




一、redis的String、List、Hash底层数据结构
1、String
redis构建了一个叫做简单动态字符串(Simple Dynamic String),简称SDS
代码结构:
struct sdshdr{
// 记录已使用长度
int len;
// 记录空闲未使用的长度
int free;
// 字符数组
char[] buf;
};动态扩展:
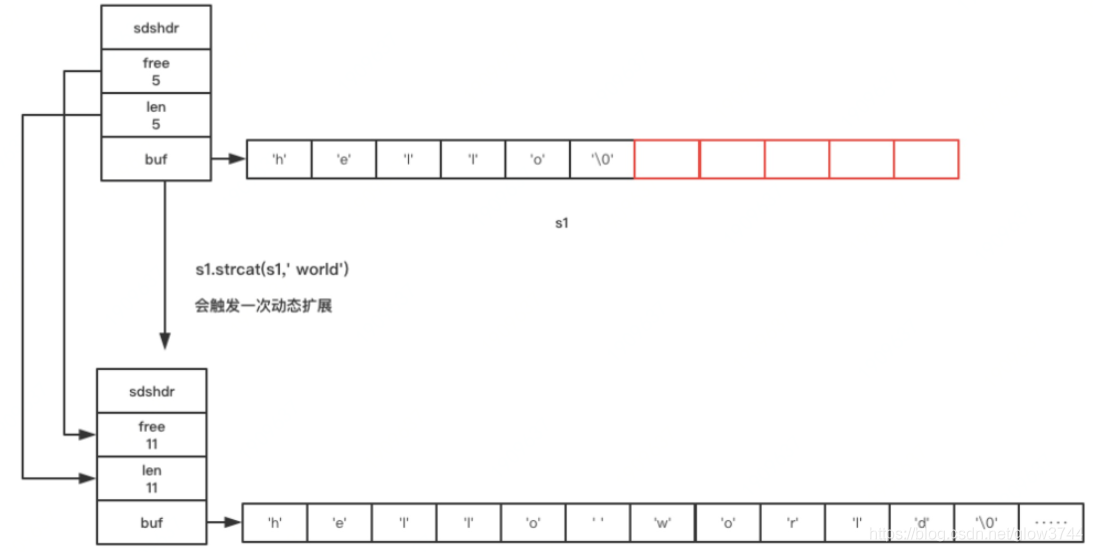
1、计算出大小是否足够
2、开辟空间至满足所需大小
3、开辟与已使用大小len相同长度的空闲free空间(如果len < 1M)开辟1M长度的空闲free空间(如果len >= 1M)
性能优势:
1、快速获取字符串长度
2、避免缓冲区溢出
3、性能提升(字符串追加与缩减)
- 空间预分配(可以减少内存分配次数)
- 惰性空间回收
参考:redis 内部是怎么实现它的字符串的 - WalkingCamel - 博客园
2、List
1、LinkedList(双向链表)
typedf struct list{
//头指针
listNode *head;
//尾指针
listNode *tail;
//节点拷贝函数
void *(*dup)(void *ptr);
//释放节点函数
void *(*free)(void *ptr);
//判断两个节点是否相等的函数
int (*match)(void *ptr,void *key);
//链表长度
unsigned long len;
}//定义链表节点的结构体
typedf struct listNode{
//前一个节点
struct listNode *prev;
//后一个节点
struct listNode *next;
//当前节点的值的指针
void *value;
}listNode;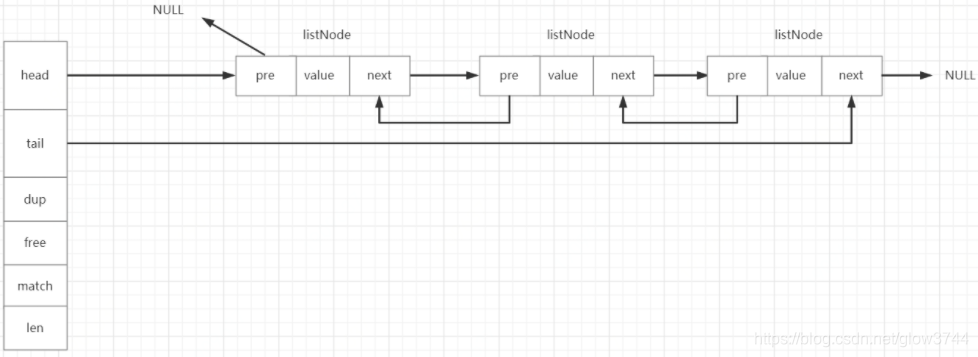
2、zipList
typedf struct ziplist<T>{
//压缩列表占用字符数
int32 zlbytes;
//最后一个元素距离起始位置的偏移量,用于快速定位最后一个节点
int32 zltail_offset;
//元素个数
int16 zllength;
//元素内容
T[] entries;
//结束位 0xFF
int8 zlend;
}ziplisttypede struct entry{
//前一个entry的长度
int<var> prelen;
//元素类型编码
int<var> encoding;
//元素内容
optional byte[] content;
}entry 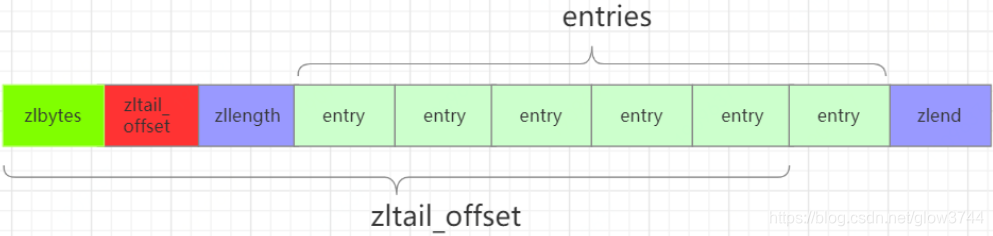
连锁更新
entry中有一个prelen字段,它的长度要么是1个字节,要么都是5个字节:
- 前一个节点的长度小于254个字节,则
prelen长度为1字节; - 前一个节点的长度大于254字节,则
prelen长度为5字节;
假设现在有一组压缩列表,长度都在250~253字节之间,突然新增一个entry节点,这个entry节点长度大于等于254字节。由于新的entry节点大于等于254字节,这个entry节点的prelen为5个字节,随后会导致其余的所有entry节点的prelen增大为5字节。

linkedList与zipList的对比
- 双向链表
