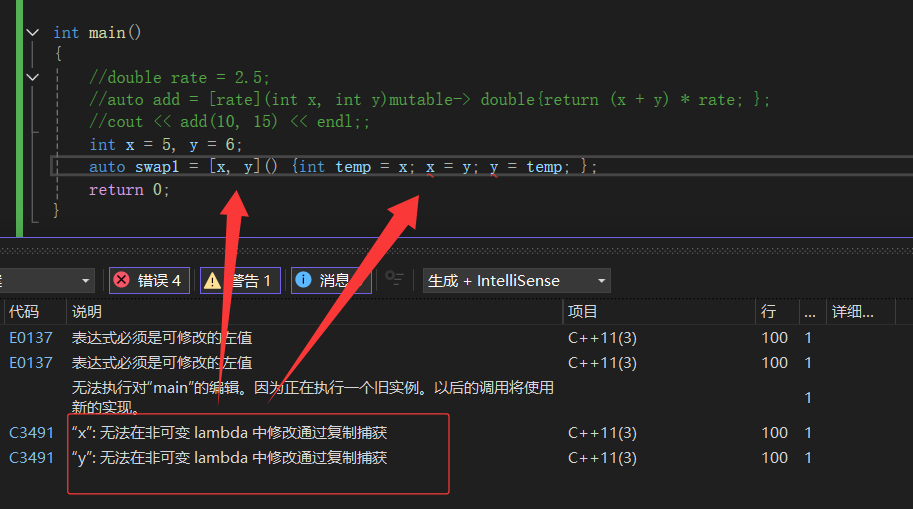
另外,当我们写成这样子的话,我们会发现它编译不过去:
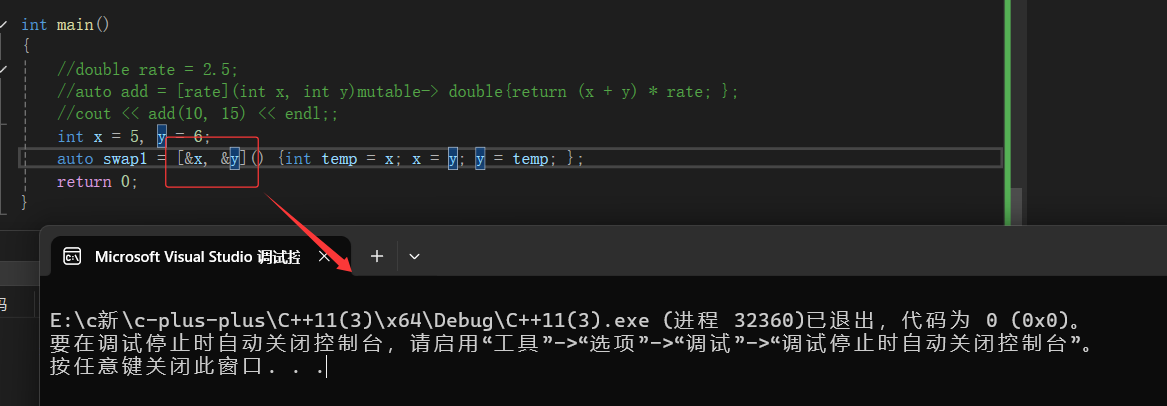
上面两种情况都可以编译过了就可以了,加上引用/mutable。
所以说引用很灵活,普通引用~普通。const引用~const捕捉
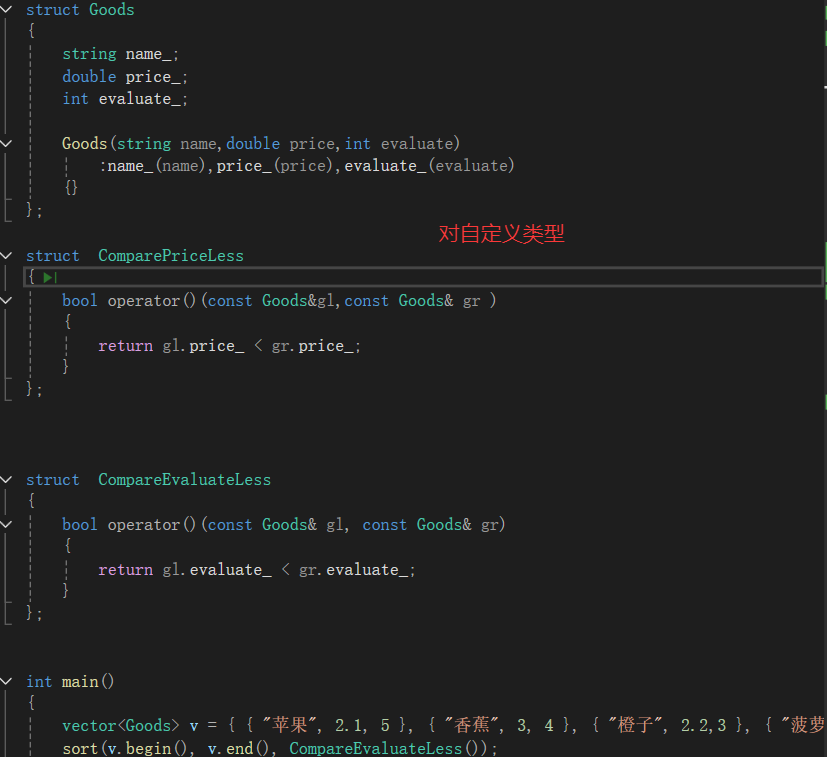
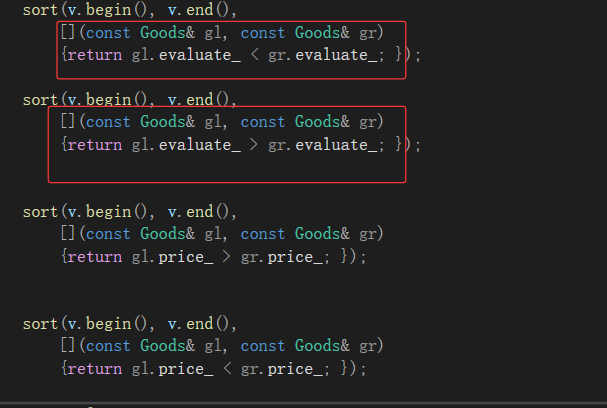

问题:
当我们打印一下关于他们的类型:
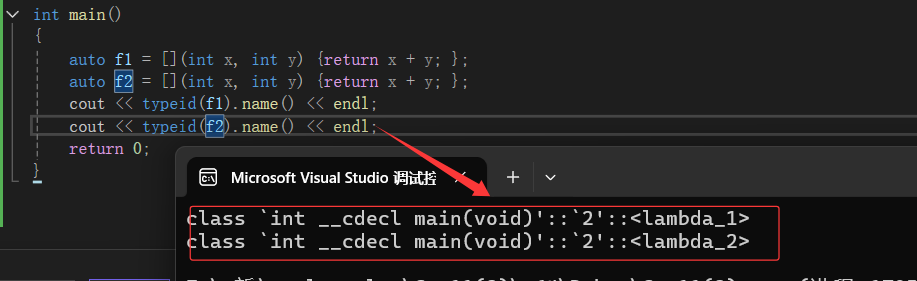
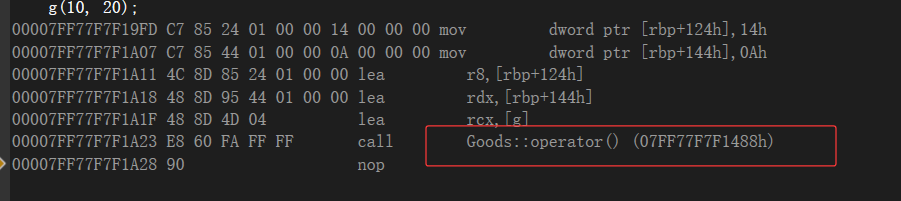
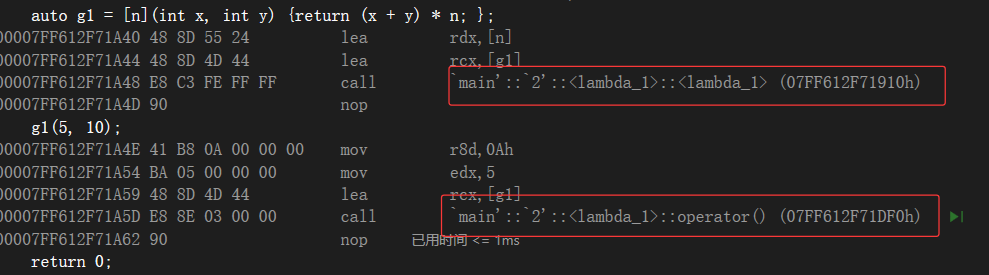
发现他们是类,它们不是匿名对象吗,怎么变成类了?其实lambda底层跟范围for差不多,都是一比一替代而已。范围for是迭代器,lambda是生成两个仿函数的类。
看仿函数与lambda两者中的底层代码:
可变参数模板
printf的方式:
printf("%d",x);
printf("%d%d",x,y);
printf("%d%d%d",x,y,z);
当我们想要打印出来不定项的参数时,如果我们像上面一样固定写,就显得非常麻烦。
那么现在我们就有了新的一种方式解析:
优势:创建可以接受可变参数的函数模板和类模板,不像C++98/03,类模版和函数模版中只能含固定数量的模版参数,可变模版参数无疑是一个巨大的改进。
由于对于可变参数的灵活使用有一定的难度,我们只简单了解使用即可:
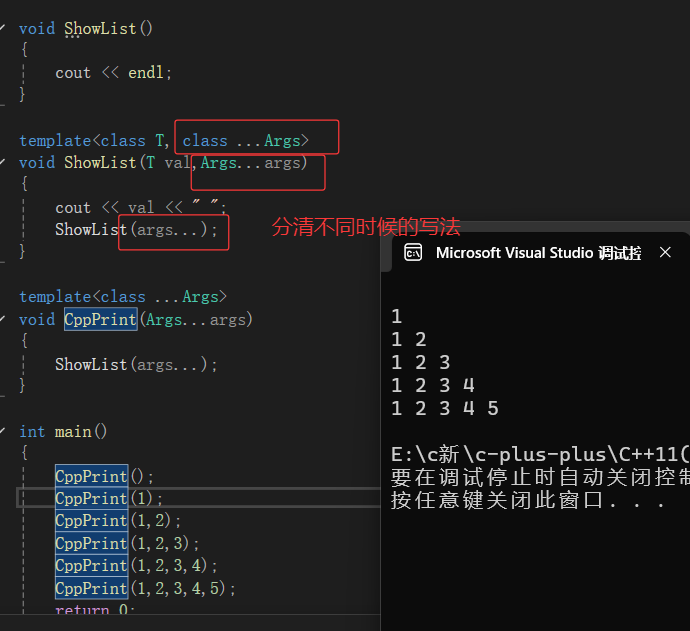
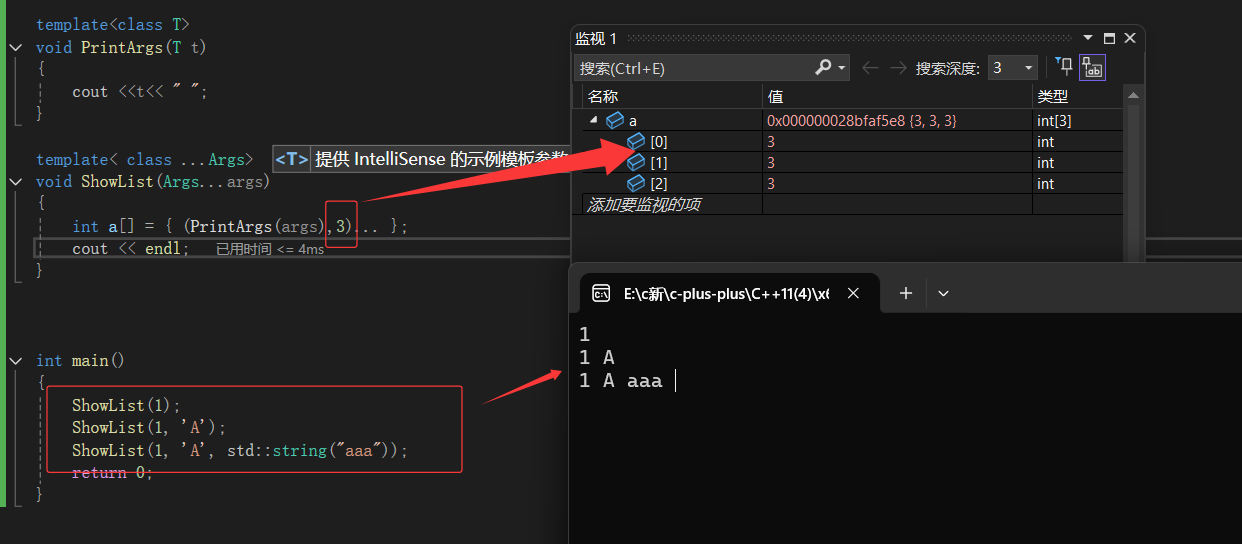
这里运用了可变参数展开和逗号表达式:
(1)可变参数模板
template< class ...Args> 和 void ShowList(Args... args) 表示 ShowList 是一个可变参数函数模板,可以接收任意数量、任意类型的参数(参数包 args )。
(2)逗号表达式
