



5 分钟吃透图像特征提取!内核 / 网络层 / 池化 / 块全拆解
一、引言
本文聚焦图像特征提取核心技术,先解析核函数(含手工与可学习类型)在彩色图像上的应用及代码实现;再以VGG19为例,对比从零训练与预训练模型的特征图差异,揭示不同网络层的特征提取规律;还介绍了池化的三种类型及作用,以及VGG风格“块”结构的设计逻辑,文章辅以关键代码与可视化参考,为计算机视觉学习者提供实用思路。
二、关键技术与核心内容
1.核(Kernel)
- 核心公式 :
* 基础版:图像 * 核 = 特征(可手工设计内核提取模糊、底部sobel、浮雕、恒等(identity)等特定特征)
* 进阶版:图像 * 核 + 偏置(bias)= 特征(将内核设为可学习参数,实现特征自动提取) - 彩色图像处理 :先分离红(R)、绿(G)、蓝(B)三通道,每个通道分别与内核运算后,再合并通道得到最终结果
- 示例内核矩阵 :
* 浮雕(emboss):[[-2, -1, 0], [-1, 1, 1], [0, 1, 2]]
* 恒等(identity):[[0, 0, 0], [0, 1, 0], [0, 0, 0]](保留原始图像)
* 左sobel(left_sobel):[[1, 0, -1], [2, 0, -2], [1, 0, -1]] - 核心代码片段 :
image_extraction(单通道图像与内核运算)和apply_filter_color(彩色图像多通道处理与合并)函数如下。
emboss = [[-2, -1, 0],
[-1, 1, 1],
[ 0, 1, 2]]
identity = [[0, 0, 0],
[0, 1, 0],
[0, 0, 0]]
left_sobel = [[1, 0, -1],
[2, 0, -2],
[1, 0, -1]]
def image_extraction(image, kernel):
for i in range(image.shape[0]-kernel.shape[0]+1):
for j in range(image.shape[1]-kernel.shape[1]+1):
image[i,j] = np.sum(image[i:i+kernel.shape[0], j:j+kernel.shape[1]]*kernel)
return image
def apply_filter_color(image, kernel):
r, g, b = image[:,:,0], image[:,:,1], image[:,:,2]
r_filtered = image_extraction(r, kernel)
g_filtered = image_extraction(g, kernel)
b_filtered = image_extraction(b, kernel)
# Merge the channels back together
filtered_image = np.stack([r_filtered, g_filtered, b_filtered], axis=-1)
return filtered_image
 在这里插入图片描述
在这里插入图片描述
2. 网络层(Layers)
-
作用 :单次特征提取不足以满足需求,需通过多层重复运算逼近最终输出,从RGB三通道提取更多特征通道
-
VGG19架构实验 :
* 实验设置:2种训练方式(从零训练、预训练),仅训练5个epoch,可视化每层16个通道特征图