linkedList便于在表的两端进行push和pop操作,在插入节点上复杂度很低,但是它的内存开销比较大。首先,它在每个节点上除了要保存数据之外,还有额外保存两个指针;其次,双向链表的各个节点都是单独的内存块,地址不连续,容易形成内存碎片。 zipList存储在一块连续的内存上,所以存储效率很高。但是它不利于修改操作,插入和删除操作需要频繁地申请和释放内存。特别是当zipList长度很长时,一次realloc可能会导致大量的数据拷贝。
- 当列表对象中元素的长度较小或者数量较少时,通常采用
zipList来存储;当列表中元素的长度较大或者数量比较多的时候,则会转而使用双向链表linkedList来存储。
3、quickList
在Redis3.2版本之后,list的底层实现方式又多了一种,quickList。qucikList是由zipList和双向链表linkedList组成的混合体。它将linkedList按段切分,每一段使用zipList来紧凑存储,多个zipList之间使用双向指针串接起来。示意图如下所示:
typedf struct quicklist{
//指向头结点
quicklistNode* head;
//指向尾节点
quicklistNode* tail;
//元素总数
long count;
//quicklistNode节点的个数
int nodes;
//压缩算法深度
int compressDepth;
...
}quickListtypedf struct quicklistNode{
//前一个节点
quicklistNode* prev;
//后一个节点
quicklistNode* next;
//压缩列表
ziplist* zl;
//ziplist大小
int32 size;
//ziplist 中元素数量
int16 count;
//编码形式 存储 ziplist 还是进行 LZF 压缩储存的zipList
int2 encoding;
...
}quickListNode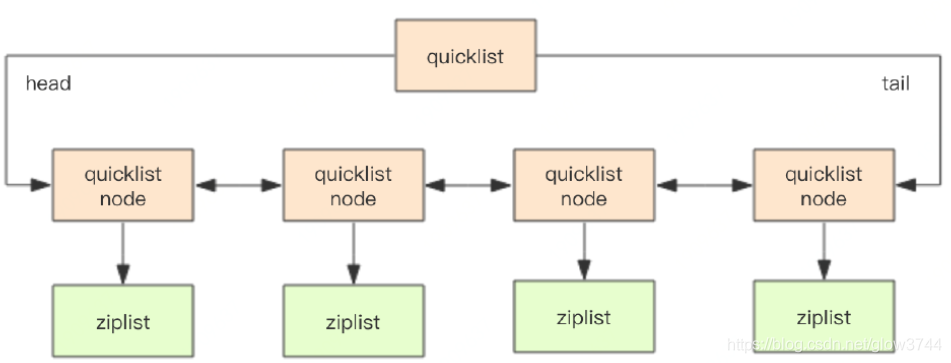
4、总结
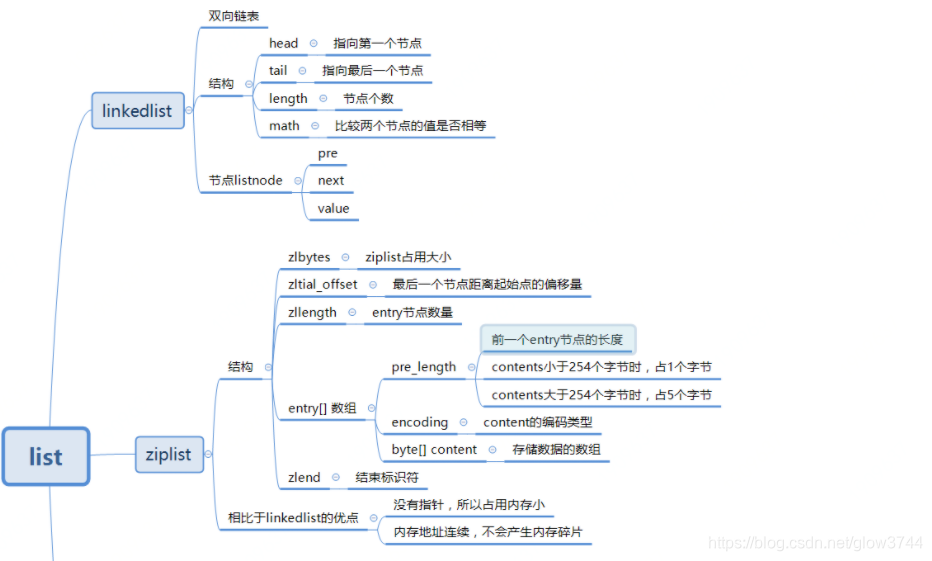

参考:Redis底层数据结构之list - Reecelin - 博客园
3、hash
1、zipList
前面已介绍
2、dict
typedf struct dict{
dictType *type;//类型特定函数,包括一些自定义函数,这些函数使得key和
//value能够存储
void *private;//私有数据
dictht ht[2];//两张hash表
int rehashidx;//rehash索引,字典没有进行rehash时,此值为-1
unsigned long iterators; //正在迭代的迭代器数量
}dict;typedf struct dictht{
dictEntry **table;//存储数据的数组 二维
unsigned long size;//数组的大小
unsigned long sizemask;//哈希表的大小的掩码,用于计算索引值,总是等于
//size-1
unsigned long used;//// 哈希表中中元素个数
}dictht;typedf struct dictEntry{
void *key;//键
union{
void val;
unit64_t u64;
int64_t s64;
double d;
}v;//值
struct dictEntry *next;//指向下一个节点的指针
}dictEntry;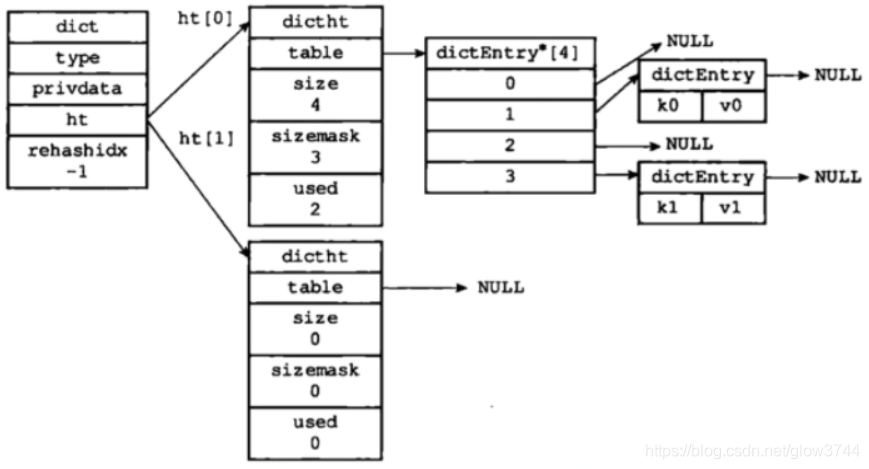