(PrintArgs(args), 3) 是逗号表达式。逗号表达式的规则是:从左到右依次计算,最终结果为最后一个表达式的值。
- 这里先执行 PrintArgs(args) (即调用 PrintArgs 打印当前参数),然后取 3 作为结果。
(3)可变参数展开
{ (PrintArgs(args), 3)... } 中, ... 是可变参数展开符,会将参数包 args 中的每个参数都执行一次 (PrintArgs(args), 3) ,并将所有结果(都是 3 )收集到数组 a 中。4)参数包有多少个值就会展开几次,调几个函数
依次获取展开包的内容(因为要知道这个数组要开多大)
ps:虽然这个代码没有任何实际意义,但它表面了个数组的目的纯粹是为了在数组构造的过程展开参数包
包装器:
std::function包装器 也叫作适配器
int y=func(x);
上面的代码中:func(x)是什么?可能是函数名?函数指针?lambda?仿函数?都有可能。我们上面说过这些都是可调用对象。
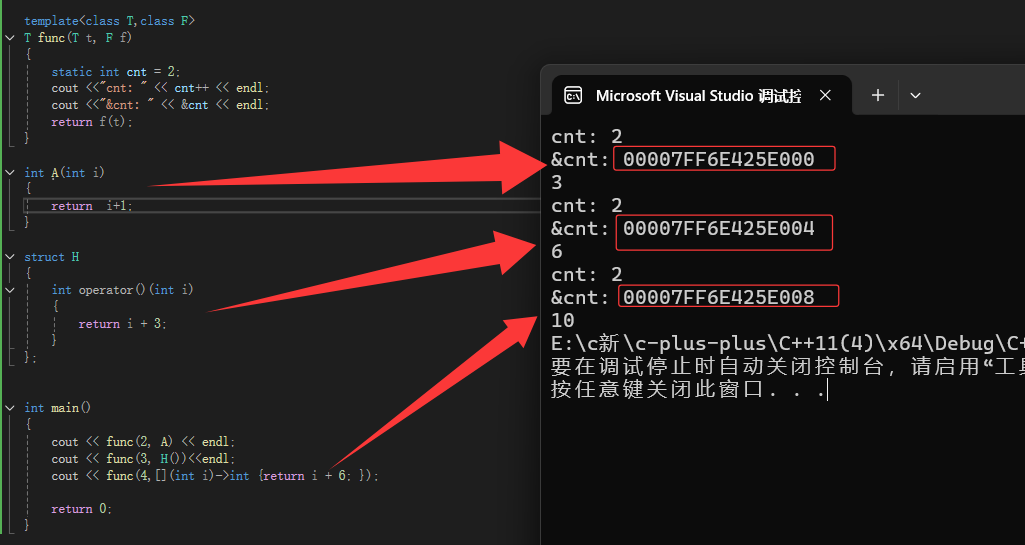
我们看到上面,它实例化出三份。模板效率低下,那么我们有什么办法解决吗?