* 实验结果:
| 训练方式 | 第5轮损失(Loss) | 第5轮准确率(Acc) | 特征图差异 |
|---|---|---|---|
| 从零训练 | 0.6862 | 55.02% | 第1卷积层与预训练差异不明显;第16卷积层(深层)特征图更模糊、含噪声,无明显模式 |
| 预训练 | 0.0285 | 99.04% | 第16卷积层(深层)出现抽象模式,特征更清晰 |
特征图可视化
在这里,我只可视化了每个卷积层的 16 个通道。 从零开始训练精度: Epoch 1/5 损失:0.6928 累积:51.42% Epoch 2/5 损失:0.6909 累积:53.13% Epoch 3/5 损失:0.6887 累积:53.74% Epoch 4/5 损失:0.6866 累积:54.98% Epoch 5/5 损失:0.6862 累积:55.02%
以下是 VGG 19 从头开始训练 的示例特征图:
 img
img
来自 epoch 1 的卷积层 1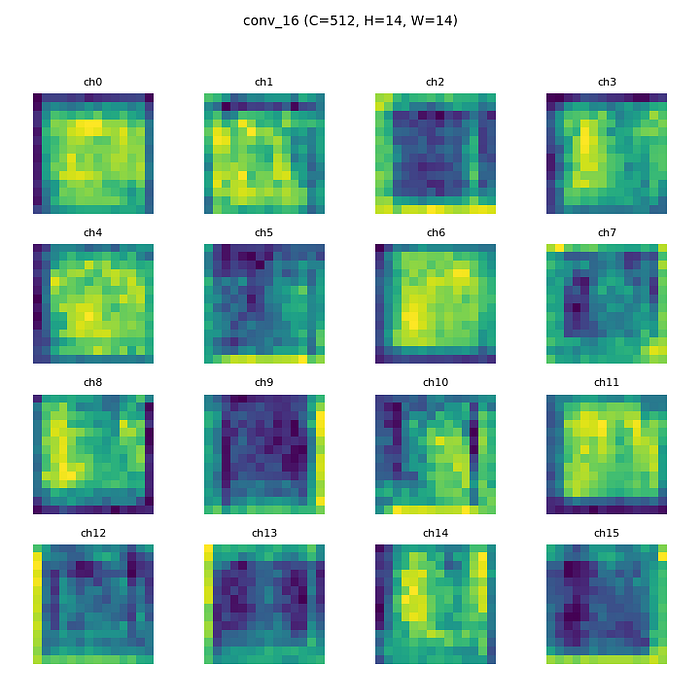
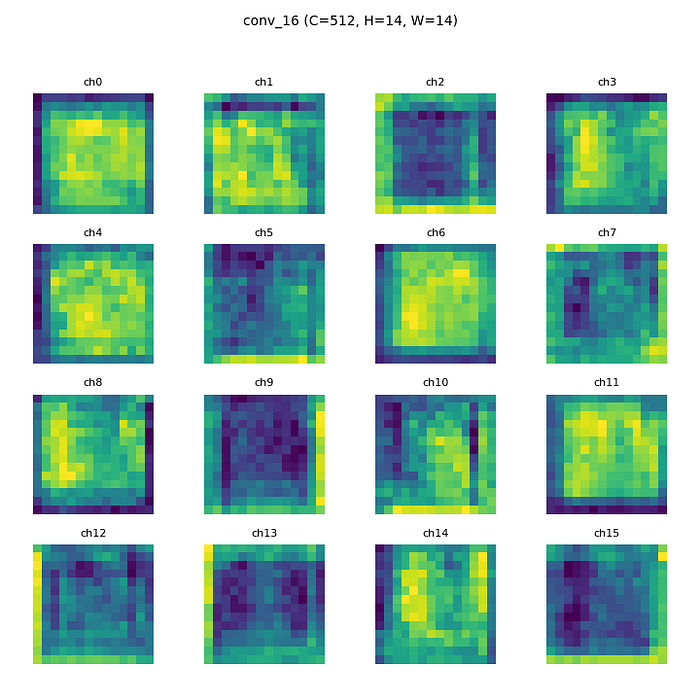
来自 epoch 1 的卷积层 16
img
来自 epoch 5 的卷积层 1
 img
img
来自 epoch 5 的卷积层 16
另一个是使用 pretrained预训练模型的情况。以下是训练精度: Epoch 1/5 损失:0.1055 累积:96.84% Epoch 2/5 损失:0.0394 累积:98.71% Epoch 3/5 损失:0.0345 累积:98.78% Epoch 4/5 损失:0.0305 累积:98.88% Epoch 5/5 损失:0.0285 累积:99.04%
以下是 VGG 19 预训练 的示例特征图:
 img
img
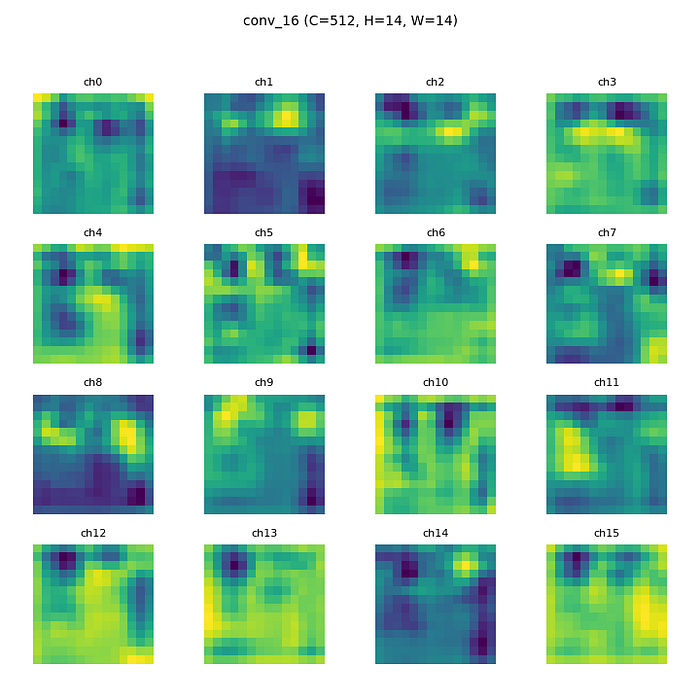
来自epoch 1 的卷积层 1
 img
img
来自epoch 1 的卷积层 16
img
来自epoch 5 的卷积层 1
img
来自epoch 5 的卷积层 16
从人眼的角度来看,从头开始训练和预训练之间的特征图差异在第一个卷积层中并不明显。但是在最后一个卷积层(卷积层16)上,差异是明显的。尽管它仍然有点难以分析,但更抽象的模式出现在每个频道上。从头开始的模型特征图更加模糊和嘈杂。
- 特征提取规律 :
* 早期层:捕捉边缘、角落、色块等通用特征
* 中间层:将早期特征组合为复杂形状、纹理(如眼睛、耳朵、毛发图案)
* 深层:提取与任务直接相关的高级特征(如猫狗分类任务中的“猫脸”“狗耳朵”)
3. 池化(Pooling)
- 作用 :从特定区域提取特定值,通常在卷积层后应用(部分架构在“块”后应用)
- 主要类型 :
* 最大池化(max pool):提取对应像素中的最大值,保留最亮区域
* 最小池化(min pool):提取对应像素中的最小值,保留最暗区域
* 平均池化(avg pool):计算对应像素的平均值,结果偏模糊 以下是不同池化类型的图片效果:
- 核心代码片段 :提供
apply_pooling函数,支持3种池化类型与4种内核尺寸(2×2、4×4、8×8、16×16),并包含可视化代码。
# Define pooling operations
def apply_pooling(img, pool_type, kernel_size):
if pool_type == ‘max’:
pool = nn.MaxPool2d(kernel_size, stride=kernel_size)
return pool(img)
elif pool_type == ‘avg’:
pool = nn.AvgPool2d(kernel_size, stride=kernel_size)
return pool(img)
elif pool_type == ‘min’:
pool = nn.MaxPool2d(kernel_size, stride=kernel_size)
return -pool(-img)
# Pooling configurations
pool_types = ['max', 'avg', 'min']
kernel_sizes = [2, 4, 8, 16]
# Visualize results
plt.figure(figsize=(15, 10))
plt.suptitle("Pooling Operations Comparison (Grayscale Saitama)", y=1.05, fontsize=16)
for i, pool_type in enumerate(pool_types):
for j, ksize in enumerate(kernel_sizes):
pooled_img = apply_pooling(img_tensor, pool_type, ksize)
# Convert to numpy and normalize for display
pooled_img = pooled_img.squeeze().numpy()
pooled_img = (pooled_img - pooled_img.min()) / (pooled_img.max() - pooled_img.min())
ax = plt.subplot(len(pool_types), len(kernel_sizes), i*len(kernel_sizes) + j + 1)
ax.imshow(pooled_img, cmap='gray')
ax.set_title(f"{pool_type.capitalize()} Pool\nKernel={ksize}x{ksize}")
ax.axis('off')
4. 块(Block)
 如上图,VGG16 架构中有 5 个块。每个区块由 2 到 3 个卷积层和 1 个池化层组成。
如上图,VGG16 架构中有 5 个块。每个区块由 2 到 3 个卷积层和 1 个池化层组成。
- 结构设计 :受VGG网络启发,每个块包含2-3个卷积层+1个池化层(非每个卷积层后都加池化)
- 核心优势 :在池化降低分辨率前,通过多层卷积提取更丰富的特征,避免分辨率降低导致的特征损失
- VGG16架构示例 :包含5个块,每个块由2-3个卷积层和1个池化层组成
总结
本文围绕图像特征提取展开,介绍了四大核心技术:一是内核,含手工设计(如浮雕、恒等)与可学习类型,还给出彩色图像多通道处理代码;二是网络层,以 VGG19 为例,对比从零训练与预训练模型,指出早期层提通用特征、深层提任务相关高级特征;三是池化,详解最大、最小、平均三种类型及不同内核尺寸效果;四是块结构,介绍 VGG 风格 “2-3 个卷积层 + 1 个池化层” 设计,以保留特征丰富度。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