扩容与缩容
负载因子
哈希表中已保存节点数量/哈希表的大小(load factor = ht[0].used / ht[0].size)
触发规则
- 没有执行BGSAVE和BGREWRITEAOF指令的情况下,哈希表的负载因子大于等于1时进行扩容;
- 正在执行BGSAVE和BGREWRITEAOF指令的情况下,哈希表的负载因大于等于5时进行扩容;
- 负载因子小于0.1时,
Redis自动开始对哈希表进行收缩操作;
数量规则
- 扩容:扩容后的
dictEntry数组数量为第一个大于等于ht[0].used * 2的2^n; - 缩容:缩容后的
dictEntry数组数量为第一个大于等于ht[0].used的2^n;
渐进式rehash
- 假设当前数据在
dictht[0]中,那么按照扩容和缩容规则为dictht[1]分配足够的空间; - 设置rehashidx=0,表示
rehash正式开始; rehash进行期间,每次对字典执行添加、删除、查找或者更新操作时,程序除了执行指定的操作以外,还会顺带将dictht[0]哈希表在rehashidx索引上的所有键值对rehash到dictht[1],当一次rehash工作完成之后,程序将rehashidx属性的值+1。同时在serverCron中调用rehash相关函数,在1ms的时间内,进行rehash处理,每次仅处理少量的转移任务(100个元素);- 随着字典操作的不断执行,最终在某个时间点上,
dictht[0]的所有键值对都会被rehash至dictht[1],这时程序将rehashidx属性的值设为-1,表示rehash操作已完成。
某一时间段并没有任何请求命令应该怎么办?
Redis在有一个定时器,会定时去判断rehash是否完成,如果没有完成,则继续进行rehash。
在维护两个dictht的时候,此时哈希表如何正常对外提供服务?
对于添加操作,会将新的数据直接添加到dictht[1]上面,这样就可以保证dictht[0]上的数量只减少不增加。而对于删除、更改、查询操作,会直接在dictht[0]上进行,尤其是这三个操作,都会涉及到查询,当在dictht[0]上查询不到时,会接着去dictht[1]上查找,如果再找不到,则表明不存在该K-V值。
渐进式rehash的优缺点
优点:采用了分而治之的思想,将rehash 操作分散到每一个对该哈希表的操作上以及定时函数上,避免了集中式rehash 带来的性能压力;
缺点:在 rehash 的时间内,需要保存两个 hash 表,对内存的占用稍大,而且如果在 redis 服务器本来内存满了的时候,突然进行 rehash 会造成大量的 key 被抛弃。
3、总结
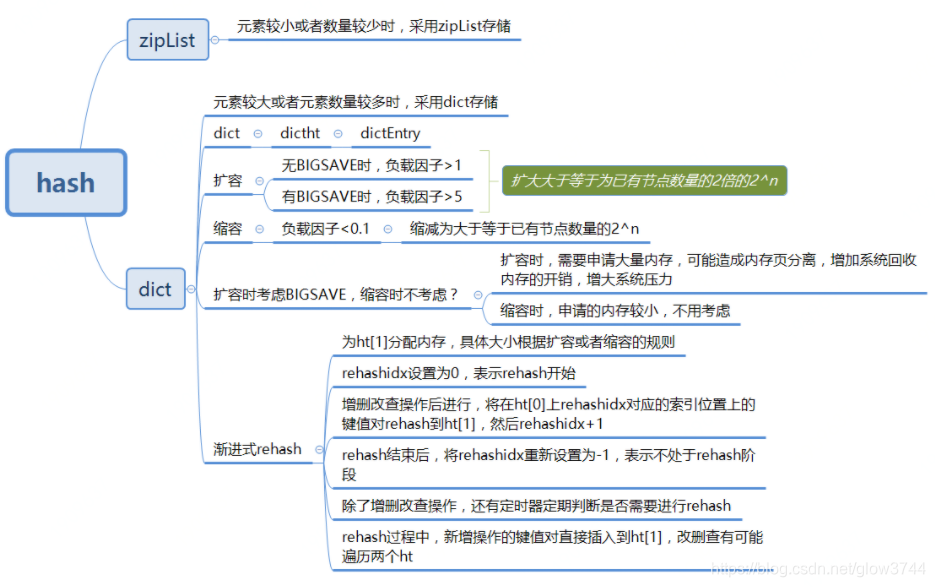
参考:Redis底层数据结构之hash - Reecelin - 博客园
4、zset
参考:https://segmentfault.com/a/1190000037473381?utm_source=tag-newest
二、Redis两种持久化机制RDB和AOF
1、RDB机制
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘。也是默认的持久化方式,这种方式是就是将内存中数据以快照的方式写入到二进制文件中,默认的文件名为dump.rdb。
三种触发方式
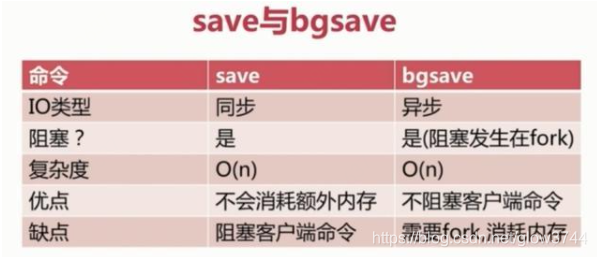
save触发方式
该命令会阻塞当前Redis服务器,执行save命令期间,Redis不能处理其他命令,直到RDB过程完成为止。具体流程如下:
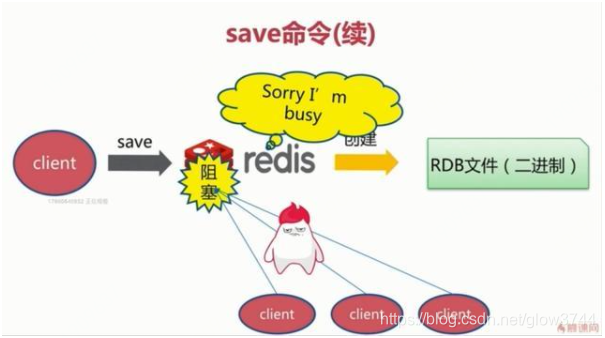
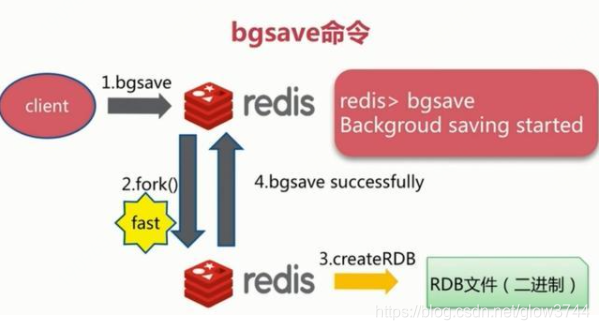
bgsave触发方式
执行该命令时,Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求。阻塞只发生在fork阶段,一般时间很短。具体流程如下:
自动触发方式
自动触发是由我们的配置文件来完成的。在redis.conf配置文件中,里面有如下配置,我们可以去设置:
save:这里是用来配置触发 Redis的 RDB 持久化条件,也就是什么时候将内存中的数据保存到硬盘。比如“save m n”。表示m秒内数据集存在n次修改时,自动触发bgsave。
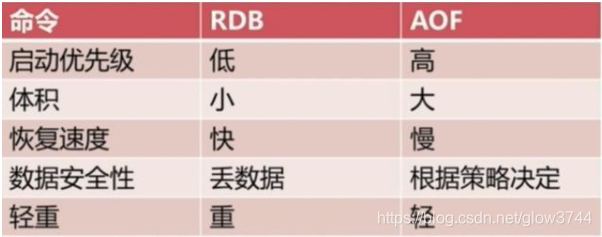
RDB的优势与劣势
优势
(1)RDB文件紧凑,全量备份,非常适合用于进行备份和灾难恢复。
(2)生成RDB文件的时候,redis主进程会fork()一个子进程来处理所有保存工作,主进程不需要进行任何磁盘IO操作。
(3)RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
劣势
当进行快照持久化时,会开启一个子进程专门负责快照持久化,子进程会拥有父进程的内存数据,父进程修改内存子进程不会反应出来,所以在快照持久化期间修改的数据不会被保存,可能丢失数据。
2、AOF机制
全量备份总是耗时的,有时候我们提供一种更加高效的方式AOF,工作机制很简单,redis会将每一个收到的写命令都通过write函数追加到文件中。通俗的理解就是日志记录。
持久化原理
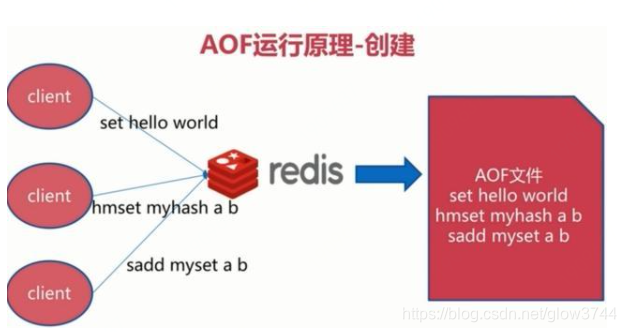
每当有一个写命令过来时,就直接保存在我们的AOF文件中。
文件重写原理
AOF的方式也同时带来了另一个问题。持久化文件会变的越来越大。为了压缩aof的持久化文件。redis提供了bgrewriteaof命令。将内存中的数据以命令的方式保存到临时文件中,同时会fork出一条新进程来将文件重写。
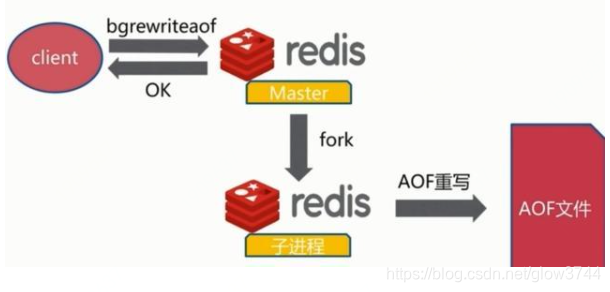
重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,这点和快照有点类似。
三种触发机制
(1)always每修改同步:同步持久化 每次发生数据变更会被立即记录到磁盘 性能较差但数据完整性比较好
(2)everysec每秒同步:异步操作,每秒记录 如果一秒内宕机,有数据丢失
(3)no不同:从不同步
AOF的优势与劣势
优势
(1)AOF可以更好的保护数据不丢失,一般AOF会每隔1秒,通过一个后台线程执行一次fsync操作,最多丢失1秒钟的数据。
(2)AOF日志文件没有任何磁盘寻址的开销,写入性能非常高,文件不容易破损。
(3)AOF日志文件的命令通过非常可读的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复。比如某人不小心用flushall命令清空了所有数据,只要这个时候后台rewrite还没有发生,那么就可以立即拷贝AOF文件,将最后一条flushall命令给删了,然后再将该AOF文件放回去,就可以通过恢复机制,自动恢复所有数据
劣势
(1)对于同一份数据来说,AOF日志文件通常比RDB数据快照文件更大