答案是用我们的包装器,
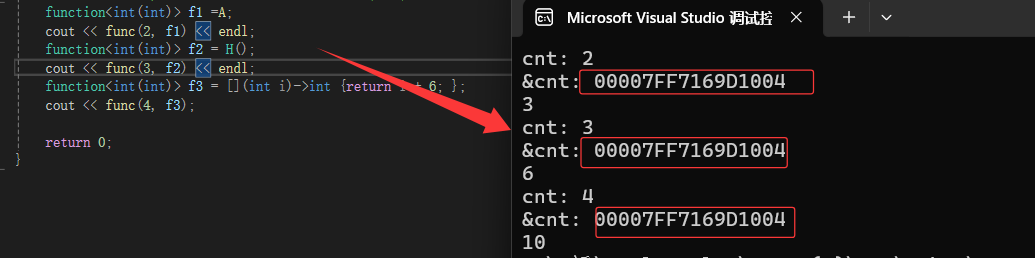
还可以包装我们的类成员函数:
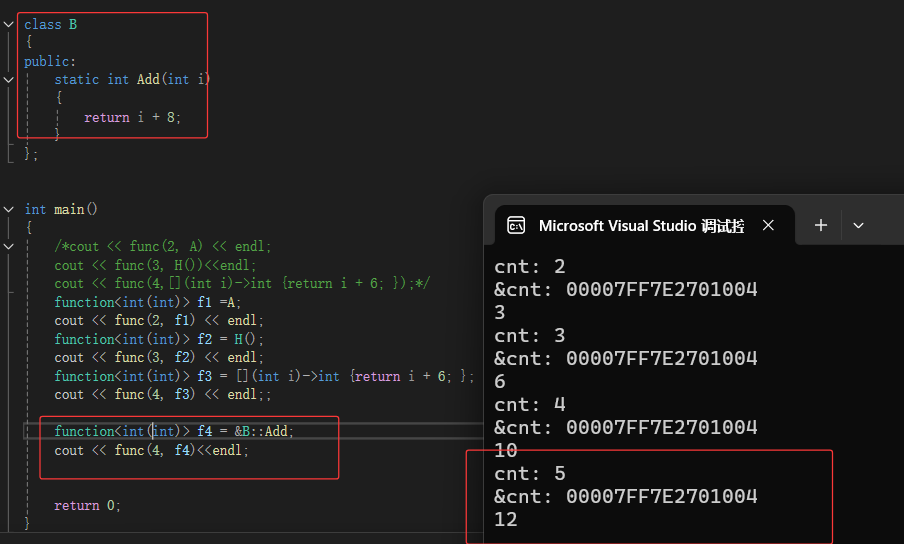
包装器的另一些场景:
算法题中的逆波兰表达式求值:当我们+-*/时,我们不再需要用switch,而是应用
class Solution {
public:
int evalRPN(vector<string>& tokens) {
stack<int> st;
map<string, function<int(int, int)>> opFuncMap =
{
{ "+", [](int i, int j){return i + j; } },
{ "-", [](int i, int j){return i - j; } },
{ "*", [](int i, int j){return i * j; } },
{ "/", [](int i, int j){return i / j; } }
};
for(auto& str : tokens)
{
if(opFuncMap.find(str) != opFuncMap.end())
{
int right = st.top();
st.pop();
int left = st.top();
st.pop();
st.push(opFuncMap[str](left, right));
}
else
{