(2)AOF开启后,支持的写QPS会比RDB支持的写QPS低,因为AOF一般会配置成每秒fsync一次日志文件,当然,每秒一次fsync,性能也还是很高的
(3)以前AOF发生过bug,就是通过AOF记录的日志,进行数据恢复的时候,没有恢复一模一样的数据出来。
3、总结
参考:百度安全验证
三、Redis过期删除策略和内存淘汰策略
1、过期时间判定
在Redis内部,每当我们设置一个键的过期时间时,Redis就会将该键带上过期时间存放到一个过期字典中。当我们查询一个键时,Redis便首先检查该键是否存在过期字典中,如果存在,那就获取其过期时间。然后将过期时间和当前系统时间进行比对,比系统时间大,那就没有过期;反之判定该键过期。
2、过期删除策略
惰性删除
设置该key 过期时间后,我们不去管它,当需要该key时,我们在检查其是否过期,如果过期,我们就删掉它,反之返回该key。
定期删除
每隔一段时间,都从一定数量的数据库中取出一定数量的随机键进行检查,并删除其中的过期键。
注意:并不是一次运行就检查所有的库,所有的键,而是随机检查一定数量的键。
定期删除函数的运行频率,在Redis2.6版本中,规定每秒运行10次,大概100ms运行一次。在Redis2.8版本后,可以通过修改配置文件redis.conf 的 hz 选项来调整这个次数。
3、内存淘汰策略
当现有内存大于 maxmemory 时,便会触发redis主动淘汰内存方式,通过设置 maxmemory-policy ,有如下几种淘汰方式:
1)volatile-lru 利用LRU算法移除设置过过期时间的key (LRU:最近使用 Least Recently Used ) 。
2)allkeys-lru 利用LRU算法移除任何key (和上一个相比,删除的key包括设置过期时间和不设置过期时间的)。通常使用该方式。
3)volatile-random 移除设置过过期时间的随机key 。
4)allkeys-random 无差别的随机移除。
5)volatile-ttl 移除即将过期的key(minor TTL)
6)noeviction 不移除任何key,只是返回一个写错误 ,默认选项,一般不会选用。
4、总结
Redis过期删除策略是采用惰性删除和定期删除这两种方式组合进行的,惰性删除能够保证过期的数据我们在获取时一定获取不到,而定期删除设置合适的频率,则可以保证无效的数据及时得到释放,而不会一直占用内存数据。
但是我们说Redis是部署在物理机上的,内存不可能无限扩充的,当内存达到我们设定的界限后,便自动触发Redis内存淘汰策略,而具体的策略方式要根据实际业务情况进行选取。
参考:Redis详解(十一)------ 过期删除策略和内存淘汰策略 - YSOcean - 博客园
四、Redis三种集群模式
1、主从复制
2、哨兵模式
3、Cluster集群
参考:Redis ==> 集群的三种模式 - 破解孤独 - 博客园
五、Redis分布式锁应用场景
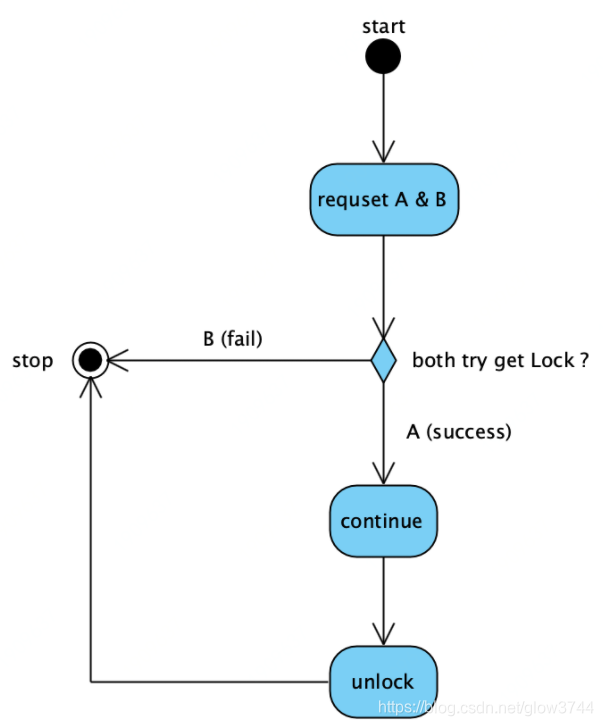
1、抢不到锁的请求,允许丢弃
比如:一些不是很重要的场景,比如“监控数据持续上报”,某一篇文章的“已读/未读”标识位更新,对于同一个id,如果并发的请求同时到达,只要有一个请求处理成功,就算成功。
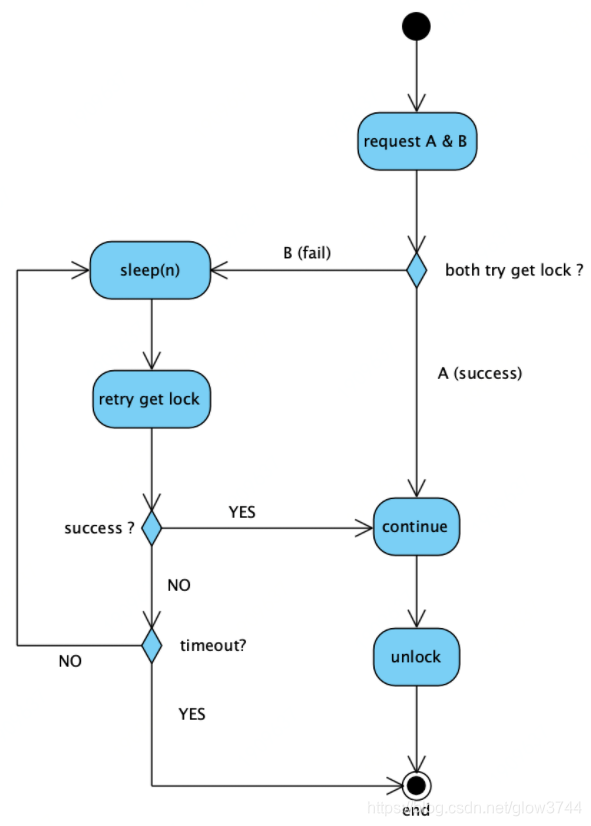
2、并发请求,不论哪一条都必须要处理的场景
比如:一个订单,客户正在前台修改地址,管理员在后台同时修改备注。地址和备注字段的修改,都必须正确更新。
解决思路:A,B二个请求,谁先抢到分布式锁谁先处理(A),抢不到的(B)在一旁不停等待重试,重试期间一旦发现B获取锁成功,即表示A已经处理完,把锁释放了。