st.push(stoi(str));
}
}
return st.top();
}
};
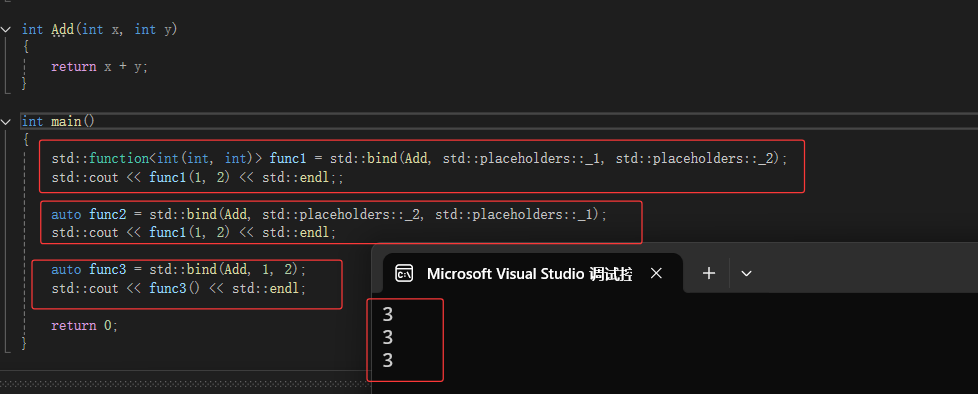
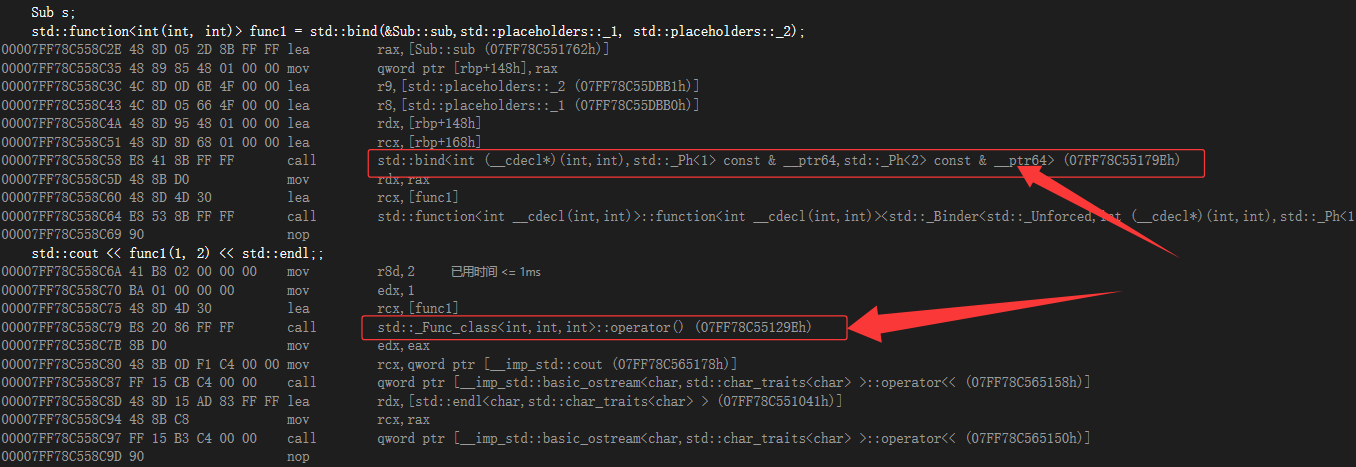
bind函数
是什么?
是一个函数模板,它就像一个函数包装器(适配器),接受一个可调用对象(callable object),生成一个新的可调用对象来“适应”原对象的参数列表
用法:
1.使用std::bind函数还可以实现参数顺序调整等操作
2.用它可以把一个原本接收N个参数的函数fn,通过绑定一些参数,返回一个接收M个(M可以大于N,但没意义)
一般形式:
auto newCallable = bind(callable,arg_list)
newCallable本身是一个可调用对象,arg_list是一个逗号分隔的参数列表,对应给定的callable的参数。当我们调用newCallable时,newCallable会调用callable,并传给它arg_list中的参数。
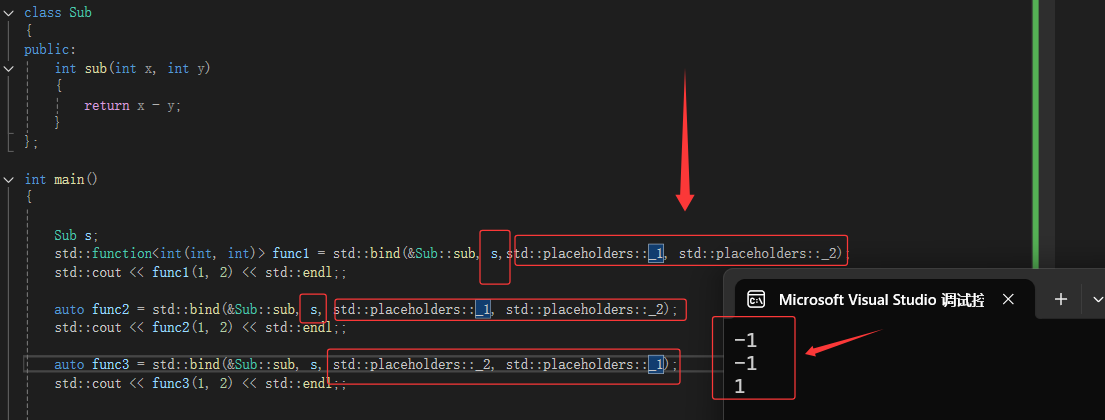
使用std::bind函数还可以实现参数顺序调整等操作
ps:
类是一个域:
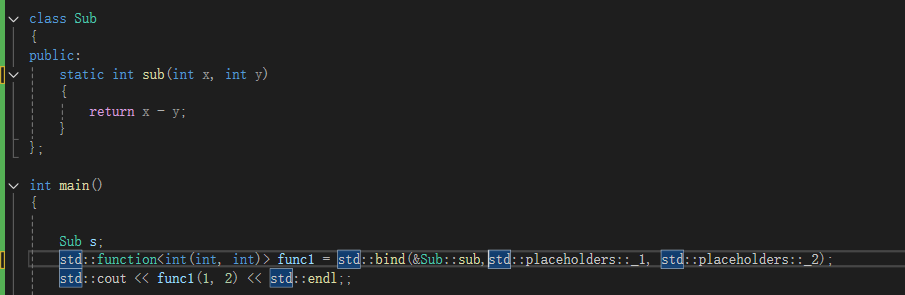
非静态的成员函数取地址:它的参数实际上会多一个this指针(如图)。
传对象地址的指针,对象都可以bind.
其中,bind的底层实际上也是一个跟lambda一样生成仿函数。如图下:
所以这就说得通了:为什么对象可以,指针也可以
因为是operator(),用对象去调用函数。
注意:!!!!1绑定的是成员函数,传地址!!!!传对象!!!传指针!!!!!1
新的类功能
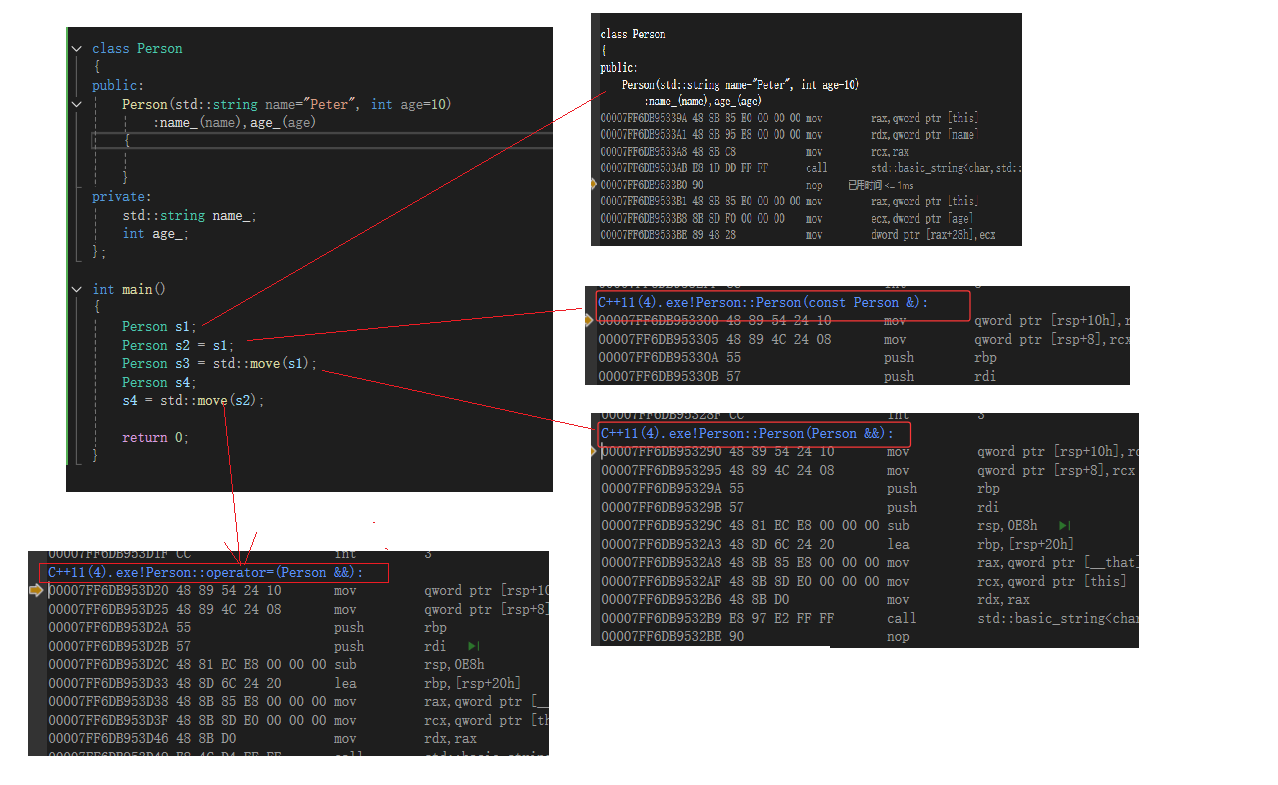
复习:C++11之前中有六个默认成员:
构造,拷贝构造,拷贝赋值重载,析构,取地址重载,const取地址重载。
而在C++11出现后,新增了两个:移动赋值运算符重载(移动拷贝),移动构造。
下面是它们两个需要注意的点:
1.如果你没有自己实现移动构造函数,且没有实现析构函数 、拷贝构造、拷贝赋值重载中的任意一个。那么编译器会自动生成一个默认移动构造。默认生成的移动构造函数,对于内置
型成员会执行逐成员按字节拷贝,自定义类型成员,则需要看这个成员是否实现移动构造,如果实现了就调用移动构造,没有实现就调用拷贝构造。