但有二点要注意:
a、设置重试次数或设置重试超时时间。否则如果A处理过程中有bug,一直卡死,或者未能正确释放锁,B就会一直会等待重试,但是又永远拿不到锁。
b、等待最长时间,必须小于锁的过期时间。否则,假设锁2秒过期自动释放,但是A还没处理完(即:A的处理时间大于2秒),这时锁会因为redis key过期“提前”误释放,B重试时拿到锁,造成A,B同时处理。
参考:基于redis的分布式锁二种应用场景 - 菩提树下的杨过 - 博客园
六、进程内缓存
1、与进程外缓存相比
- 节省内存带宽
- 响应时延降低
2、进程内缓存缺点
- 数据存了多份,一致性比较难保障
3、进程缓存如何保证数据一致性
- 单节点通知其他节点。缺点:多个节点相互耦合
- 通过MQ通知其他节点。缺点:引入了MQ,使得系统更复杂
- 每个节点启动一个timer,定时从后端拉取最新数据,更新内存缓存。缺点:放弃了“实时一致性”
4、为什么不能频繁使用进程内缓存
答:分层架构设计,有一条准则:站点层、服务层要做到无数据无状态,这样才能任意的加节点水平扩展,数据和状态尽量存储到后端的数据存储服务,例如数据库服务或者缓存服务。
可以看到,站点与服务的进程内缓存,实际上违背了分层架构设计的无状态准则,故一般不推荐使用。
5、什么时候可以使用进程内缓存
- 只读数据
- 极其高并发的,如果透传后端压力极大的场景
- 允许数据不一致业务
参考:进程内缓存,究竟怎么玩?
七、选redis还是memcache
1、什么情况倾向于选择redis
复杂数据结构:memcache仅支持KV结构
持久化:memcache无法满足持久化需求
天然高可用:而memcache,要想要实现高可用,需要进行二次开发,例如客户端的双读双写,或者服务端的集群同步。
存储内容比较大:memcache的value存储,最大为1M
2、什么情况倾向于选择memcatche
纯KV,数据量非常大,并发量非常大的业务,使用memcache或许更适合。
内存分配
memcache使用预分配内存池的方式管理内存,能够省去内存分配时间。
redis则是临时申请空间,可能导致碎片。
从这一点上,mc会更快一些。
虚拟内存使用
memcache把所有的数据存储在物理内存里。
redis有自己的VM机制,理论上能够存储比物理内存更多的数据,当数据超量时,会引发swap,把冷数据刷到磁盘上。
从这一点上,数据量大时,mc会更快一些。
网络模型
memcache使用非阻塞IO复用模型,redis也是使用非阻塞IO复用模型。
但由于redis还提供一些非KV存储之外的排序,聚合功能,在执行这些功能时,复杂的CPU计算,会阻塞整个IO调度。
从这一点上,由于redis提供的功能较多,mc会更快一些。
线程模型
memcache使用多线程,主线程监听,worker子线程接受请求,执行读写,这个过程中,可能存在锁冲突。
redis使用单线程,虽无锁冲突,但难以利用多核的特性提升整体吞吐量。
从这一点上,mc会快一些。
八、缓存,你真的用对了么?
误用一:把缓存作为服务与服务之间的传递数据的媒介
存在问题:1、MQ更合适,2、服务耦合
误用二:使用缓存未考虑雪崩
存在问题:缓存挂掉,可能会把数据库压垮
解决方案:1、高可用缓存,2、缓存水平切分
误用三:调用方缓存数据
存在问题:数据不一致
误用四:多服务公用缓存实例
存在问题:1、不同服务吞吐量不一样,容易导致一个服务把另一个服务的热数据挤出去,2、服务耦合
参考:缓存,你真的用对了么?
九、缓存,究竟是淘汰,还是修改?