如果你没有自己实现移动赋值重载函数,且没有实现析构函数 、拷贝构造、拷贝赋值重载中的任意一个,那么编译器会自动生成一个默认移动赋值。默认生成的移动构造函数,对于内置类型成员会执行逐成员按字节拷贝,自定义类型成员,则需要看这个成员是否实现移动赋值,如果实现了就调用移动赋值,没有实现就调用拷贝赋值。(默认移动赋值跟上面移动构造完全类似)
如果你提供了移动构造或者移动赋值,编译器不会自动提供拷贝构造和拷贝赋值。
我们通过汇编的角度去理解它:
角度一:只写了构造函数:
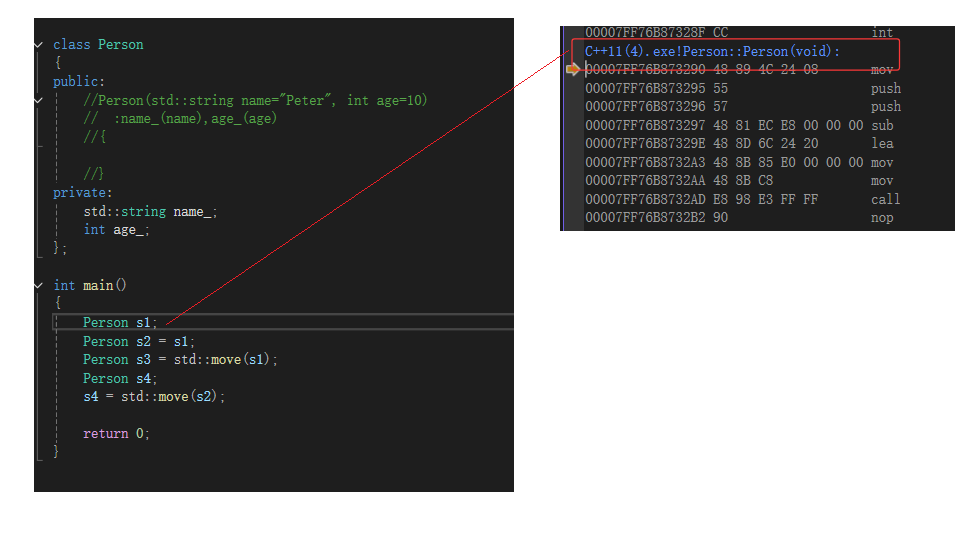
什么都没写:这也证明了之前我们说没写构造函数的时候,编译器会默认生成的结论也是对的。
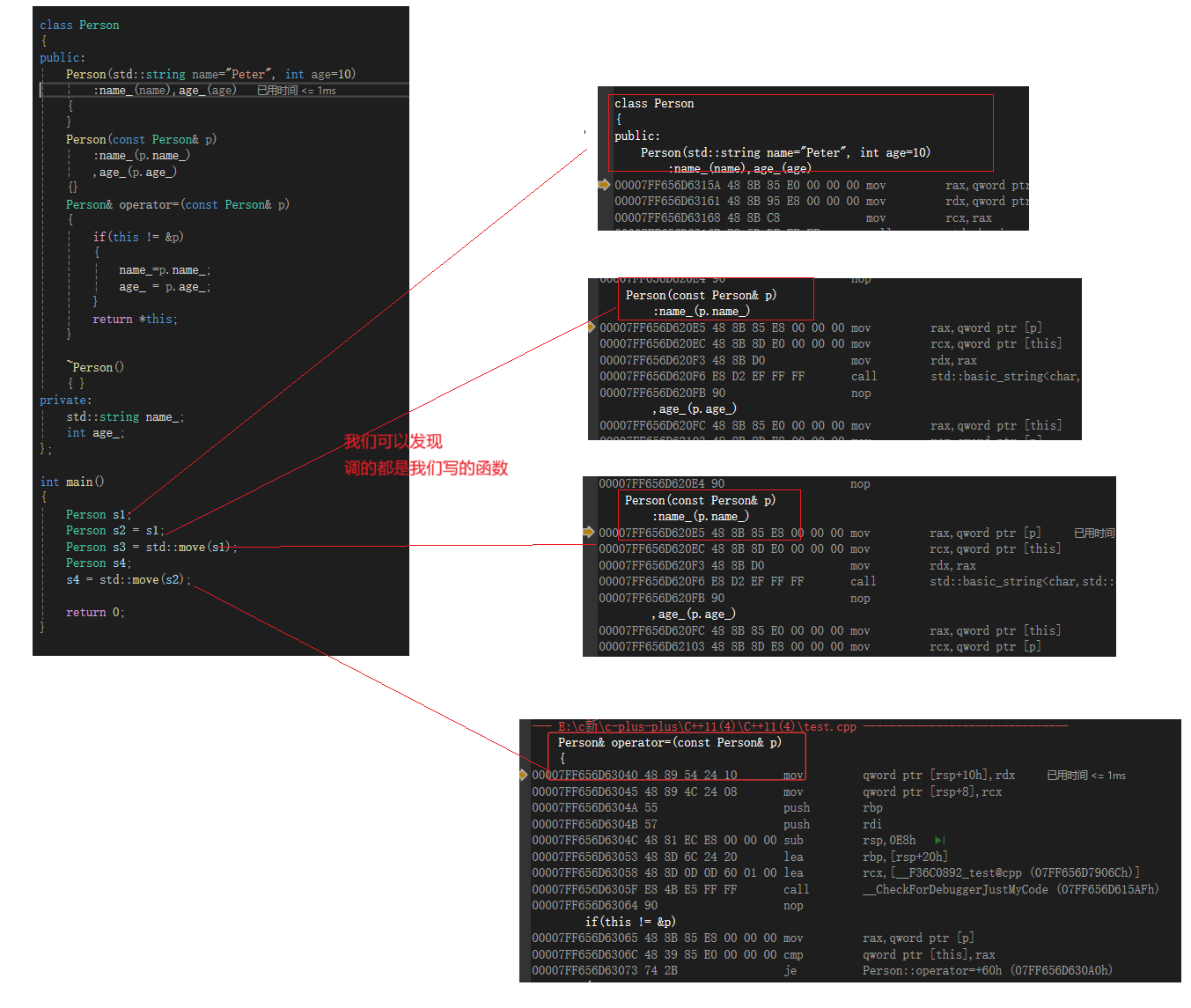
类成员变量初始化
C++11允许在类定义时给成员变量初始缺省值,默认生成构造函数会使用这些缺省值初始化
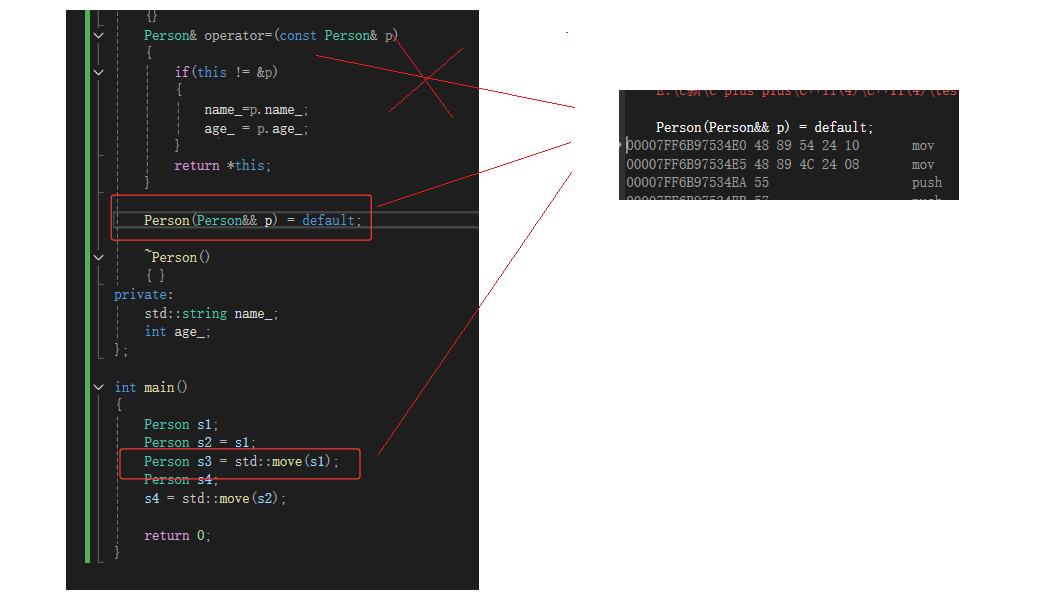
强制生成默认函数的关键字default
C++11可以让你更好的控制要使用的默认函数。假设你要使用某个默认的函数,但是因为一些原因这个函数没有默认生成。比如:我们提供了拷贝构造,就不会生成移动构造了,那么我们可以使用default关键字显示指定移动构造生成。