1、淘汰和修改缓存区别
- 淘汰某个key,操作简单,直接将key置为无效,但下一次该key的访问会cache miss
- 修改某个key的内容,逻辑相对复杂,但下一次该key的访问仍会cache hit
2、结论
- 大部分情况,修改value成本会高于“增加一次cache miss”,因此应该淘汰缓存
- 如果还在纠结,总是淘汰缓存,问题也不大
十、Cache Aside Pattern
1、介绍
旁路缓存方案的经验实践,这个实践又分为读实践,写实践。
对于读请求
- 先读cache,再读db
- 如果,cache hit,则直接返回数据
- 如果,cache miss,则访问db,并将数据set回缓存
对于写请求
- 淘汰缓存,而不是更新缓存
- 先操作数据库,再淘汰缓存
2、原因
Cache Aside Pattern为什么建议淘汰缓存,而不是更新缓存?
如果更新缓存,在并发写时,可能出现数据不一致
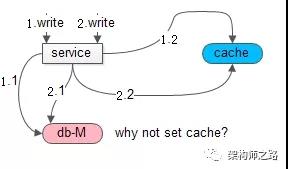
- 请求1先操作数据库,请求2后操作数据库
- 请求2先set了缓存,请求1后set了缓存
Cache Aside Pattern为什么建议先操作数据库,再操作缓存?
如果先操作缓存,数据不一致的时间窗口不可控
- 线程A淘汰缓存
- 线程B读缓存(cache miss)
- 线程B读库
- 线程B设置缓存
- 线程A写库
3、问题
如果先操作数据库,再淘汰缓存,在原子性被破坏时
- 修改数据库成功了
- 淘汰缓存失败了
导致,数据库与缓存的数据不一致。
4、扩展
原子性被破坏情况下,先操作缓存,再操作数据库,不会导致数据不一致(但并发条件下会)。
先删除缓存,后更新数据库,以下情况会出现数据库不一致
1、线程A淘汰缓存、线程B读缓存、线程B读库、线程B设置缓存、线程A更新库。(概率大)
先更新数据库,后删除缓存,以下情况会出现数据库不一致
1、线程A更新库成功,删除缓存失败;(概率小)
2、线程A更新库,线程A删除缓存,线程B读缓存、线程B读库、线程C更新库,线程C删除缓存、线程B设置缓存(概率小,需要对同一数据进行两次更新)
十一、数据库主从不一致
方案一:忽略
如果业务能接受,最推崇此法,别把系统架构搞得太复杂。
方案二:强制读主
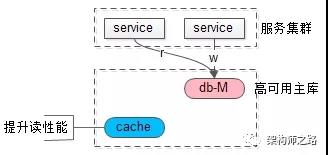
- 使用一个高可用主库提供数据库服务
- 读和写都落到主库上
- 采用缓存来提升系统读性能
方案三:选择性读主
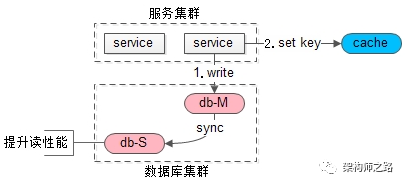
当写请求发生时
- 写主库
- 将哪个库,哪个表,哪个主键三个信息拼装一个key设置到cache里,这条记录的超时时间,设置为“主从同步时延”
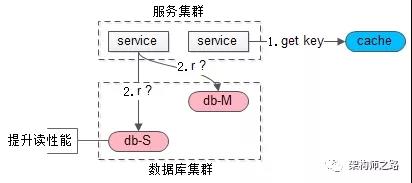
当读请求发生时
- cache里有这个key,说明1s内刚发生过写请求,数据库主从同步可能还没有完成,此时就应该去主库查询
- cache里没有这个key,说明最近没有发生过写请求,此时就可以去从库查询
十二、redis实现分布式事务
1、使用setnx命令获取分布式锁
2、为了防止获取分布式锁后服务挂掉导致锁一直无法释放,故设置超时时间n(必须和setnx实现原子操作,redisTemplate中存在该方法)
3、为了解决程序执行时间大于超时时间,在获取到分布式锁后,起一个线程,每隔n/3秒查询下锁是否还存在,存在则超时时间为n
4、redisson封装实现了上述逻辑
十三、redis数据结构的应用
1、string
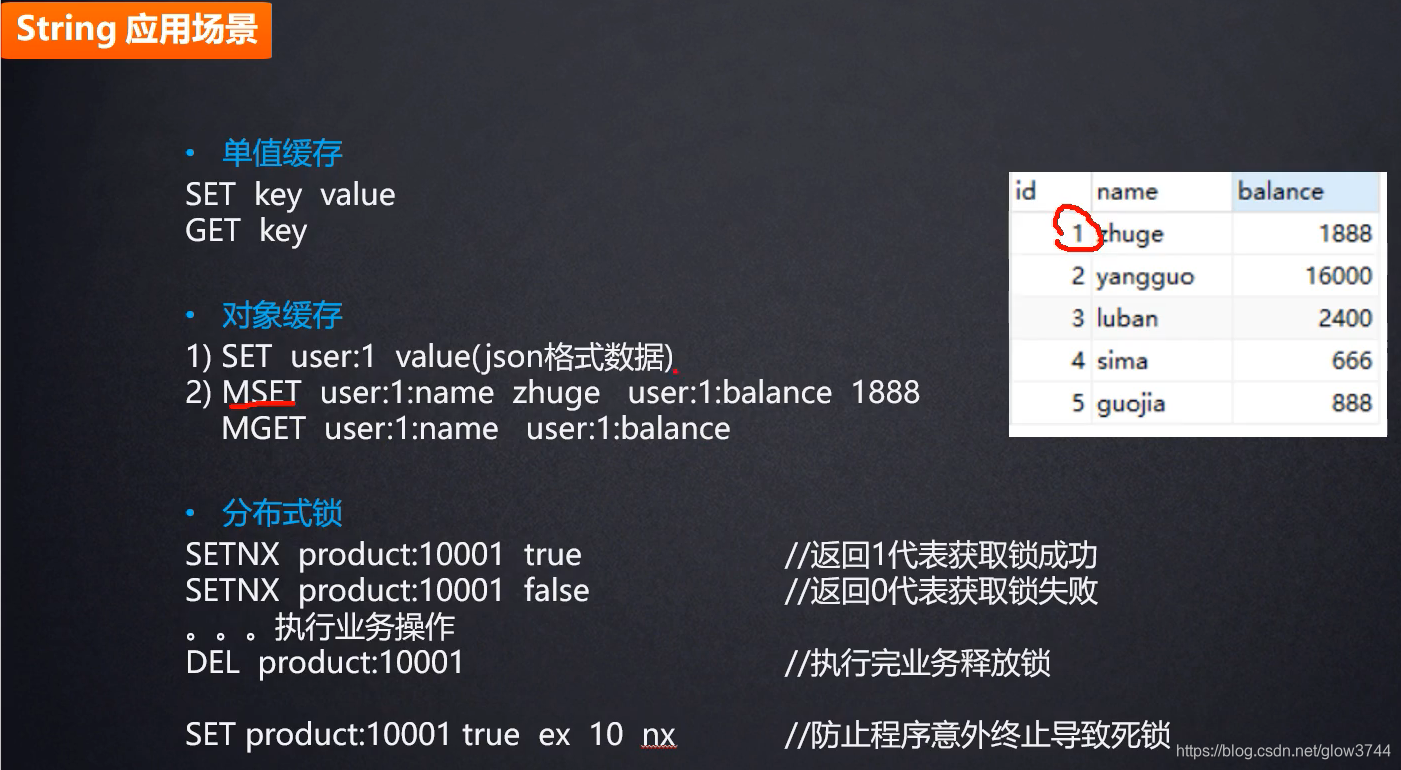
2、hash
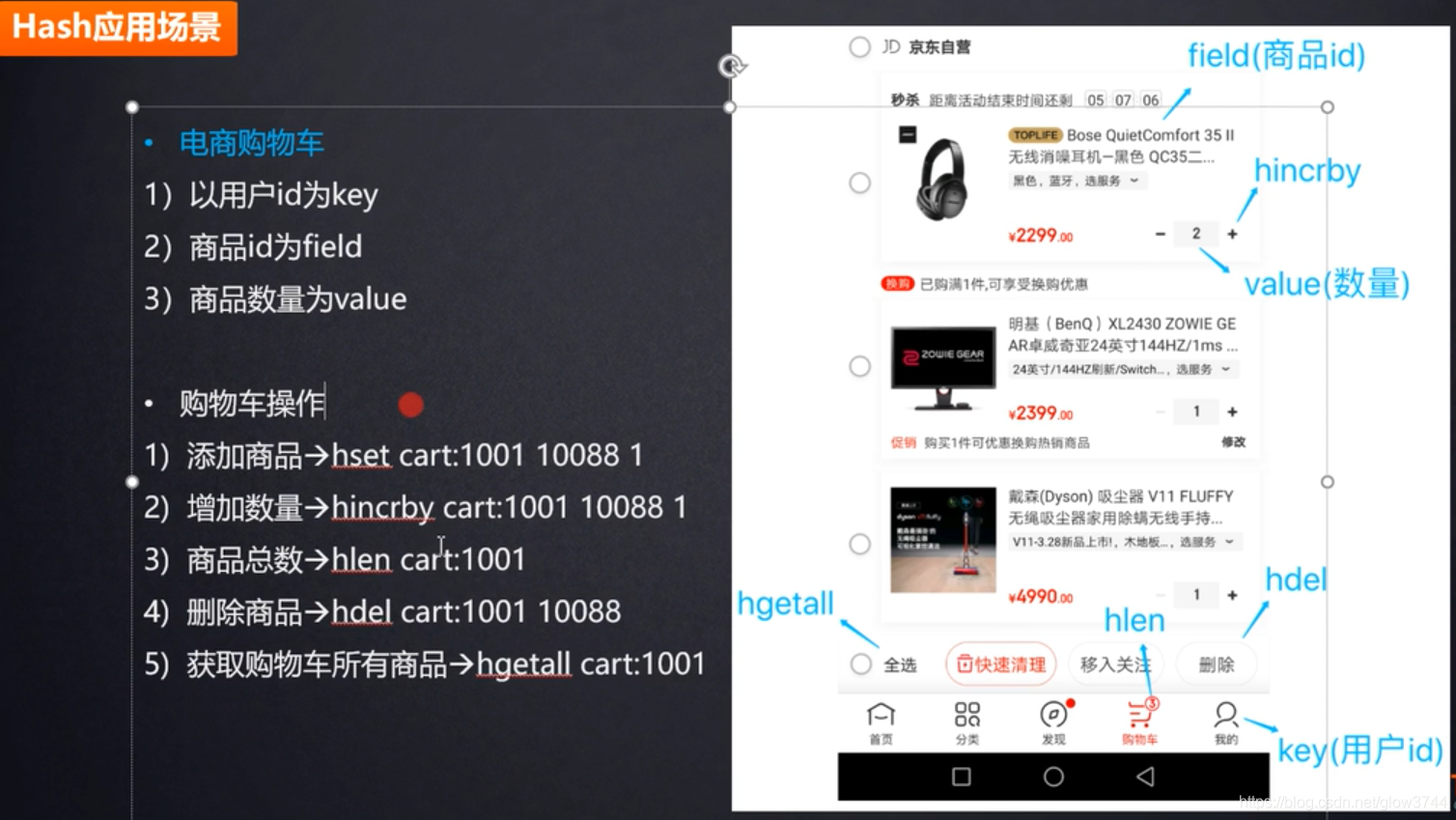

















 2086
2086



 到【灌水乐园】发言
到【灌水乐园】发言