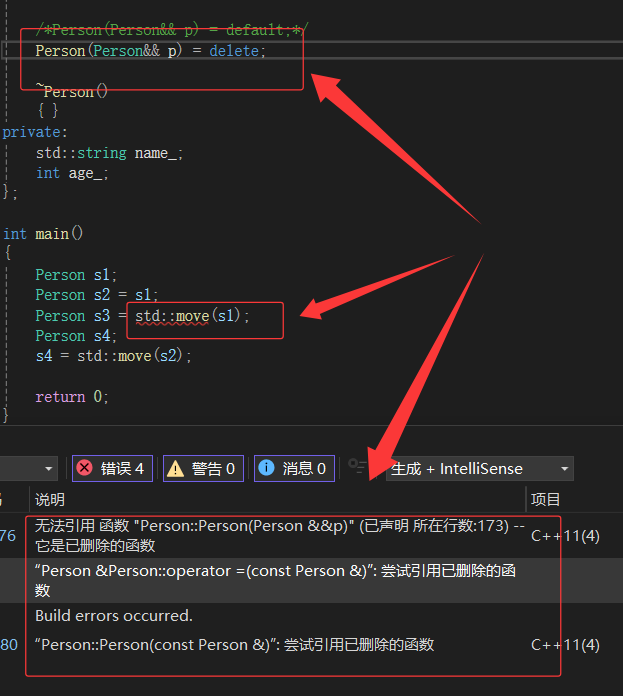
禁止生成默认函数的关键字delete:
如果能想要限制某些默认函数的生成,在C++98中,是该函数设置成private,并且只声明补丁已,这样只要其他人想要调用就会报错。在C++11中更简单,只需在该函数声明加上=delete即可,该语法指示编译器不生成对应函数的默认版本,称=delete修饰的函数为删除函数。
C++11还有继承和多态中的final与override关键字(已讲),多线程(得了解到了Linux中的多线程部分才能更好的了解).......等我们以后再讲解
好了,关于C++11的语法暂时先了解到这里吧,希望对大家有所帮助!
最后,到了本次鸡汤环节:
愿你路上一切顺利!!


















 2640
2640

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









